基于大数据的股票数据可视化分析与预测系统
本项目基于 Python 利用网络爬虫技术从某财经网站采集上证指数、创业板指数等大盘指数数据,以及个股数据,同时抓取股票公司的简介、财务指标和机构预测等数据,并进行 KDJ、BOLL等技术指标的计算,构建股票数据分析系统,前端利用echarts进行可视化。基于深度学习算法实现股票价格预测,为投资提供
TensorFlow简单使用(基础篇)
目录一、TensorFlow的数据类型二、如何创建一个张量三、常用函数1.强制转换、最大值、最小值2.平均值、求和3.标记为可训练4.四则运算5.平方、次方与开方6.矩阵相乘7.输入特征和标签配对8.求出张量的梯度9.枚举函数10.独热编码11.概率转换函数12.自更新函数13.最大值索引函数我们为
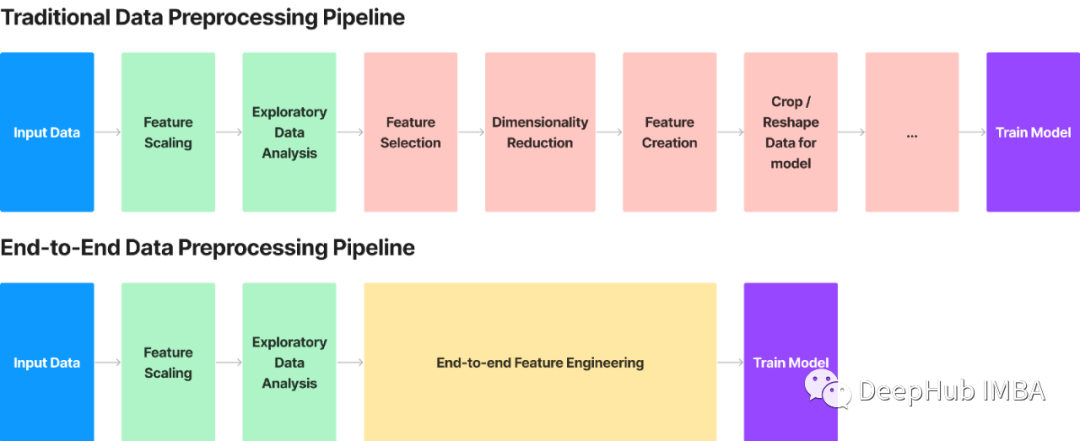
端到端的特征转换示例:使用三元组损失和 CNN 进行特征提取和转换
通过卷积和三元组损失学习数据的表示,并提出了一种端到端的特征转换方法,这种使用无监督卷积的方法简化并应用于各种数据。
10大机器视觉和AI模型库
AI社区慷慨地分享代码、模型架构,甚至在大型数据集上预训练好的模型。我们站在巨人的肩膀上,这就是为什么行业会如此广泛地采用人工智能的原因。当我们开始一个计算机视觉项目时,我们首先找到能部分解决我们问题的模型。假设想要构建一个安防应用,该应用主要是检测规定区域的行人。首先,检查是否存在公开可用的行人检
AI实现艺术品自动生成?太牛了
什么是AI艺术家?本文介绍了AI艺术家的基本原理以及使用流程,为艺术创作带来新的概念,希望能得到大家的鼓励支持!
大数据概论第二章理论基础
目录数据科学的学科地位统计学统计学与数据科学数据科学中常用的统计学知识数据科学视角下的统计学机器学习机器学习与数据库数据科学中常用的机器学习知识数据科学视角下的机器学习数据可视化数据科学的学科地位从学科定位上看,数据科学处于三大领域交叠之处,如下维恩图所示:从DrewConway的《数据科学维恩图》
机器学习决策树作业
机器学习决策树作业作业1:用独热编码表达天气数据集,并画出决策树。作业2:对于以下数据集,实际值和预测值:data = {‘y_Actual’: [‘Yes’, ‘No’, ‘No’, ‘Yes’, ‘No’, ##‘Yes’, ‘No’, ‘No’, ‘Yes’, ‘No’, ‘Yes’
R语言使用tidyr包的pivot_longer函数将dataframe数据从宽表变换为长表
R语言使用tidyr包的pivot_longer函数将dataframe数据从宽表变换为长表
R语言使用dplyr包的select函数和filter函数进行行数据筛选(row selection)
R语言使用dplyr包的select函数和filter函数进行行数据筛选(row selection)

GAN能进行股票预测吗?
在过去的研究中,出现了而很多的方式,但这些方式和方法并不是很成功,所以本文将这个领域的研究扩展到GANs。看看GANs这个领域是否能够进行预测。
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow第2版》-学习笔记(8):降维
· Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition, by Aurélien Géron (O’Reilly). Copyright 2019 Aurélien Géron, 978-1-
图片、视频超分模型RealBasicVSR安装使用 | 机器学习
一个好用的超分模型推荐——RealBasicVSR
机器学习系列8 基于Python构建Web应用以使用机器学习模型
👽👽👽在本文中,我将带你使用Python的Flask框架与Pickle模块构建了Web应用程序,在UFO目击数据集上构建了逻辑回归多分类模型,并将其集成在Web程序中。🏆🏆🏆

统计学小抄:常用术语和基本概念小结
统计学是涉及数据的收集,组织,分析,解释和呈现的学科。

Pycaret 3.0的RC版本已经发布了,什么重大的改进呢?
Pycaret是Python中的一个开源可自动化机器学习工作流程的低代码机学习库。 它是一种端到端的机器学习和模型管理工具。要了解有关Pycaret的更多信息,可以查看官方网站或GitHub。
python机器学习从入门到高级:超参数调整(含详细代码)
Python机器学习🌸个人主页:JoJo的数据分析历险记📝个人介绍:小编大四统计在读,目前保研到统计学top3高校继续攻读统计研究生💌如果文章对你有帮助,欢迎✌关注、👍点赞、✌收藏、👍订阅专栏在我们选择好一个模型后,接下来要做的是如何提高模型的精度。因此需要进行超参数调整,一种方法是手动处
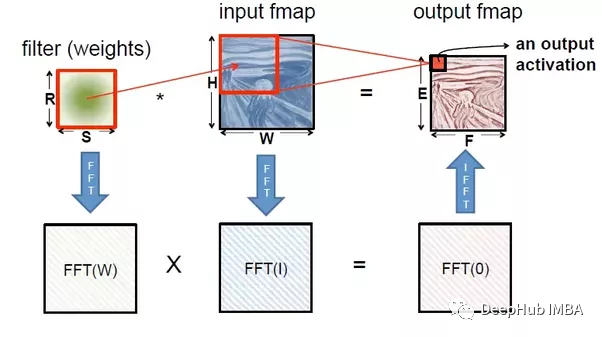
神经网络与傅立叶变换有关系吗?
傅里叶变换可以视为一种有助于逼近其他函数的函数,神经网络被也认为是一种函数逼近技术或通用函数逼近技术。 本文将讨论傅里叶变换,以及如何将其用于深度学习领域。
Python机器学习从入门到高级:模型评估和选择(含详细代码)
之前我们介绍了机器学习的一些基础性工作,介绍了如何对数据进行预处理,接下来我们可以根据这些数据以及我们的研究目标建立模型。那么如何选择合适的模型呢?首先需要对这些模型的效果进行评估。本文介绍如何使用`sklearn`代码进行模型评估
【人工智能】话说人工智能与人工神经网络的历程
人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。那么,它的发展历程是经历了什么过程呢?



