

数据可视化基本上是数据的图形表示。在探索性数据分析中,可以使用数据可视化来理解变量之间的关系,还可以通过视化数据揭示底层结构或了解数据信息。
有多种工具可以帮助我们创建数据可视化。Seaborn就是其中之一 ,它是一个流行的 Python 数据可视化库。虽然Seaborn也是基于 Matplotlib ,但是与其他流行的数据可视化库相比,Seaborn 的语法更简单需要的代码更少。
只需一行 Seaborn 代码,我们就能够创建最常用的绘图并对其进行自定义,这是我们将在本文中重点介绍的内容。本文中将使用 Seaborn 的来创建以下绘图:
- 散点图
- 折线图
- 直方图
- 箱形图
但是,我们将介绍的功能不仅限于这些图,还可以用于创建其他几种图,例如 kde 图、条形图和小提琴图。
Seaborn 有一些内置的数据集,可以使用 load_dataset 函数访问。本文将使用penguins和taxis数据集进行演示。
# importing libraries
import pandas as pd
import seaborn as sns
sns.set(style="darkgrid")
# reading the datasets
penguins = sns.load_dataset(name="penguins")
taxis = sns.load_dataset(name="taxis")
散点图
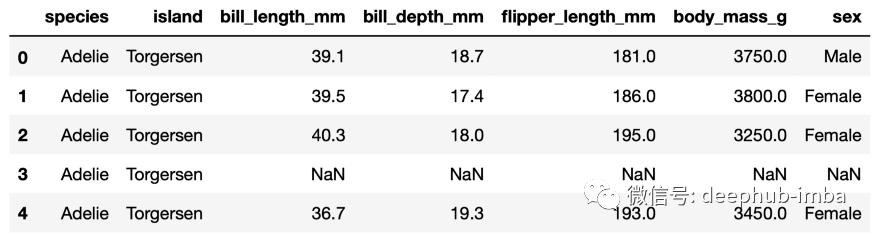
penguins.head()
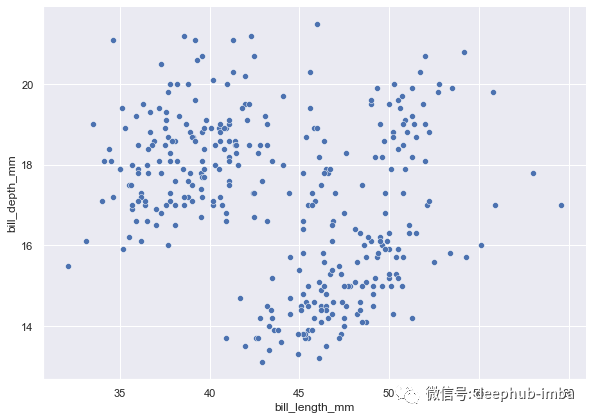
relplot 是最常用的一个函数。可以创建散点图和折线图,因为两种绘图类型主要用于研究变量之间的关系。
以下代码创建散点图。height 和 aspect 参数调整图形大小。
sns.relplot(data=penguins, x="bill_length_mm", y="bill_depth_mm",
kind="scatter", height=6, aspect=1.4)
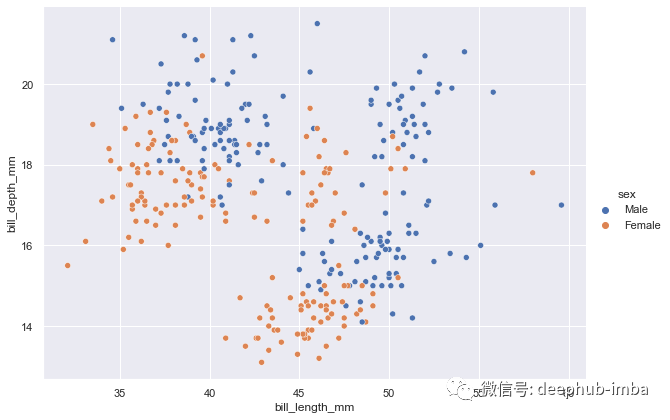
每个点代表一个数据点(即行)。我们可以使用 hue 参数通过以不同的颜色显示来区分不同的类别。这是一个将上图中的雌性和雄性企鹅分开的示例。
sns.relplot(data=df, x="bill_length_mm", y="bill_depth_mm",
hue="sex", kind="scatter", height=6, aspect=1.4)
折线图
折线图是另一种非常常用的关系图。它可以展示值如何随时间或连续测量而变化。
我们将创建一个折线图来可视化每日乘客数量,该数量可以使用 Pandas 的 groupby 函数从出租车数据集中计算出来。为了让事情变得更有趣,我们还分别计算不同支付方式的总数。
taxis["date"] = taxis["pickup"].astype("datetime64[ns]").dt.date
taxis_daily = taxis.groupby(["date","payment"], as_index=False).agg(
total_passengers = ("passengers","sum"),
total_amount = ("total","sum")
)
taxis_daily.head()

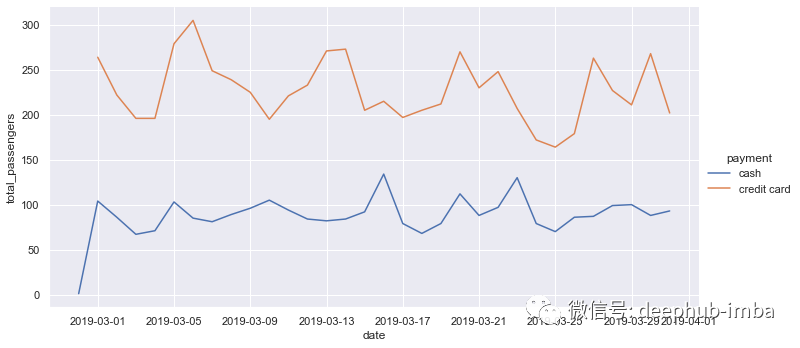
以下代码行创建了一个显示每日总乘客人数的折线图。
sns.relplot(data=taxis_daily, x="date", y="total_passengers",
hue="payment", kind="line", height=5, aspect=2)
直方图
直方图用于可视化连续变量的数据分布。它们将值范围划分为离散的 bin,并显示每个 bin 中的数据点数(即行)。
对于前面的示例,计算每日乘客人数和总量创建总金额的直方图,如下所示:
sns.displot(data=taxis_daily, x="total_amount", kind="hist",
height=5, aspect=1.5, bins=12)
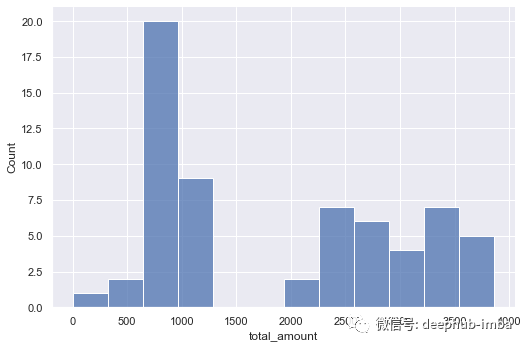
displot 函数可以用于创建直方图, kde图 和 ecdf 图。bins 参数控制直方图中的 bin 数量。
这个直方图告诉我们的是,花费的总金额通常在 1000 左右。条的高度与它们所代表的范围内的值的数量成正比。
箱形图
箱线图是一个分类分布图,显示变量在中位数和四分位数方面的分布。Seaborn 的 catplot 函数可以创建箱形图。
sns.catplot(data=penguins, x="island", y="body_mass_g", kind="box",
height=5, aspect=1.5)

彩色框覆盖了第一个和第三个四分位数之间的范围,中间的线是中值。当所有值按升序排序时:
- 第一个四分位数是找到 25% 数据点的值。
- 中位数是中间的点。
- 第三个四分位数是找到 75% 数据点的值。
较高的箱线图表明这些值更加分散。
总结
Seaborn 使创建数据可视化变得非常容易。它们提供了清晰直观的语法。并且seaborn的函数语法基本相同。只需更改函数名称和 kind 参数,就可以只用一行代码创建许多不同的图。
作者:Soner Yıldırım