pandas将多个Series对象合并起来形成dataframe、当索引不一致时会产生缺失值NaN
pandas将多个Series对象合并起来形成dataframe、当索引不一致时会产生缺失值NaN

Pandas 中最常用的 7 个时间戳处理函数
数据科学和机器学习中时间序列分析的有用概念
三、深度学习基础2(前、反向传播;超参数)
前向传播与反向传播前向传播反向传播神经网络的输出、卷积神经网络输出值以及Pooling 层输出值(主要作用是下采样)过程皆为比较简单的基础知识,在此不作详细赘述。超参数超参数:比如算法中的 learning rate (学习率)、iterations(梯度下降法循环的数量)、(隐藏层数目)、(隐藏层
机器学习实战 -朴素贝叶斯
贝叶斯分类算法是统计学的一种概率分类方法,朴素贝叶斯分类是贝叶斯分类中最简单的一种。所以称之为”朴素”,是因为贝叶斯分类只做最原始、最简单的假设:所有的特征之间是统计独立的。
【Spark】(task6)Spark RDD完成统计逻辑
文章目录一、Spark RDD二、使用RDD functions完成任务2的统计逻辑Reference一、Spark RDDRDD:resilient distributed dataset (RDD)每个spark程序都有一个driver program运行main函数,在cluster集群上执行
三、深度学习基础1(构成、模型)
神经网络组成(输入层、隐藏层、输出层)最简单的神经网络:感知机复杂一些的感知机由简单的感知机单元组合而成:Sigmoid 单元感知机单元的输出只有 0 和 1,实际情况中,更多的输出类别不止 0 和 1,而是[0,1]上的概率值,这时候就需要 sigmoid 函数把任意实数映射到[0,1]上。sig
学习笔记:深度学习(5)——词向量的相关概念
开始学习Bert。

常见的8个概率分布公式和可视化
在本文中,我们将介绍一些常见的分布并通过Python 代码进行可视化以直观地显示它们。
集成学习-装袋法和提升法
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通 过在数据上构建多个模型,集成所有模型的建模结果。目录前言一、集成学习是什么?二、装袋法Bagging1.随机森林-代表集成学习技术水平的算法(有放回的抽样bagging)1.1 简介

5篇关于将强化学习与马尔可夫决策过程结合使用的论文推荐
低光图像增强、离线强化学习、基于深度强化学习的二元分类决策森林的构建方法等最新的研究成果
二、机器学习基础11(点估计)
点估计:用实际样本的一个指标来估计总体的一个指标的一种估计方法。点估计举例:比如说,我们想要了解中国人的平均身高,那么在大街上随便找了一个人,通过测量这个人的身高来估计中国人的平均身高水平;或者在淘宝上买东西的时候随便一次买到假货就说淘宝上都是假货等;这些都属于点估计。点估计主要思想:在样本数据中得
机器学习系列5 利用Scikit-learn构建回归模型:准备和可视化数据(保姆级教程)
在本文中,我们以美国南瓜数据为例,观察并整理了需要的数据,挑选及提取了特征变量:如月份,平均价格。并对其进行了数据可视化,我们发现,9月和10月份是南瓜的平均价格最高。

检测和处理异常值的极简指南
本文是关于检测和处理数据集中的异常值
数据科学 机器学习系列4 使用Python创建Scikit-Learn回归模型
机器学习系列4 使用Python和Scikit-Learn回归模型 在本文中,我们将学习机器学习本地环境的配置过程,利用Scikit-learn库走完机器学习模型的基本流程,最终创建一个线性回归模型。
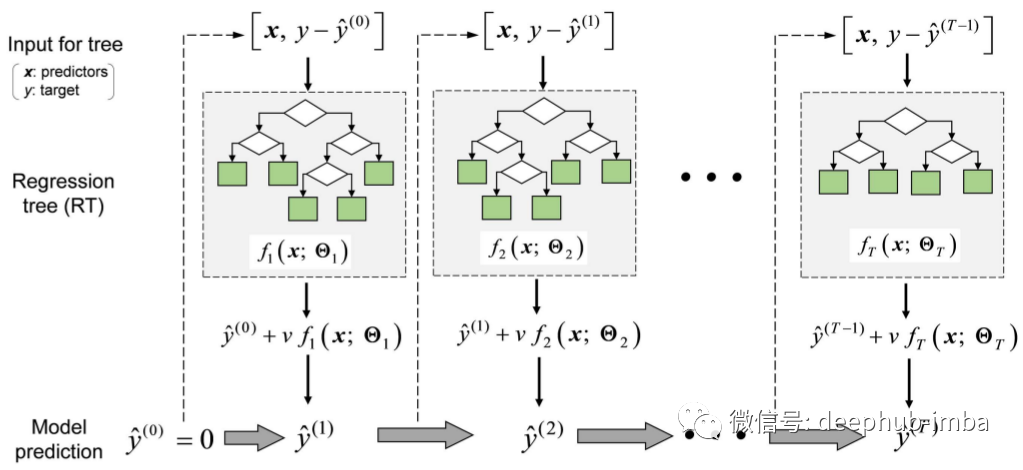
基于梯度提升(Boosting )的回归树简介
Boosting 是一种松散的策略,它将多个简单模型组合成一个复合模型。这个想法的理论来自于随着我们引入更多的简单模型,整个模型会变得越来越强大。
机器学习实战 - 决策树
机器学习实战 - 决策树总结
机器学习——CART决策树——泰坦尼克还生还预测
Scikit-learn库中实现的决策树的算法是优化的CART算法。分类决策树的类是DecisionTreeClassifier。
数据科学 机器学习系列3 机器学习的流程
在本文中,你将学习到:1机器学习的流程。2 理解基本术语概念,如“模型”,“训练”,“预测”,“过拟合”等。
《机器学习实战:基于Scikit-Learn、Keras和TensorFlow第2版》-学习笔记(4):训练模型
第四章 训练模型· Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow, 2nd Edition, by Aurélien Géron (O’Reilly). Copyright 2019 Aurélien Géron
二、机器学习基础5(损失函数、梯度下降)
损失函数损失函数(Loss function)又叫做误差函数,用来衡量算法的运行情况.估量模型的预测值 f (x)与真实值 Y 的不一致程度,是一个非负实值函数,通常使用来表示,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数重要组成部分。常见的损失函数损失函数用



