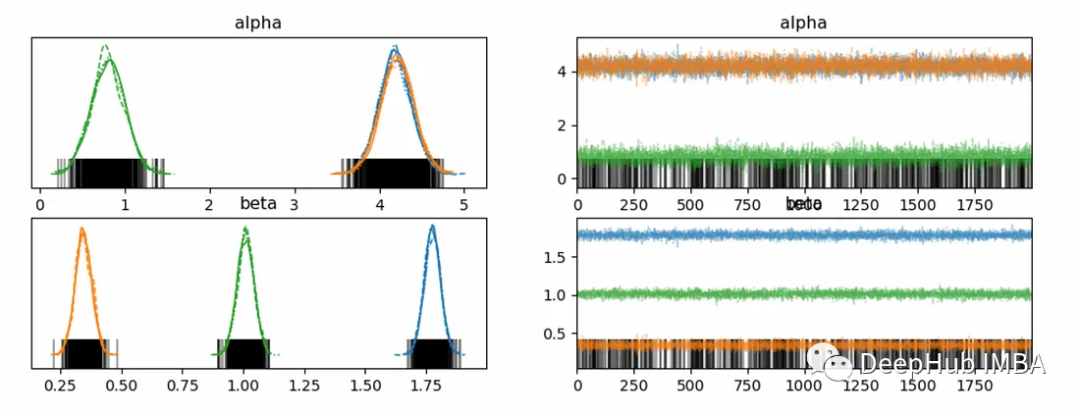
使用PyMC进行时间序列分层建模
在统计建模领域,理解总体趋势的同时解释群体差异的一个强大方法是分层(或多层)建模。这种方法允许参数随组而变化,并捕获组内和组间的变化。在时间序列数据中,这些特定于组的参数可以表示不同组随时间的不同模式。
机器学习算法(7)—— 朴素贝叶斯算法
朴素贝叶斯是一种分类算法,经常被用于文本分类,它的输出结果是某个样本属于某个类别的概率。(1)优点朴素贝叶斯模型发源于古典数学理论,有稳定的分类效率对缺失数据不太敏感,算法也比较简单,常用于文本分类分类准确度高,速度快(2)缺点由于使用了样本属性独立性的假设,所以如果特征属性有关联时其效果不好需要计
SDU CS 期末考回忆版合集
删除原有分散的版本,合订起来画个。包括:机器学习、算法、图形学、操作系统、编译原理、软件工程、大数据分析管理、计算机体系结构等。
6月人工智能论文推荐
6月人工智能论文推荐
10- 天猫用户复购预测 (机器学习集成算法) (项目十) *
阿里巴巴天池天猫复购预测的机器学习项目, 使用数据分析, 通过机器学习中的线性分类算法, 进行建模, 从而预测消费者行为, 复购情况 .
手把手教你做多重线性逐步回归
某研究收集到美国50个州关于犯罪率的一组数据,包括人口、面积、收入、文盲率、高中毕业率、霜冻天数、犯罪率共7个指标,现在我们想考察一下州犯罪率和哪些指标有关。数据上传SPSSAU后,在 “我的数据”中查看浏览原始数据,前5行数据如下:图1 “我的数据”查看浏览数据集线性回归中要求自变量为连续型数据,
[人工智能] TensorFlow 框架基本原理及使用
TensorFlow 是一款由 Google 开源的人工智能框架,是目前应用最广泛的深度学习框架之一。它可以在各种硬件平台上运行,包括单个 CPU、CPU 集群、GPU,甚至是分布式环境下的 CPU 和 GPU 组合。除了深度学习领域,TensorFlow 还支持其他机器学习算法和模型,如决策树SV
[大模型] LLaMA系列大模型调研与整理-llama/alpaca/lora(部分)
llama系列大模型调研及关键信息整理,llama/standford-alpaca/alpaca-lora/chinese-llama-alpaca/belle等
AI与大数据的结合(个人理解)
通过AI技术和大数据技术的结合,可以实现数据的高效处理和分析,从而实现更加智能化、高效化的数据应用。AI与大数据的结合,主要是利用大数据技术采集和存储大量的数据,然后应用AI技术对这些数据进行分析和处理,从而实现更加智能化、高效化的数据应用。通过大数据技术采集和分析车辆位置数据、交通流量数据等等,然
损失函数——均方误差(Mean Squared Error,MSE)
在使用MSE作为损失函数进行优化时,通常会采用梯度下降等优化算法来最小化MSE的值,从而提高模型的性能。MSE的值越小,说明模型的预测值与真实值之间的差异越小,模型的性能越好。如果需要在训练模型时使用MSE作为损失函数进行优化,可以在训练循环中计算损失,并使用反向传播算法更新模型参数。在PyTorc
推荐10个AI人工智能技术网站
AI World的主题包括AI技术、AI应用、AI实践和AI商业。AI Trends (https://www.aitrends.com/) 是一个专注于人工智能领域的网站,它提供了最新的AI技术和应用趋势的报道和分析。AI News(https://www.ainewsletter.com/)是一
损失函数——对数损失(Logarithmic Loss,Log Loss)
要在训练中使用对数损失作为损失函数,可以在模型训练的过程中调用 PyTorch 中的损失函数计算方法,并将计算得到的损失加入到反向传播过程中以更新模型参数。在 PyTorch 中,可以使用 nn.BCELoss() 来计算二元分类问题的对数损失,使用 nn.CrossEntropyLoss() 来计
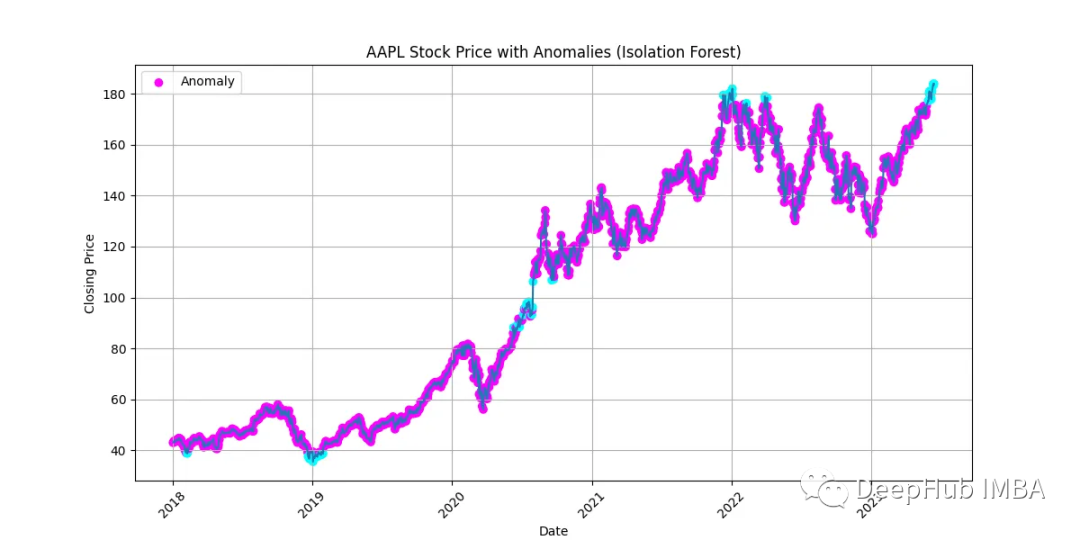
时间序列异常检测:统计和机器学习方法介绍
在本文中将探索各种方法来揭示时间序列数据中的异常模式和异常值。
AI大模型
本文将介绍什么是AI大模型,它能应用到哪些行业,使用AI大模型的具体步骤以及应该注意的事项。
机器学习课后练习题(期末复习题目附答案)
第九章 神经网络一. 单选题1. 以下关于感知器说法错误的是: ( )。A. 单层感知器可以用于处理非线性学习问题B. 可为感知器的输出值设置阈值使其用于处理分类问题C. 感知器是最简单的前馈式人工神经网络D. 感知器中的偏置只改变决策边界的位置正确答案: A2. 关于BP算法特点描述错误的是 (
数学建模算法与应用:预测模型(3)案例: SARS 疫情对经济指标影响
2003年的 SARS 疫情对中国部分行业的经济发展产生了一定的影响,特别是对部分疫情较严重的省市的相关行业所造成的影响是明显的,经济影响主要分为直接经济影响和间接影响.直接经济影响涉及到商品零售业、旅游业、综合服务等行业.很多方面难以进行定量地评估,现仅就 SARS 疫情较重的某市商品零售业、旅游
深度学习竞赛进阶技巧 - BLIP使用说明与实战
由于大规模模型的端到端的训练,视觉与语言的预训练模型的成本越来越高。本文提出了BLIP-2,这是一种通用的有效的预训练策略,它从现成的冷冻预训练图像编码器与大型的语言模型中引导视觉语言预训练。BLIP-2通过一个轻量级的查询transformer弥补了模态差距,该transformer分为两个阶段进

XGBoost超参数调优指南
本文将详细解释XGBoost中十个最常用超参数的介绍,功能和值范围,及如何使用Optuna进行超参数调优。
Milvus实践 第一章:简介与部署
业内最好的向量数据库及向量检索工具
Chatgpt给人类带来的机遇和挑战有哪些?
我们需要充分利用ChatGPT的优势和潜力,同时也需要警惕其可能带来的负面影响,采取适当的措施来保障人们的利益和权益,推动人工智能技术的健康发展和应用。技术风险和安全问题:ChatGPT需要依赖计算机系统和网络技术,这可能会带来技术风险和安全问题,如黑客攻击、数据泄露、人工智能算法错误等,这些问题需



