机器学习——从0开始构建自己的深度学习网络
机器学习——从0开始构建自己的深度学习网络
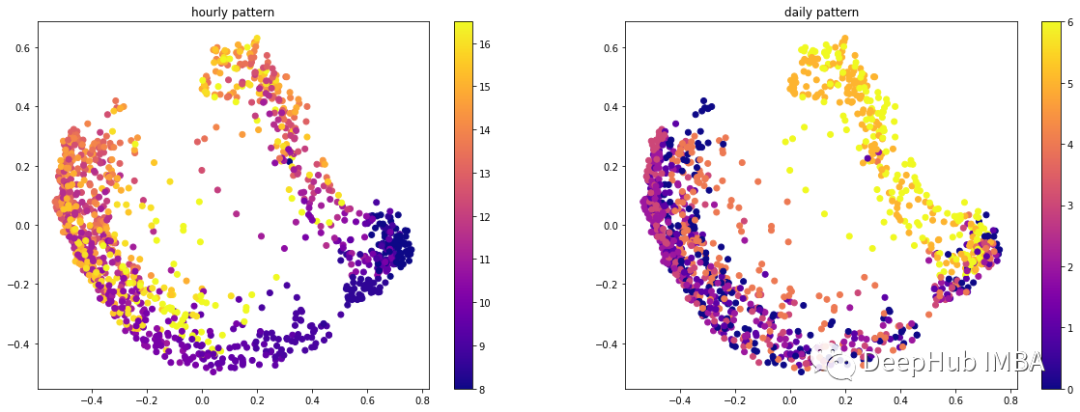
在时间序列中使用Word2Vec学习有意义的时间序列嵌入表示
在这篇文章中,介绍了众所周知的 Word2Vec 算法的推广,用于学习有价值的向量表示。我们在时间序列上下文中应用 Word2Vec,并展示了这种技术在非标准 NLP 应用程序中的有效性。整个过程可以很容易地集成到任何地方,并且很容易用于迁移学习任务。
机器学习入门-一元线性回归模型的骚操作
🐸文章适合于所有的相关人士进行学习🐸🐶各位看官看完了之后不要立刻转身呀🐶🐼期待三连关注小小博主加收藏🐼🐤小小博主回关快 会给你意想不到的惊喜呀🐤文章目录🚩前言🚩一元线性回归模型讲解☁️我们可能会遭遇的问题☁️线性回归模型🚩数学公式推导☁️公式推导☁️代码介绍及实现🌊jupyt
520不要老想着谈恋爱要变的更加爱强化学习
快速了解强化学习
home credit default risk(捷信违约风险)机器学习模型复现(论文_毕业设计_作业)
home credit default risk(捷信违约风险)机器学习模型复现(论文_毕业设计_作业)
基于LSTM的时空序列预测任务文章总结
时空序列预测任务,LSTM单元结构
李宏毅老师《机器学习》课程笔记-3卷积神经网络
介绍了深度学习在图像识别领域的应用—卷积神经网络。
机器学习系列(14)_PCA对图像数据集的降维_03
文章目录一、噪音过滤1、案例:手写数字图像识别一、噪音过滤降维的目的之一是希望抛弃对模型带来负面影响的特征,同时,带有效信息的特征的方差应该是远大于噪音的,所以相比噪音,有效的特征所带来的信息不会在PCA当中大量抛弃。inverse_transform能够在不恢复原始数据的情况下,将降维后的数据返回
数学建模学习(69):朴素贝叶斯回归分类,轻松掌握
手把手教你使用贝叶斯回归分类模型
正则化——参数范数惩罚
L1和L2正则化
神经网络入门(详细 )
机器学习流程、K近邻算法,以及详细介绍了神经网络的基本框架。
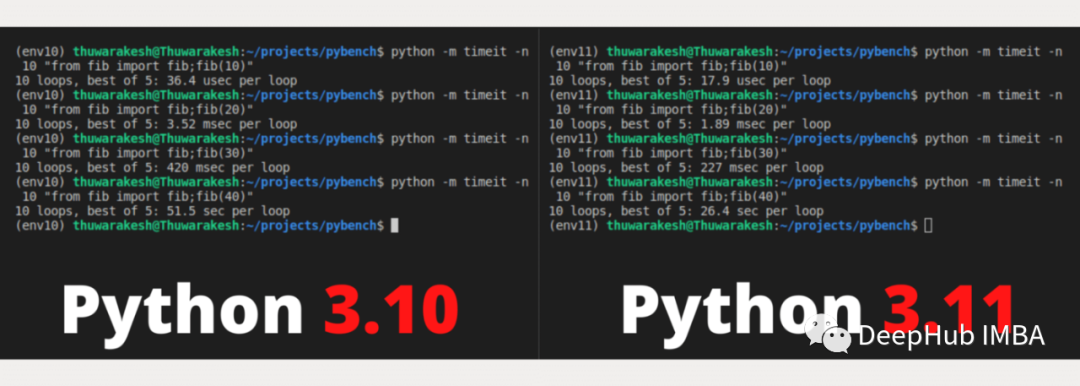
Python 3.11比3.10 快60%:使用冒泡排序和递归函数对比测试
Python 3.11中特意强调了优化,我们可以实际验证下到底有没有官方说的平均1.25倍的提升呢?
机器学习作业(第十八次课堂作业)
机器学习作业(第十八次课堂作业)
机器学习——k近邻(KNN算法)工作原理、代码实现详解
机器学习——k近邻(KNN算法)工作原理、欧式距离、代码实现详解
计算机视觉系列(二)——迁移学习
目录一、迁移学习与微调二、如何寻找预训练的模型?三、初始化模型四、将 ResNet 迁移到 CIFAR-10 上一、迁移学习与微调ImageNet 数据集大约有 120w 个样本,类别数为 1000;MNIST 数据集只有 6w 个样本,类别数为 10。然而,我们平常接触到的数据集的规模通常在这两者
概率还不会的快看过来《统计学习方法》——第四章、朴素贝叶斯法
作者简介:整个建筑最重要的是地基,地基不稳,地动山摇。而学技术更要扎稳基础,关注我,带你稳扎每一板块邻域的基础。博客主页:啊四战斗霸的博客专栏:《统计学习方法》第二版——个人笔记创作不易,走过路过别忘了三连击了哟!!!关注作者,不仅幸运爆棚,未来更可期!!!***有代码,就有注释!!!Triple
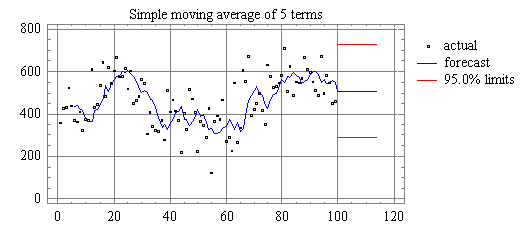
一个简单实例解析移动平均模型 Moving-Average Models
本文将使用简单的说明性示例来解释移动平均模型(Arima [p,q]中的MA [Q])。
【注意力机制集锦2】BAM&SGE&DAN原文、结构、源码详解
视觉注意力机制领域BAM及DAN的原文、结构、源码解读
时间序列统计特征的详细解析
根据对已有时间序列比赛的统计研究,发现数据规模不大的比赛任务中,依然使用的是特征工程+梯度提升树模型。而且特征工程依然是重中之重。所以特意换了一些时间对特征工程进行了详细的总结。主要包括两大类,一类是常用的(大家都使用的)基本特征,还有一类是Top选手使用的高级特征。为了方便比赛选手学习,将其概念
大数据与人工智能协会 机器学习小组 测试试题纠错
文章目录前言激活函数:激活函数的作用:常用的激活函数:随机梯度下降:批梯度下降:总结前言经过一段时间的学习,初步了解了机器学习的一些东西,但是在这次测试中仍旧可以看出自己在这方面的了解还只是了解,以下是我在这次测试之后对测试题的纠错和相关的一系列知识。1.写出你所知道的激活函数,写出其表达式以及图像



