
作者🕵️♂️:让机器理解语言か
专栏🎇:机器学习sklearn
描述🎨:本专栏主要分享博主学习机器学习的笔记和一些心得体会。
寄语💓:🐾没有白走的路,每一步都算数!🐾
0、介绍
监督学习(英语:Supervised learning)是机器学习中最为常见、应用最为广泛的分支之一。本次实验将带你了解监督学习中常见的分类方法,并学会使用 scikit-learn 来构建预测模型,用于解决实际问题。
知识点
- 常用监督学习方法
- 常用算法对比评估
除了前面两节介绍过的线性模型以及支持向量机,还有很多监督学习方法都非常流行。例如:K 近邻、决策树、随机森林、朴素贝叶斯等。
1、K 近邻
K 近邻是一种十分常用的监督学习算法。简单来讲,K 近邻就是假设一个给定的数据集,且**数据的类别已经确定**。这些**数据的特征所构成的特征向量可以映射到对应的特征空间**中。现在,假设一个输入实例,我们可以计算该输入和其他数据点之间的距离,再通过多数表决的方式,来确定新输入实例的类别,最后完成分类。
其中,K 近邻中的「近邻」代表**原有特征空间中与新输入实例距离最近的那些样本**。而 K 代表**距离最近的 K 个样本。**所以,对于 K 近邻而言。**K 值的大小和距离的度量方式**(欧式距离或者曼哈顿距离)是其构成的两个关键因素。

如上图所示,原数据集由红、绿两类组成。现在,我们新输入一个橙色实例,图中表示了样本对应在特征空间的位置。现在,我们确定 K = 3,然后可以圈定出距离橙色实例最近的 3 个样本点。其中,红色样本为 1 个,绿色 2 个。根据多数表决的规则,最终确定新输入的橙色样本数据被判定为 B 类别。而当我们指定 K = 7 时,红色样本 4 个,绿色样本 3 个,则橙色样本被判定为 A 类别。
2、决策树和随机森林
决策树也是一种十分常见的监督学习方法。它是一种特殊的树形结构,一般由节点和有向边组成。其中,节点表示特征、属性或者一个类。而有向边包含有判断条件。

如图所示,决策树从根节点开始延伸,经过不同的判断条件后,到达不同的子节点。而上层子节点又可以作为父节点被进一步划分为下层子节点。一般情况下,我们从根节点输入数据,经过多次判断后,这些数据就会被分为不同的类别。这就构成了一颗简单的分类决策树。
当我们使用决策树分类时,对于已有训练集只建立一颗决策树。而随机森林的概念是,对于一个训练集随机建立多颗决策树。而建立这些决策树时,会采取一种叫 **Bootstrap **的取样方式,即每一次从数据集中又放回的取出一部分数据,再用这部分数据去建立小决策树。对于随机森林而言,**最终的分类结果由众多小决策树输出类别的众数确定。**下图展示了一个由 3 颗决策树构成的随机森林过程。

由于随机森林的特点,**有效地降低过拟合程度,具有较好的泛化误差。**另外,**训练速度也非常快,模型的表现往往都比较好**,是十分受欢迎的一种机器学习方法。
监督学习包含的方法众多,在此就不再一一介绍。下面我们直接上手,看一看 scikit-learn 中一些常用监督学习方法的分类效果如何。

3、常见监督学习方法
下面,我们通过同一个示例数据集来对常见的监督学习算法分类性能做一个比较。
为了更方便可视化,这里选用了一个随机生成的二分类数据集。总共包含 300 条数据,类别为 0 和 1。
接下来,你可以通过 Pandas 读取数据集并预览这些数据。
import pandas as pd # 加载 pandas 模块
import warnings
warnings.filterwarnings('ignore')
# 读取 csv 文件, 并将第一行设为表头
data = pd.read_csv(
"https://labfile.oss.aliyuncs.com/courses/866/class_data.csv", header=0)
data.head() # 输出数据预览

通常情况下,可视化是直观认识陌生数据的很好方法。这里,我们通过 Matplotlib 来可视化这些数据。只需要 3 行代码,就可以画出数据集的散点图。
from matplotlib import pyplot as plt # 加载绘图模块
%matplotlib inline
plt.scatter(data["X"], data['Y'], c=data['CLASS']) # 绘制散点图

上面,我们用 **
c=data['CLASS']
** 参数来控制散点的颜色。
接下来,加载本次实验需要的模块,以及 scikit-learn 中常见的分类器。你也可以通过 官方文档 对应的页面来查看这些分类方法。
# 集成方法分类器
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import BaggingClassifier
from sklearn.ensemble import ExtraTreesClassifier
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.ensemble import RandomForestClassifier
# 高斯过程分类器
from sklearn.gaussian_process import GaussianProcessClassifier
# 广义线性分类器
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.linear_model import RidgeClassifier
from sklearn.linear_model import SGDClassifier
# K近邻分类器
from sklearn.neighbors import KNeighborsClassifier
# 朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB
# 神经网络分类器
from sklearn.neural_network import MLPClassifier
# 决策树分类器
from sklearn.tree import DecisionTreeClassifier
from sklearn.tree import ExtraTreeClassifier
# 支持向量机分类器
from sklearn.svm import SVC
from sklearn.svm import LinearSVC
接下来,建立预测模型,采用默认参数即可。由于方法较多,所有这里就不再依次单独定义模型,而是用列表形式管理。
# 建立模型
models = [
AdaBoostClassifier(),
BaggingClassifier(),
ExtraTreesClassifier(),
GradientBoostingClassifier(),
RandomForestClassifier(),
GaussianProcessClassifier(),
PassiveAggressiveClassifier(),
RidgeClassifier(),
SGDClassifier(),
KNeighborsClassifier(),
GaussianNB(),
MLPClassifier(),
DecisionTreeClassifier(),
ExtraTreeClassifier(),
SVC(),
LinearSVC()
]
# 依次为模型命名
classifier_Names = ['AdaBoost', 'Bagging', 'ExtraTrees',
'GradientBoosting', 'RandomForest', 'GaussianProcess',
'PassiveAggressive', 'Ridge', 'SGD',
'KNeighbors', 'GaussianNB', 'MLP',
'DecisionTree', 'ExtraTree', 'SVC', 'LinearSVC']
然后,划分数据集。70% 用于训练,另外 30% 用于测试。
from sklearn.model_selection import train_test_split # 导入数据集切分模块
feature = data[['X', 'Y']] # 指定特征变量
target = data['CLASS'] # 指定标签变量
X_train, X_test, y_train, y_test = train_test_split(
feature, target, test_size=.3) # 切分数据集
准备好数据之后,就可以开始模型训练和测试了。
from sklearn.metrics import accuracy_score # 导入准确度评估模块
# 遍历所有模型
for name, model in zip(classifier_Names, models):
model.fit(X_train, y_train) # 训练模型
pre_labels = model.predict(X_test) # 模型预测
score = accuracy_score(y_test, pre_labels) # 计算预测准确度
print('%s: %.2f' % (name, score)) # 输出模型准确度
输出结果:
AdaBoost: 0.82 Bagging: 0.86 ExtraTrees: 0.87 GradientBoosting: 0.86 RandomForest: 0.84 GaussianProcess: 0.88 PassiveAggressive: 0.76 Ridge: 0.86 SGD: 0.81 KNeighbors: 0.86 GaussianNB: 0.86 MLP: 0.87 DecisionTree: 0.79 ExtraTree: 0.84 SVC: 0.90 LinearSVC: 0.86
我们可以看到,这 16 个分类器最终的准确度均在 80% ~ 90% 之间,差距不是很大。对于这种现象,主要有两个原因。首先,本次使用的是一个**非常规范整洁的线性分类数据集**。其次,**所有的分类器均采用了默认参数**,而 scikit-learn 提供的默认参数一般已经较优。
接下来,我们通过可视化的方法将每一个模型在分类时的决策边界展示出来,这样能更加直观的感受到机器学习模型在执行分类预测时发生的变化。
from matplotlib.colors import ListedColormap # 加载色彩模块
import numpy as np # 导入数值计算模块
from tqdm.notebook import tqdm
# 绘制数据集
i = 1 # 为绘制子图设置的初始编号参数
cm = plt.cm.Reds # 为绘制等高线选择的样式
cm_color = ListedColormap(['red', 'yellow']) # 为绘制训练集和测试集选择的样式
# 栅格化
x_min, x_max = data['X'].min() - .5, data['X'].max() + .5
y_min, y_max = data['Y'].min() - .5, data['Y'].max() + .5
xx, yy = np.meshgrid(np.arange(x_min, x_max, .1),
np.arange(y_min, y_max, .1))
# 模型迭代
plt.figure(figsize=(20, 10))
for name, model in tqdm(zip(classifier_Names, models)):
ax = plt.subplot(4, 4, i) # 绘制 4x4 子图
model.fit(X_train, y_train) # 模型训练
pre_labels = model.predict(X_test) # 模型测试
score = accuracy_score(y_test, pre_labels) # 模型准确度
# 根据类的不同选择决策边界计算方法
if hasattr(model, "decision_function"):
Z = model.decision_function(np.c_[xx.ravel(), yy.ravel()])
else:
Z = model.predict_proba(np.c_[xx.ravel(), yy.ravel()])[:, 1]
# 绘制决策边界等高线
Z = Z.reshape(xx.shape)
ax.contourf(xx, yy, Z, cmap=cm, alpha=.6)
# 绘制训练集和测试集
ax.scatter(X_train['X'], X_train['Y'], c=y_train, cmap=cm_color)
ax.scatter(X_test['X'], X_test['Y'], c=y_test,
cmap=cm_color, edgecolors='black')
# 图形样式设定
ax.set_xlim(xx.min(), xx.max())
ax.set_ylim(yy.min(), yy.max())
ax.set_xticks(())
ax.set_yticks(())
ax.set_title('%s | %.2f' % (name, score))
i += 1
按照上面的步骤执行,你就能看到如下图所示的对比图了。

上面将决策边界绘制出来,并用等高线图显示。其中,颜色越深表示偏向于黄色散点分类的概率越高,而颜色越浅,则表示偏向红色散点的概率越高。
为了进一步探索各分类器对于不同特征分布的数据集的适用情况。接下来,我们将原有数据集做一些变换。
在前几节的课程中,我们都知道了**
sklearn.datasets
**这个模块可以导入一些预设的数据集。其实,不仅如此,这个模块开提供了一些数据集的生成方法。比如:
- **
sklearn.datasets.make_circles**方法可以生成大圆环包小圆环样式的数据集。 sklearn.datasets.make_moons方法可以生成两个交织间隔圆环样式的数据集。
from sklearn import datasets
# 生成 200 个包含噪声的环状样本
circles = datasets.make_circles(n_samples=200, noise=.1)
plt.scatter(circles[0][:, 0], circles[0][:, 1], c=circles[1])

# 生成 300 个包含噪声的月牙状样本
moons = datasets.make_moons(n_samples=300, noise=.2, random_state=1)
plt.scatter(moons[0][:, 0], moons[0][:, 1], c=moons[1])

这两组数据都是无法进行线性分类,所以如果是非线性分类器,其结果应该会好很多。
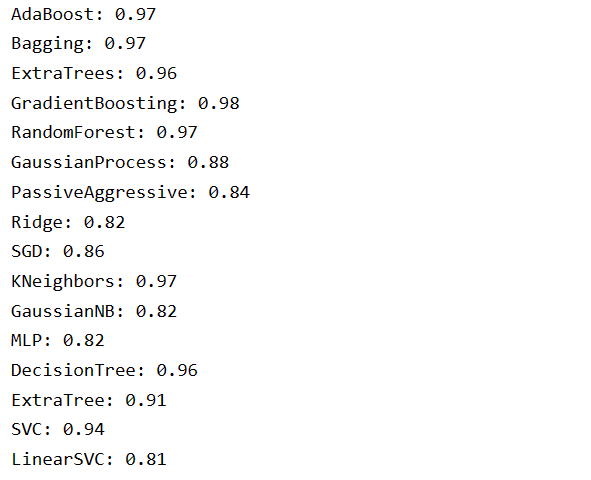
# 对月牙状样本进行分割测试
X_train, X_test, y_train, y_test = train_test_split(
moons[0], moons[1], test_size=0.3)
for name, model in zip(classifier_Names, models):
model.fit(X_train, y_train) # 训练模型
pre_labels = model.predict(X_test) # 模型预测
score = accuracy_score(y_test, pre_labels) # 计算预测准确度
print('%s: %.2f' % (name, score)) # 输出模型准确度
**输出结果: **
小练习
自己尝试通过** **sklearn.datasets.make_multilabel_classification方法生成一个多类别的数据集,并通过常见的非线性分类器完成分类。
3、实验总结
本次实验对比了 scikit-learn 中常见的监督学习方法,我们可以看出不同方法之间差别。另外,对于不同空间分布的数据集,模型的适用性也不一样。大多数非线性分类模型的表现和适用性都较好。
版权归原作者 让机器理解语言か 所有, 如有侵权,请联系我们删除。