
YOLOv7训练预测
预测结果:


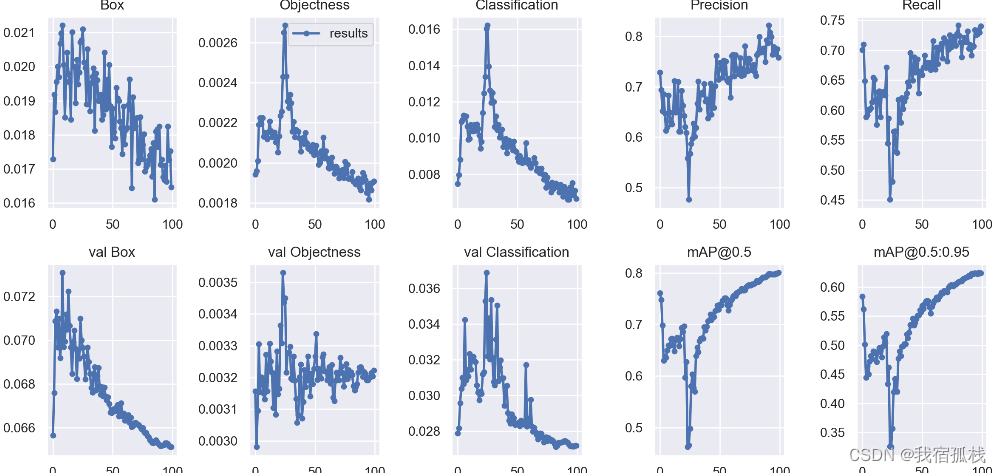
一、数据集准备
数据集的准备包括数据集适配YOLO格式的重新分配以及相应配置文件的书写,此处可查看博主的TT100K2yolo的重新分配博文,该文章包括数据集划分,配置文件书写,以及最终的数据集层级目录组织,可以直接提供给下一步进行训练。
需要注意的是数据集的yaml文件有一点不一样:
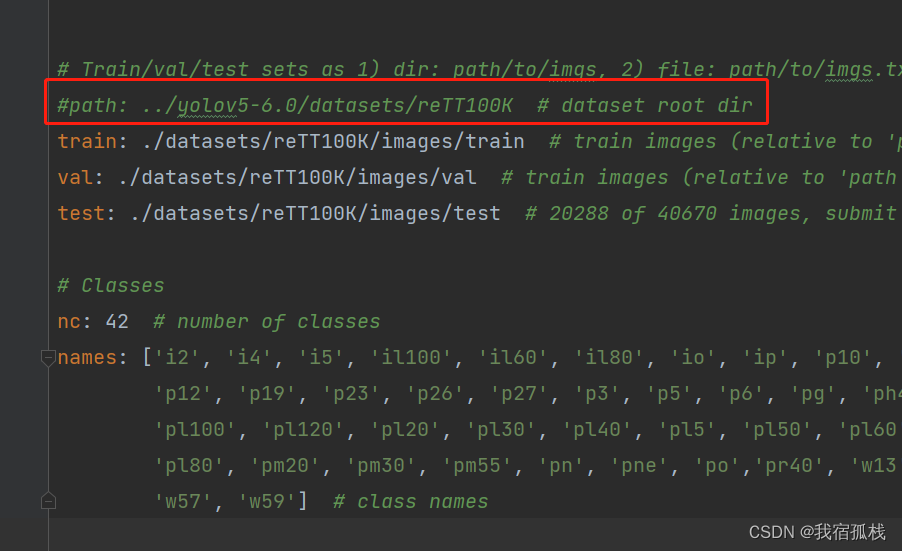
YOLOv7中么有图中红色框中的path路径,注释掉即可。
二、环境配置
可参考博主YOLOv5的环境部署,博主实测YOLOv7可直接在YOLOv5环境下直接训练预测。
三、训练
训练参数也和YOLOv5通用。
注意事项:YOLOv7比YOLOv5更吃性能,博主3080(10G)YOLOv5batchsize可以给40,训练v7只能给8。而且收敛速度也比较慢,博主最后是迭代了有500个epoch。
2.1 train.py
修改配置文件参数。
官方代码中这块默认yaml文件是
coco128.yaml
:
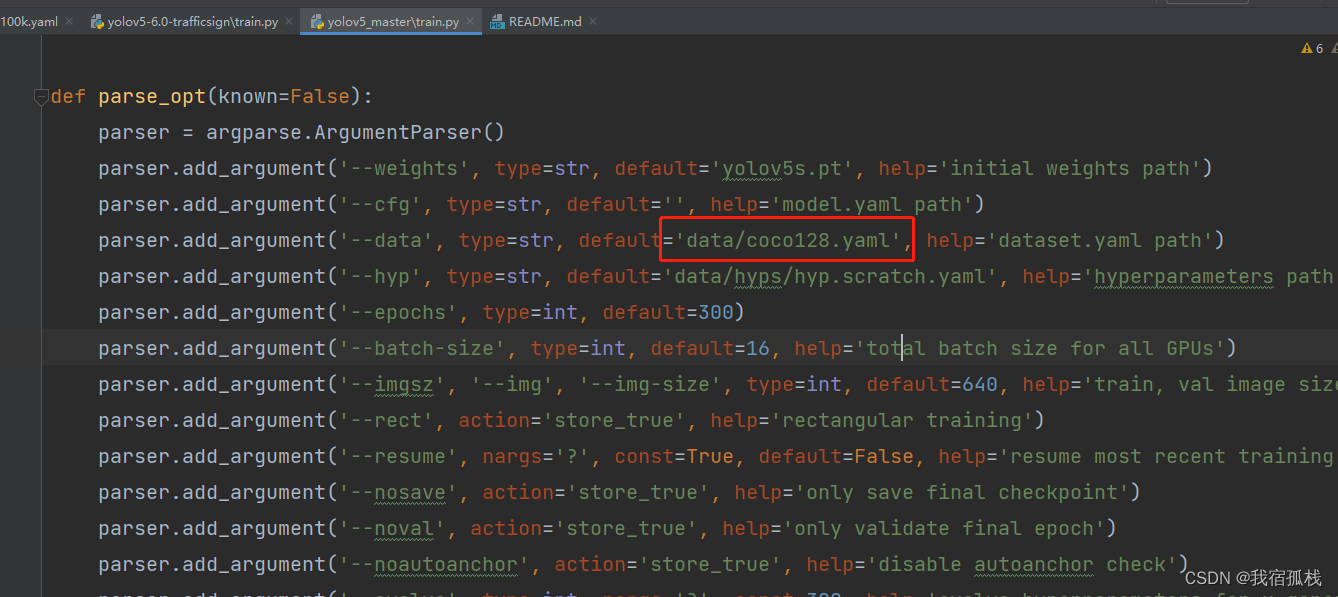
同理,这里直接将上节中的yaml文件
rett100k.yaml
替换掉
coco128.yaml
即可。
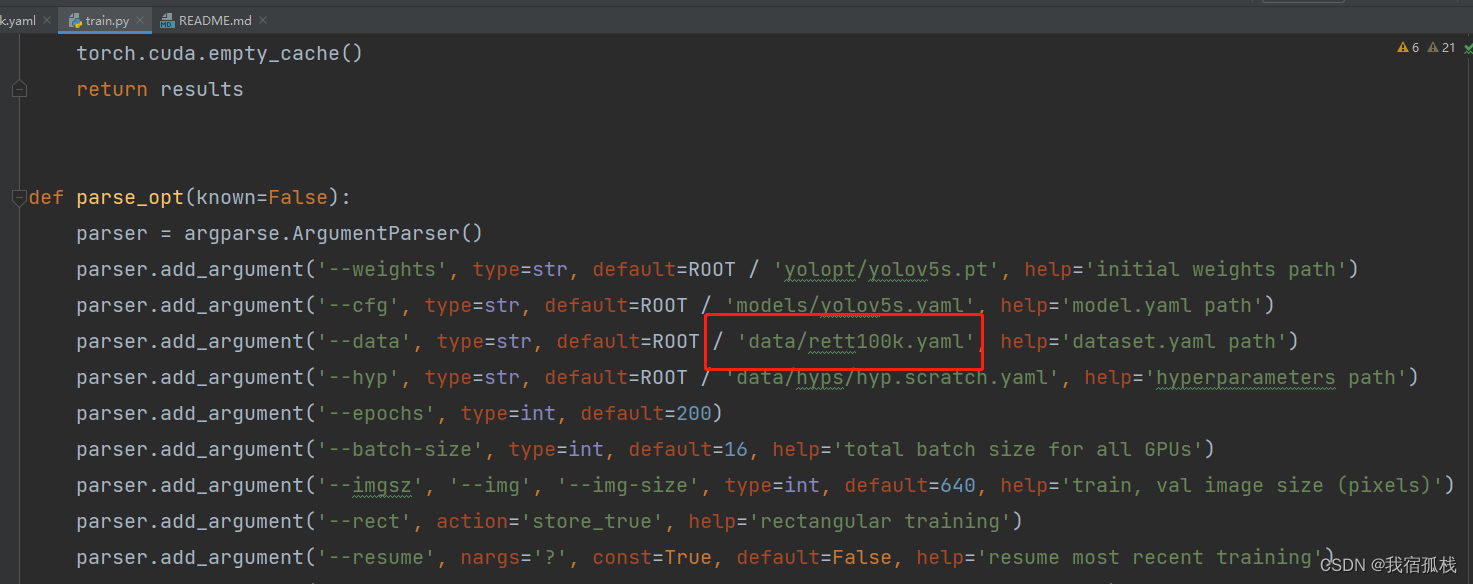
这里是在代码中修改,还有一种方式是在训练的时候输入yaml文件地址,可参见readme文档。
2.2 训练代码运行
当然首先需要进入YOLOv5目录下,博主是在新建的虚拟环境中配置的yolov5,所以需要先激活pytorch环境: 可以先通过以下命令查看虚拟环境:
可以先通过以下命令查看虚拟环境:
conda info -e
博主yolov5的虚拟环境是在jpytorch下的,所以执行:
source activate jpytorch
如此便可以进行训练操作了。
再执行以下语句:
python train.py --data rett100k.yaml --cfg yolov5s.yaml --weights '' --batch-size 64

这里batch_size可根据自身计算机性能选择:
注意:博主用的是3080GPU,选择的64,结果都出现了图里上半部分的错误:
RuntimeError: Unable to find a valid cuDNN algorithm to run convolution
,于是重新选择了40便开始正常训练了;另外训练期间不要在终端用键盘,否则会打断训练,只能重新来过。

接下坐等其训练结束就好啦
2.3 训练参数说明(
train.py
)
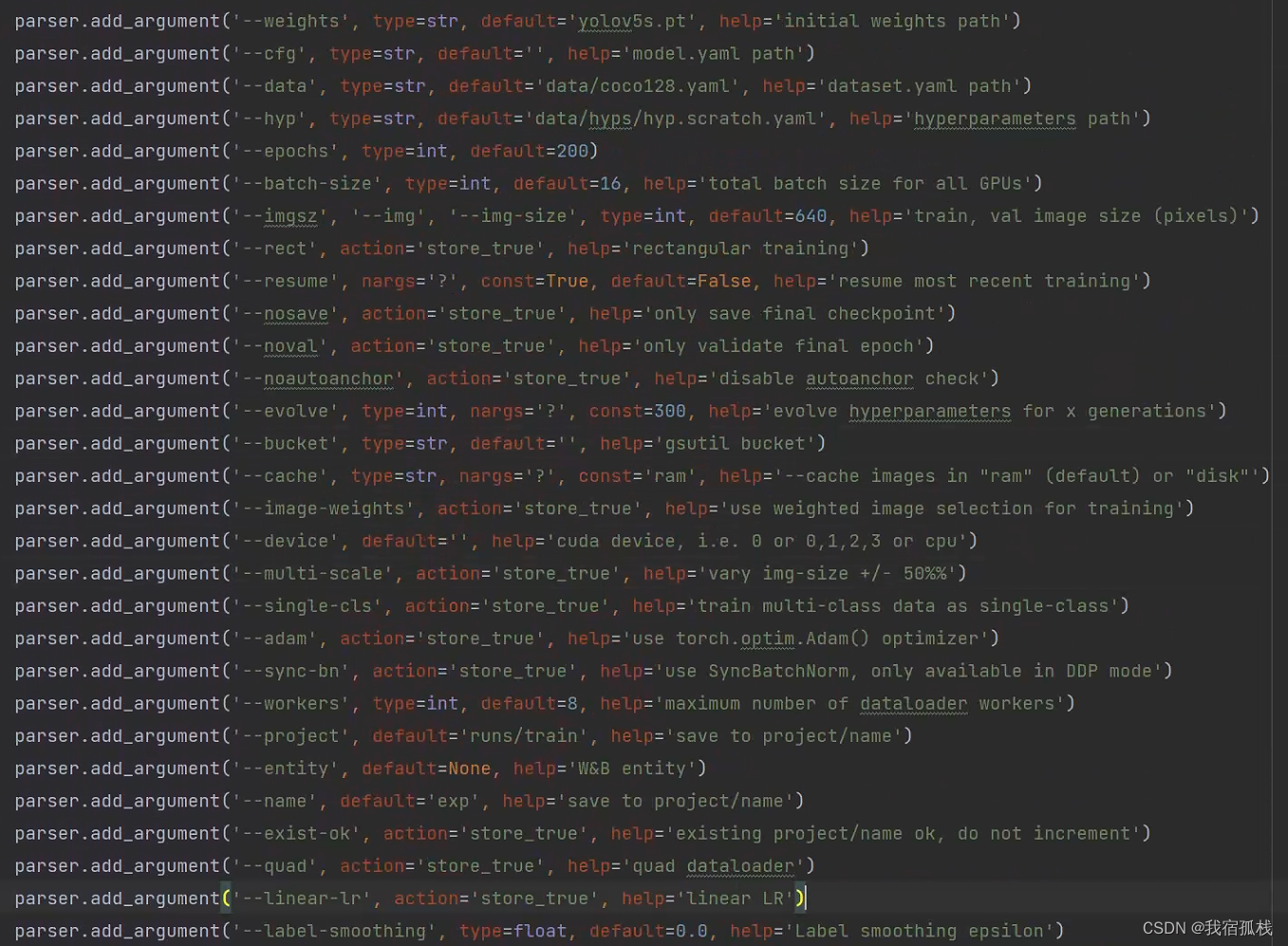
- weights:指定预训练权重路径;默认是使用
yolov5s.pt; - cfg:模型配置文件,比如models/yolov5s.yaml。
- data:数据集对应的yaml参数文件,里面主要存放数据集的类别和路径信息;
- hyp: 训练网络的一些超参数设置,(一般用不到)
- epochs: 轮数,默认300,需要指定;
- batch-size:每次输出给神经网络的图片数(一般爆显存即cuda out of memory时可以调小此参数解决);
- img-size: 训练和测试数据集的图片尺寸(个人理解为分辨率),默认640,640nargs=‘+’ 表示参数可设置一个或多个,两个数字前者为训练集大小,后者为测试集大小;
- rect: 只要加上’–rect’程序就会将rect设为true; 所谓矩阵推理就是不再要求你训练的图片是正方形了;矩阵推理会加速模型的推理过程,减少一些冗余信息。下图分别是矩阵推理方式和方形推理方式

- resume:断点续训:即是否在之前训练的一个模型基础上继续训练,default 值默认是 false。一种方式是先将train.py中这一行default=False 改为 default=True:
- nosave:是否只保存最后一轮的pt文件;默认是保存best.pt和last.pt;
- notest:只在最后一次进行测试,正常情况下每个epoch都会计算mAP;如果开启了这个参数,那么就只在最后一轮上进行测试,不建议开启。
- noautoanchor:是否禁用自动锚框;默认开启;
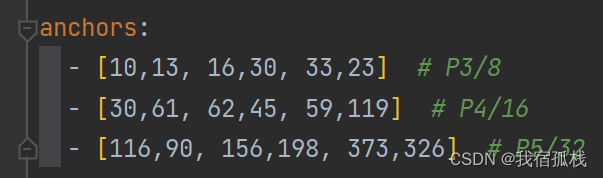
yolov5中预先设定了一下锚框,这些锚框是针对coco数据集的,其他目标检测也适用,如下图所示:
如果开启了noautoanchor,在训练开始前,会自动计算数据集标注信息针对默认锚框的最佳召回率,当最佳召回率大于等于0.98时,则不需要更新锚框;如果最佳召回率小于0.98,则需要重新计算符合此数据集的锚框。建议不要改动此选项。
- evolve:是否寻找最优参数,yolov5使用遗传超参数进化,提供的默认参数是通过在COCO数据集上使用超参数进化得来的(也就是hpy文件夹下默认的超参数)。由于超参数进化会耗费大量的资源和时间,建议不要动这个参数。
遗传算法是利用种群搜索技术将种群作为一组问题解,通过对当前种群施加类似生物遗传环境因素的选择、交叉、变异等一系列的遗传操作来产生新一代的种群,并逐步使种群优化到包含近似最优解的状态,遗传算法调优能够求出优化问题的全局最优解,优化结果与初始条件无关,算法独立于求解域,具有较强的鲁棒性,适合于求解复杂的优化问题,应用较为广泛。
- bucket:这个参数是 yolov5 作者将一些东西放在谷歌云盘,可以进行下载,如今没必要使用。
- cache-images:是否提前缓存图片到内存,以加快训练速度,默认False;开启这个参数就会对图片进行缓存,从而更好的训练模型;
- image-weights:是否启用加权图像策略,测试过程中,对测试不太好的地方加权重,,默认是不开启的;主要是为了解决样本不平衡问题。开启后会对于上一轮训练效果不好的图片,在下一轮中增加一些权重
- device:训练网络的设备cpu还是gpu;
- multi-scale:训练过程中是否启用多尺度训练,默认不开启;
- 多尺度训练是指设置几种不同的图片输入尺度,训练时每隔一定iterations随机选取一种尺度训练,这样训练出来的模型鲁棒性更强。
- 输入图片的尺寸对检测模型的性能影响很大,在基础网络部分常常会生成比原图小数十倍的特征图,导致小物体的特征描述不容易被检测网络捕捉。通过输入更大、更多尺寸的图片进行训练,能够在一定程度上提高检测模型对物体大小的鲁棒性。
- single-cls:训练数据集是单类别还是多类别,默认False;
- adam:是否采用adam,可选SGD,Adam,AdamW;
- sync-bn:是否开启跨卡同步BN;开启后,可使用 SyncBatchNorm 进行多 GPU分布式训练;
- local_rank:DistributedDataParallel 单机多卡训练,一般不改动
- workers: 进程数,多线程训练
- project:训练结果保存路径,默认在runs/train;
- entity:在线可视化工具wandb,作用不大,不必考虑;
- name: 训练结果保存文件名,默认在exp文件夹;
- exist-ok: 覆盖掉上一次的结果,不新建训练结果文件;如果指定了这个参数的话,那么本次预测的结果还是保存在上一次保存的文件夹里;如果不指定,就是每预测一次结果,就保存在一个新的文件夹里。
- quad:在dataloader时采用什么样的方式读取我们的数据
- linear-lr:用于对学习速率进行调整,默认为 false,含义是通过余弦函数来降低学习率,生效后按照线性的方式去调整学习率;
- label-smoothing: 对标签进行平滑处理,防止过拟合,默认不起用
- upload_dataset:是否上传dataset到wandb tabel,默认False;启用后,将数据集作为交互式 dsviz表 在浏览器中查看、查询、筛选和分析数据集
- bbox_interval:设置界框图像记录间隔 Set bounding-box image logging interval for W&B 默认-1
- save-period:多少个epoch保存一下checkpoint,default=-1。
- artifact_alias:使用数据的版本,忽略即可;
- local_rank:DistributedDataParallel 单机多卡训练,单GPU设备不需要设置;
- freeze:冻结哪些层,不去更新训练这几层的参数;
冻结训练是迁移学习常用的方法。当数据集较小时,我们会选择预训练好的模型进行微调。大型数据集预训练好的权重主干特征提取能力是比较强的,这个时候我们只需要冻结主干网络,fine-tune后面层就可以了,不需要从头开始训练,大大减少了时间而且还提高了性能。
- patience:早停轮数,默认100;如果模型在100轮里没有提升,则停止训练模型。
三、检测
3.1 测试代码运行
最简单的方式就是将图片放置到如图目录下,
python detect.py --weights runs/train/exp14/weights/best.pt --source test/test --output run/now
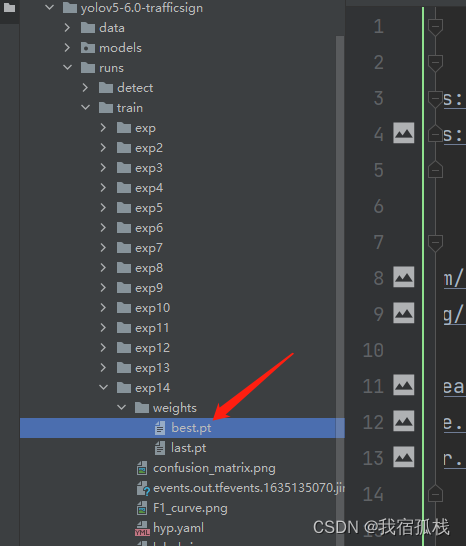
注意权重地址按照如图所示给,选择最后一个exp里边的pt文件。
这里
--source 0
表示使用电脑摄像头进行检测。
检测结果如下:


3.2 检测参数说明(
detect.py
)
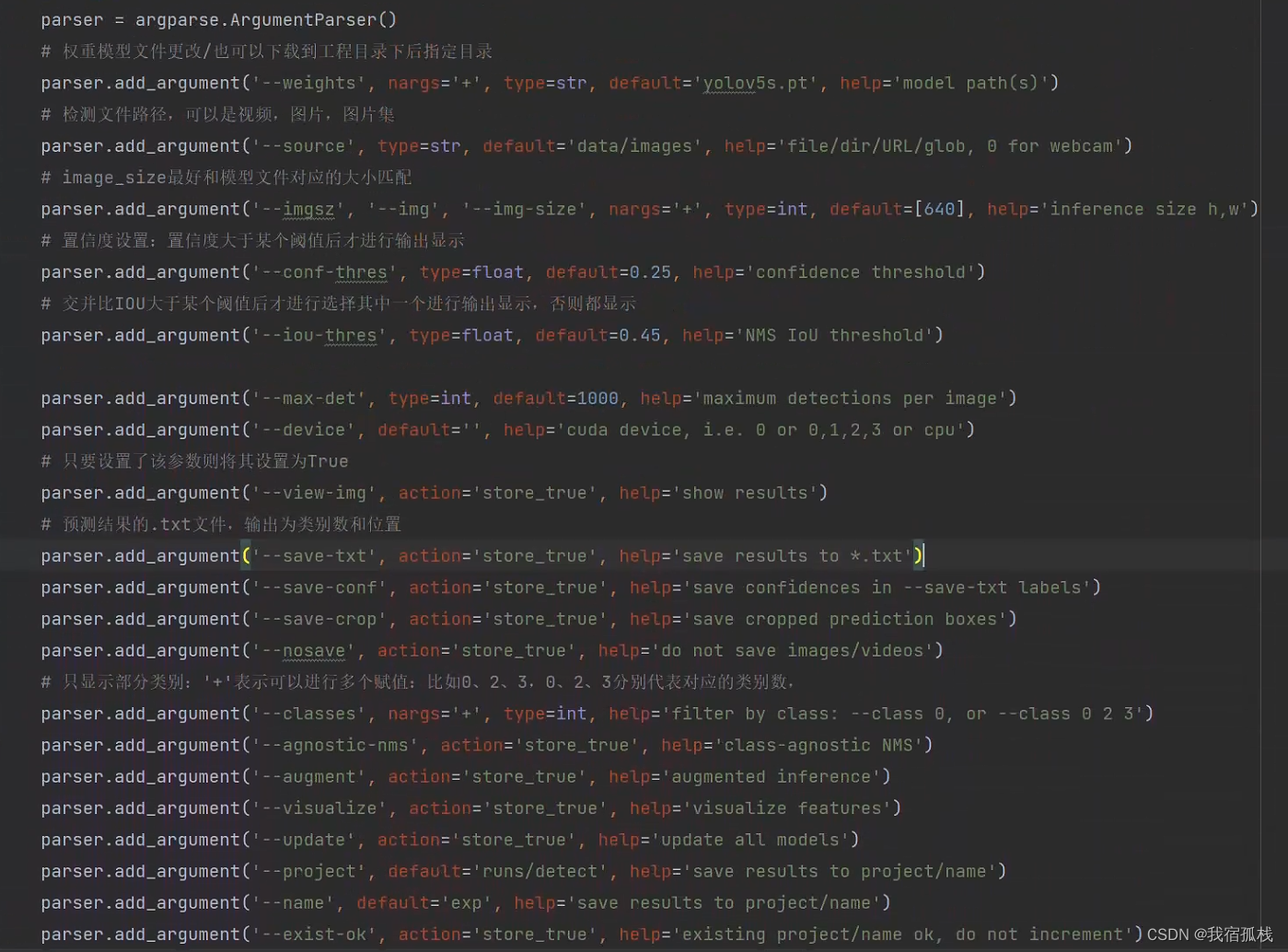
- weights:,在这里推理预测用的训练好的权重文件;
- source:测试数据,可以是图片/视频路径,也可以是’0’(电脑自带摄像头),也可以是rtsp等视频流;
- output:网络预测之后的图片/视频的保存路径
- img-size:网络输入图片大小
- conf-thres::置信度阈值(检测精度,作者是设置的0.25),置信度的阈值,超过这个阈值的预测框就会被预测出来
- iou-thres::做nms的iou阈值()
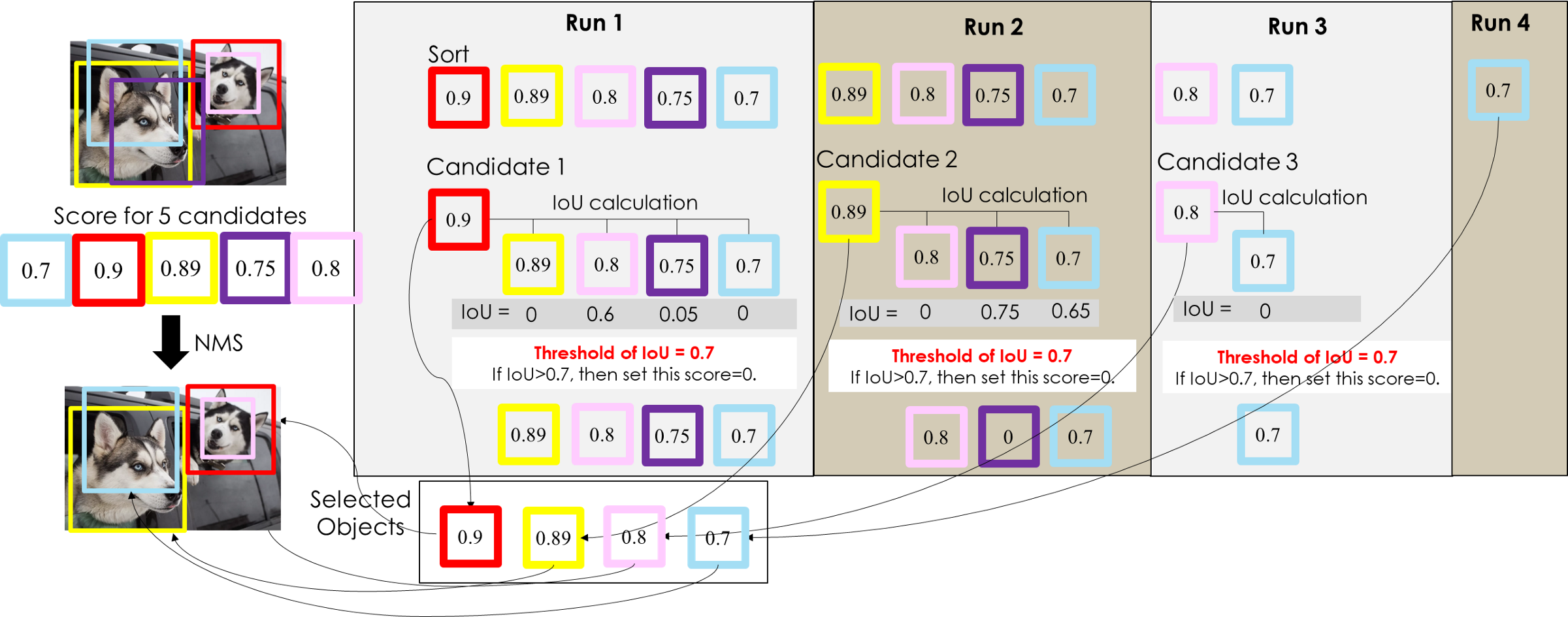
NMS步骤:
对 BBox 按置信度排序,选取置信度最高的 BBox(所以一开始置信度最高的 BBox 一定会被留下来);
对剩下的 BBox 和已经选取的 BBox 计算 IOU,淘汰(抑制) IOU 大于设定阈值的 BBox(在图例中这些淘汰的 BBox 的置信度被设定为0)。
重复上述两个步骤,直到所有的 BBox 都被处理完,这时候每一轮选取的 BBox 就是最后结果。
- iou-thres=0.5时,NMS 只运行了两轮就选取出最终结果:第一轮选择了红色 BBox,淘汰了粉色 BBox;第二轮选择了黄色 BBox,淘汰了紫色 BBox 和青色 BBox。
- iou-thres=0.7
- iou-thres分别取“0”,“0.45”,“1”

- max-det:每张图最大检测数量,默认是最多检测1000个目标;
- view-img:检测的时候是否展示预测之后的图片/视频,默认False 如果输入代码python detect.py --view-img,在检测的时候系统要把我检测的结果实时的显示出来,假如我文件夹有5张图片,那么模型每检测出一张就会显示出一张,直到所有图片检测完成。
- save-txt:是否将预测的框坐标以txt文件形式保存,txt默认保存物体的类别索引和预测框坐标(YOLO格式),每张图一个txt,txt中每行表示一个物体;默认False;
- save-conf:上面保存的txt中是否包含置信度
- save-crop:是否把模型检测的物体裁剪下来;开启了这个参数会在crops文件夹下看到几个以类别命名的文件夹,里面保存的都是裁剪下来的图片。
- nosave:不保存预测的结果;但是还会生成exp文件夹,只不过是一个空的exp。这个参数应该是和“–view-img”配合使用的;
- classes:指定检测某几种类别,形如0或者0 2 3;比如coco128.yaml中person是第一个类别,classes指定“0”,则表示只检测图片中的person;
- agnostic-nms:跨类别nms,进行nms是否也去除不同类别之间的框,默认False;比如待检测图像中有一个长得很像排球的足球,pt文件的分类中有足球和排球两种,那在识别时这个足球可能会被同时框上2个框:一个是足球,一个是排球。开启agnostic-nms后,那只会框出一个框;
- augment:推理的时候进行多尺度,翻转等操作(TTA)推理数据增强操作
- visualize:是否可视化特征图。 如果开启了这和参数可以看到exp文件夹下又多了一些文件,这里.npy格式的文件就是保存的模型文件,可以使用numpy读写。还有一些png文件。
- update:如果指定这个参数,则对所有模型进行strip_optimizer操作,去除pt文件中的优化器等信息
- project:预测结果保存的路径
- name:预测结果保存文件夹名
- exist-ok:每次预测模型的结果是否保存在原来的文件夹;如果指定了这个参数的话,那么本次预测的结果还是保存在上一次保存的文件夹里;如果不指定就是每次预测结果保存一个新的文件夹下
- line-thickness:调节预测框线条粗细的,
default=3;有的时候目标重叠太多会产生遮挡,比如python detect.py --line-thickness 10;
- hide-labels:隐藏预测图片上的标签(只有预测框)
- hide-conf:隐藏置信度(还有预测框和类别信息,但是没有置信度)
- half:是否使用 FP16 半精度推理。 在training阶段,梯度的更新往往是很微小的,需要相对较高的精度,一般要用到FP32以上。在inference的时候,精度要求没有那么高,一般F16(半精度)就可以,甚至可以用INT8(8位整型),精度影响不会很大。同时低精度的模型占用空间更小了,有利于部署在嵌入式模型里面。
- dnn:是否使用 OpenCV DNN 进行 ONNX 推理。
补充:验证参数(
val.py
)
- task:可以是train, val, test。比如:python val.py --task test表示打印测试集指标
- augment:测试是否使用TTA Test Time Augment,指定这个参数后各项指标会明显提升几个点。
- verbose:是否打印出每个类别的mAP,默认False。
- save-hybrid:将标签+预测混合结果保存到 .txt
- save-json:是否按照coco的json格式保存预测框,并且使用cocoapi做评估(需要同样coco的json格式的标签) 默认False
- half:是否使用半精度推理 默认False 其余和
detect.py一样。
版权归原作者 我宿孤栈 所有, 如有侵权,请联系我们删除。