
NSFW指的是 不适宜工作场所("Not Safe (or Suitable) For Work;")。在本文中,将介绍如何创建一个检测NSFW图像的图像分类模型。

数据集
由于数据集的性质,我们无法从一些数据集的网站(如Kaggle等)获得所有图像。
但是我们找到了一个专门抓取这种类型图片的github库,所以我们可以直接使用。clone项目后可以运行下面的代码来创建文件夹,并将每个图像下载到其特定的文件夹中。
folders = ['drawings','hentai','neutral','porn','sexy']
urls = ['urls_drawings.txt','urls_hentai.txt','urls_neutral.txt','urls_porn.txt','urls_sexy.txt']
names = ['d','h','n','p','s']
for i,j,k in zip(folders,urls,names):
try:
#Specify the path of the folder that has to be made
folder_path = os.path.join('your directory',i)
os.mkdir(folder_path)
except:
pass
#setup the path of url text file
url_path = os.path.join('Datasets_Urls',j)
my_file = open(url_path, "r")
data = my_file.read()
#create a list with all urls
data_into_list = data.split("\n")
my_file.close()
icount = 0
for ii in data_into_list:
try:
#create a unique image names for each images
image_name = 'image'+str(icount)+str(k)+'.png'
image_path = os.path.join(folder_path,image_name)
#download it using the library
urllib.request.urlretrieve(ii, image_path)
icount+=1
except Exception as e:
pass
#this below code is done to make the count of the image same for all the data
#you can use a big number if you are building a more complex model or if you have a good system
if icount == 2000:
break
这里的folder变量表示类的名称,urls变量用于获取URL文本文件(可以根据文本文件名更改它),name变量用于为每个图像创建唯一的名称。
上面代码将为每个类下载2000张图像,可以编辑最后一个“if”条件来更改下载图像的个数。
数据准备
我们下载的文件夹可能包含其他类型的文件,所以首先必须删除不需要的类型的文件。
image_exts = ['jpeg','.jpg','bmp','png']
path_list = ['drawings','hentai','neutral','porn','sexy']
cwd = os.getcwd()
def remove_other_images(path_list):
for ii in path_list:
data_dir = os.path.join(cwd,'DataSet',ii)
for image in os.listdir(os.path.join(data_dir)):
image_path = os.path.join(data_dir,image_class,image)
try:
img = cv2.imread(image_path)
tip = imghdr.what(image_path)
if tip not in image_exts:
print('Image not in ext list {}'.format(image_path))
os.remove(image_path)
except Exception as e:
print("Issue with image {}".format(image_path))
remove_other_images(path_list)
上面的代码删除了扩展名不是指定格式的图像。
另外图像可能包含许多重复的图像,所以我们必须从每个文件夹中删除重复的图像。
cwd = os.getcwd()
path_list = ['drawings','hentai','neutral','porn','sexy']
def remove_dup_images(path_list):
for ii in path_list:
os.chdir(os.path.join(cwd,'DataSet',ii))
filelist = os.listdir()
duplicates = []
hash_keys = dict()
for index, filename in enumerate(filelist):
if os.path.isfile(filename):
with open(filename,'rb') as f:
filehash = hashlib.md5(f.read()).hexdigest()
if filehash not in hash_keys:
hash_keys[filehash] = index
else:
duplicates.append((index,hash_keys[filehash]))
for index in duplicates:
os.remove(filelist[index[0]])
print('{} duplicates removed from {}'.format(len(duplicates),ii))
remove_dup_images(path_list)
这里我们使用hashlib.md5编码来查找每个类中的重复图像。
Md5为每个图像创建一个唯一的哈希值,如果哈希值重复(重复图像),那么我们将重复图片添加到一个列表中,稍后进行删除。
因为使用TensorFlow框架所以需要判断是否被TensorFlow支持,所以我们这里加一个判断:
import tensorflow as tf
os.chdir('{data-set} directory')
cwd = os.getcwd()
for ii in path_list:
os.chdir(os.path.join(cwd,ii))
filelist = os.listdir()
for image_file in filelist:
with open(image_file, 'rb') as f:
image_data = f.read()
# Check the file format
_, ext = os.path.splitext(image_file)
if ext.lower() not in ['.jpg', '.jpeg', '.png', '.gif', '.bmp']:
print('Unsupported image format:', ext)
os.remove(os.path.join(cwd,ii,image_file))
else:
# Decode the image
try:
image = tf.image.decode_image(image_data)
except:
print(image_file)
print("unspported")
os.remove(os.path.join(cwd,ii,image_file))
以上就是数据准备的所有工作,在清理完数据后,我们可以拆分数据。比如分割创建一个训练、验证和测试文件夹,并手动添加文件夹中的图像,我们将80%用于训练,10%用于验证,10%用于测试。
模型
首先导入tensorflow
import tensorflow as tf
import os
import numpy as np
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
import hashlib
from imageio import imread
import numpy as np
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.applications.vgg16 import preprocess_input
from tensorflow.keras.layers import Flatten,Dense,Input
from tensorflow.keras.models import Model,Sequential
from keras import optimizers
对于图像,默认大小设置为224,224。
IMAGE_SIZE = [224,224]
可以使用ImageDataGenerator库,进行数据增强。数据增强也叫数据扩充,是为了增加数据集的大小。ImageDataGenerator根据给定的参数创建新图像,并将其用于训练(注意:当使用ImageDataGenerator时,原始数据将不用于训练)。
train_datagen = ImageDataGenerator(
rescale=1./255,
preprocessing_function=preprocess_input,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')
对于测试集也是这样:
test_datagen = ImageDataGenerator(rescale=1./255)
为了演示,我们直接使用VGG模型
vgg = VGG16(input_shape=IMAGE_SIZE+[3],weights='imagenet',include_top=False
然后冻结前面的层:
for layer in vgg.layers:
layer.trainable = False
最后我们加入自己的分类头:
x = Flatten()(vgg.output)
prediction = Dense(5,activation='softmax')(x)
model = Model(inputs=vgg.input, outputs=prediction)
model.summary()
模型是这样的:

训练
看看我们训练集:
train_set = train_datagen.flow_from_directory('DataSet/train',
target_size=(224,224),
batch_size=32,
class_mode='sparse')
验证集
val_set = train_datagen.flow_from_directory('DataSet/validation',
target_size=(224,224),
batch_size=32,
class_mode='sparse')

使用' sparse_categorical_crossentropy '损失,这样可以将标签编码为整数而不是独热编码。
from tensorflow.keras.metrics import MeanSquaredError
from tensorflow.keras.metrics import CategoricalAccuracy
adam = optimizers.Adam()
model.compile(loss='sparse_categorical_crossentropy',
optimizer=adam,
metrics=['accuracy',MeanSquaredError(name='val_loss'),CategoricalAccuracy(name='val_accuracy')])
然后就可以训练了:
from datetime import datetime
from keras.callbacks import ModelCheckpoint
log_dir = 'vg_log'
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir = log_dir)
start = datetime.now()
history = model.fit_generator(train_set,
validation_data=val_set,
epochs=100,
steps_per_epoch=len(train_set)// batch_size,
validation_steps=len(val_set)//batch_size,
callbacks=[tensorboard_callback],
verbose=1)
duration = datetime.now() - start
print("Time taken for training is ",duration)
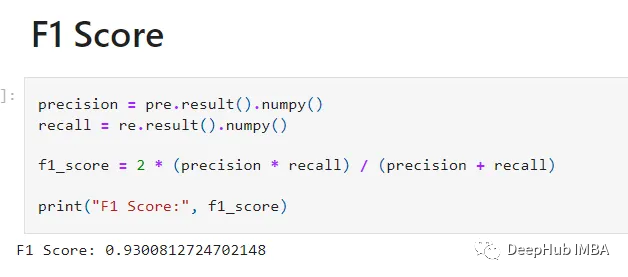
模型训练了100次。得到了80%的验证准确率。f1得分为93%
预测
下面的函数将获取一个图像列表并根据该列表进行预测。
import numpy as np
import matplotlib.image as mpimg
import matplotlib.pyplot as plt
from scipy.ndimage import gaussian_filter
def print_classes(images,model):
classes = ['Drawing','Hentai','Neutral','Porn','Sexual']
fig, ax = plt.subplots(ncols=len(images), figsize=(20,20))
for idx,img in enumerate(images):
img = mpimg.imread(img)
resize = tf.image.resize(img,(224,224))
result = model.predict(np.expand_dims(resize/255,0))
result = np.argmax(result)
if classes[result] == 'Porn':
img = gaussian_filter(img, sigma=6)
elif classes[result] == 'Sexual':
img = gaussian_filter(img, sigma=6)
elif classes[result] == 'Hentai':
img = gaussian_filter(img, sigma=6)
ax[idx].imshow(img)
ax[idx].title.set_text(classes[result])
li = ['test1.jpeg','test2.jpeg','test3.jpeg','test4.jpeg','test5.jpeg']
print_classes(li,model)
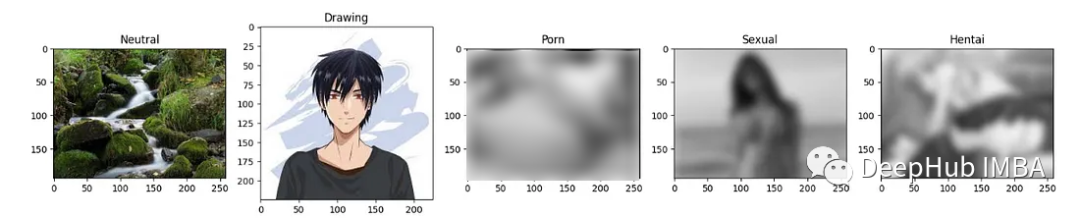
看结果还是可以的。
最后,本文的源代码:
https://github.com/Nikhilthalappalli/NSFW-Classifier
但是我觉得源代码不重要,Alex Kim的项目才是你需要的:
https://github.com/alex000kim/nsfw_data_scraper
作者:Nikhil Thalappalli