GBDT算法原理以及实例理解(含Python代码简单实现版)
GBDT算法原理以及实例理解(含Python代码简单实现版)
ChatGPT在小红书文案实践
今天聊一聊ChatGPT在小红书这个实际应用场景的案例。ChatGPT 以较低的门槛提高了使用者创作水平,有较高的下限,但如何创造更高质量的内容就要依靠使用者在领域的能力和AI使用技巧,作者无任何小红书推广和文案写作经验,文章内容来自ChatGPT和Notion Ai合作完成。
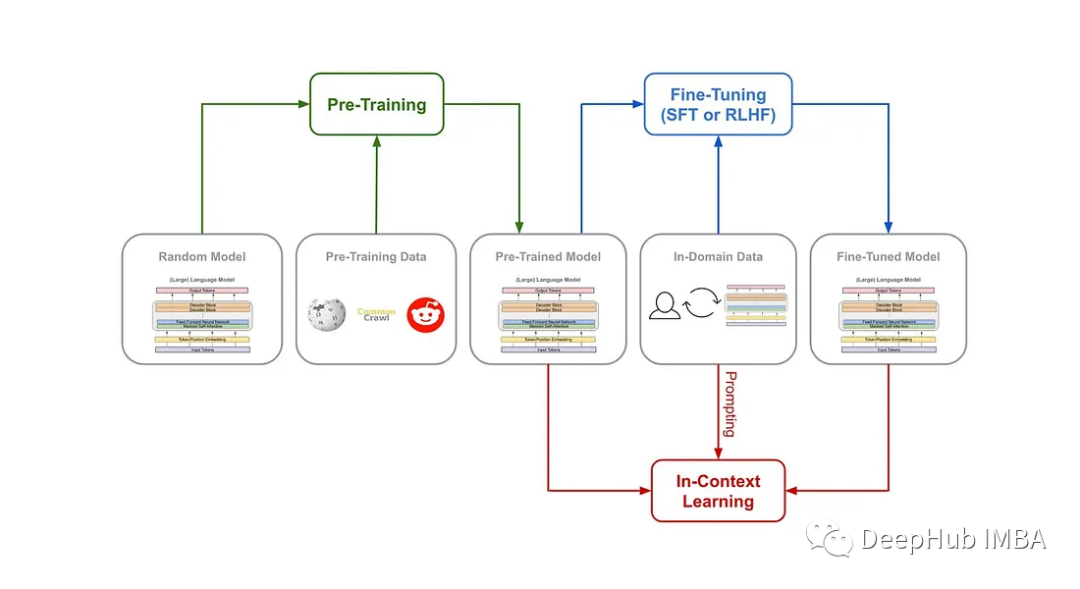
预训练、微调和上下文学习
最近语言模型在自然语言理解和生成方面取得了显著进展。这些模型通过预训练、微调和上下文学习的组合来学习。在本文中将深入研究这三种主要方法,了解它们之间的差异,并探讨它们如何有助于语言模型的学习过程。
机器学习(线性回归实训)------波士顿房价
机器学习,线性回归,sklearn,波士顿房价
欧氏距离 VS 余弦距离
xx场景应该用欧氏距离还是余弦距离?有啥区别?
SVN无法连接到服务器的各种问题原因及解决办法
SVN专业使用教程详解第一节 安装服务器第一步 下载SVN服务器,需要链接的请私信。正在上传…重新上传取消点击下载的执行文档进行安装正在上传…重新上传取消选择组件选择在部署 VisualSVN Server 时安装VisualSVN Server 和 Administration Tools组件。调
时序分析 49 -- 贝叶斯时序预测(一)
贝叶斯时序分析简单介绍和Python示例
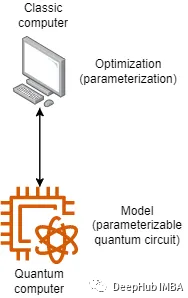
量子机器学习Variational Quantum Classifier (VQC)简介
变分量子分类器(Variational Quantum Classifier,简称VQC)是一种利用量子计算技术进行分类任务的机器学习算法。它属于量子机器学习算法家族,旨在利用量子计算机的计算能力,潜在地提升经典机器学习方法的性能。
lightgbm使用手册——参数篇
lgbm参数记录
中医脉诊仪:结合传统与现代技术的诊断工具
中医脉诊仪是一种将传统脉诊原理与现代科技相结合的诊断工具,具有高度的应用价值。通过高精度压力传感器、数字处理技术和人工智能算法,脉诊仪能够实现客观、量化的脉搏数据分析,提高诊断的准确性和效率。在临床、教学和研究等领域均有广泛应用。随着科技的进步,中医脉诊仪将朝着多功能化、智能化和个性化等方向发展,进

【人工智能】大模型的本质是这个世界抽象出来的函数
在数学中,函数是一种映射关系,它将一个自变量映射到一个因变量上。通常用一个符号表示函数,例如fxf(x)fx,其中xxx是自变量,fxf(x)fx是因变量。函数可以看作是一个黑盒子,输入自变量xxx,输出因变量fxf(x)fx。函数的本质是描述一个映射关系,它可以用图像、表格、公式等多种方式来表示。

时间序列预测的20个基本概念总结
时间序列是一组按时间顺序排列的数据点
2023年计算机、视觉与智能技术国际会议(ICCVIT 2023)
算法、自主和可信计算、5G、AI在通信中的应用、人工智能、机器学习、计算机视觉、计算智能、模式识别、大数据、数据挖掘、区块链技术、生物医学信息学与计算、计算机体系结构、计算机系统、嵌入式系统、数据压缩、高性能计算、图像处理、移动计算、移动和普适计算、计算机与网络安全、密码、数据隐藏、并行和分布式计算
深入理解深度学习——正则化(Regularization):正则化和欠约束问题
大多数形式的正则化能够保证应用于欠定问题的迭代方法收敛。例如,当似然的斜率等于权重衰减的系数时,权重衰减将阻止梯度下降继续增加权重的大小。是奇异的,这些方法就会失效。当数据生成分布在一些方向上确实没有差异时,或因为例子较少(即相对输入特征的维数来说)而在一些方向上没有观察到方差时,这个矩阵就是奇异的
ChatGPT背后的大预言模型 以及《ChatGPT全能应用一本通》介绍
机器学习模型具有基于特定领域/区域的信息,可以根据给定的输入提供输出。为了创建模型,使用了机器学习技术称为监督学习,在其中给定了某些标记输入来训练模型。随着数据量的增加,正确标记数据变得困难。大型语言模型(LLM)是设计用于根据给定提示或输入生成不同类型响应(视频,文本,图像)的AI系统。这些模型使

使用NLPAUG 进行文本数据的扩充增强
数据增强可以通过添加对现有数据进行略微修改的副本或从现有数据中新创建的合成数据来增加数据量。这种数据扩充的方式在CV中十分常见,因为对于图像来说可以使用很多现成的技术,在保证图像信息的情况下进行图像的扩充。
多传感器数据融合技术
多传感器数据融合技术形成于上世纪80年代,目前已成为研究的热点。它不同于一般信号处理,也不同于单个或多个传感器的监测和测量,而是对基于多个传感器测量结果基础上的更高层次的综合决策过程。把分布在不同位置的多个同类或不同类传感器所提供的局部数据资源加以综合进行分析,消除多传感器信息之间可能存在的冗余和矛
Box-Cox变换详解
①Box-Cox变换方法介绍 ②Box-Cox变换归一化与其他归一化方法的区别 ③Box-Cox变换的优缺点
MultiHeadAttention多头注意力机制的原理
MultiHeadAttention多头注意力作为Transformer的核心组件,其主要由多组自注意力组合构成,Attention Is All You Need,self-attention。



