
温馨提示:获取源码可扫描文末博主 QQ 名片 :)
1. 项目简介
股票市场行情分析与预测是数据分析领域里面的重头戏,其符合大数据的四大特征:交易量大、频率高、数据种类多、价值高。
本项目基于 Python 利用网络爬虫技术从某财经网站采集上证指数、创业板指数等大盘指数数据,以及个股数据,同时抓取股票公司的简介、财务指标和机构预测等数据,并进行 KDJ、BOLL等技术指标的计算,构建股票数据分析系统,前端利用echarts进行可视化。基于深度学习算法实现股票价格预测,为投资提供可能的趋势分析。
2. 功能组成
基于大数据的股票数据可视化分析与预测系统的功能组成如下图所示:
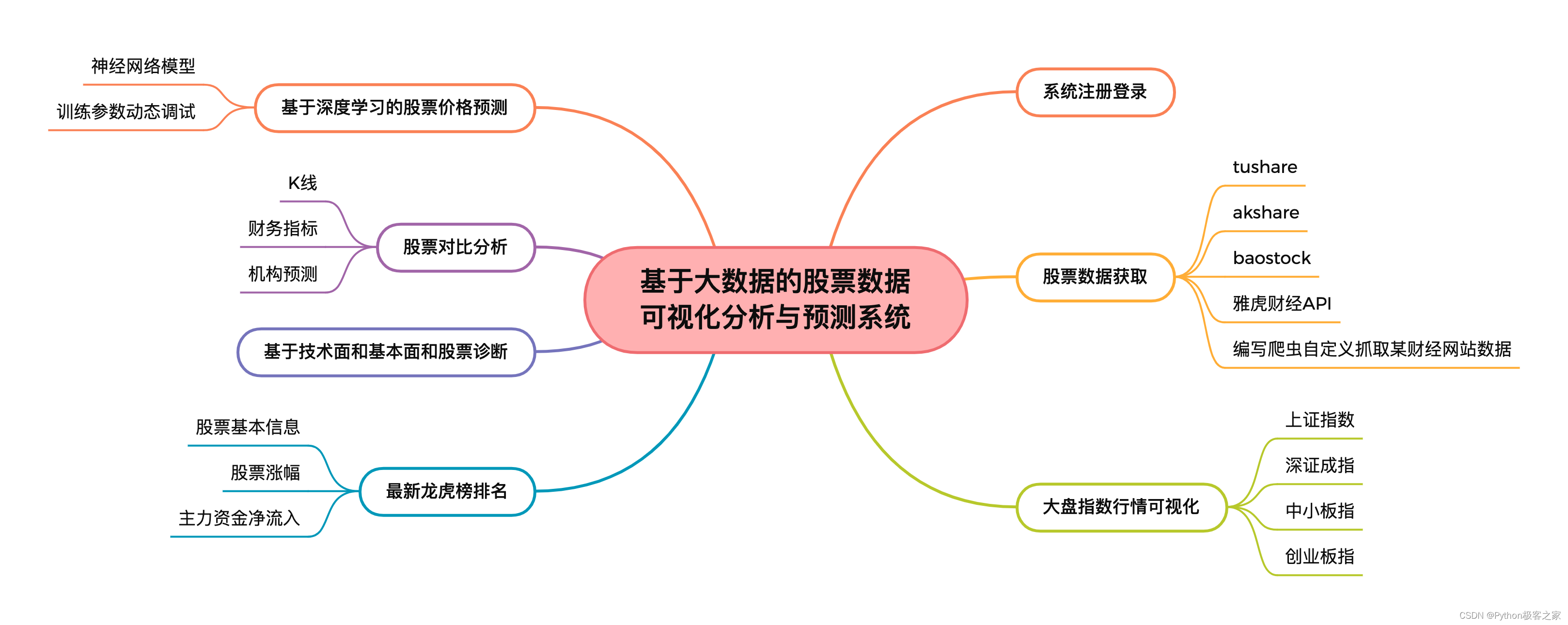
3. 股票数据获取
数据获取是股票数据分析的第一步,找不到可靠、真实的数据,量化分析就无从谈起。随着信息技术的不断发展,数据获取渠道也越来越多,当前包括开源的股票数据获取的工具:tushare、baostock、pandas_datareader和yahool等财经数据API,这样可以节省不少精力。当这些开源的API接口不能满足自己特定场景的股票数据需求的时候,我们可以从某些财经网站抓取所需的数据。以 tushare 为例:
获取所有股票列表:
print('爬取上市公司列表...')
stock_list_file = os.path.join(os.getcwd(), '../数据集', '股票列表', '{}.csv'.format(cur_date.strftime('%Y-%m-%d')))
# list_status: 上市状态: L上市 D退市 P暂停上市,默认L
# exchange: 交易所 SSE上交所 SZSE深交所 HKEX港交所(未上线)
stocks = pro.stock_basic(list_status='L', exchange='', fields='ts_code,symbol,name,area,industry,market,list_date,is_hs')
stocks.to_csv(stock_list_file, index=False, encoding='utf8')
print('done.')
获取所有股票的历史 K线数据:
# 爬取过去 300 天的数据
start_date = cur_date - timedelta(days=300)
# ----------- 爬取股票的历史数据 -----------
print('爬取股票的历史数据...')
for i, row in tqdm(stocks.iterrows(), total=stocks.shape[0]):
stock_name = row['name']
stock_code = row['ts_code']
stock_daily_file = os.path.join(os.getcwd(), '../数据集', '股票日线行情', '{}({}).csv'.format(stock_name, stock_code))
if os.path.exists(stock_daily_file):
stock_df = pd.read_csv(stock_daily_file, parse_dates=['trade_date'])
stock_df['trade_date'] = stock_df['trade_date'].map(lambda d: d.strftime('%Y%m%d'))
start_date_str = stock_df.iloc[0]['trade_date']
else:
stock_df = pd.DataFrame()
start_date_str = start_date.strftime('%Y%m%d')
new_stock_df = None
while True:
try:
new_stock_df = pro.daily(ts_code=stock_code, start_date=start_date_str, end_date=cur_date.strftime('%Y%m%d'))
except:
token_idx += 1
ts_token = get_ts_token(token_idx)
if ts_token:
ts.set_token(ts_token)
pro = ts.pro_api()
new_stock_df = pro.daily(ts_code=stock_code, start_date=start_date_str, end_date=cur_date.strftime('%Y-%m-%d'))
else:
time.sleep(61)
token_idx = 0
if new_stock_df is not None:
break
stock_df = pd.concat([new_stock_df, stock_df])
stock_df = stock_df.drop_duplicates(subset=['trade_date']).reset_index(drop=True)
stock_df.to_csv(stock_daily_file, index=False, encoding='utf8')
print('done.')
当开源工具不能满足需求时,如需要获取个股北向资金持仓排名的数据,需要编写爬虫:
def fetch_stock_north_bound_foreign_capital_rank(self):
"""
个股北向资金持仓排名,注意是上一个交易日的数据
"""
page = 1
page_size = 10000
HdDate = datetime.now().date()
while True:
url = f'某财经网站获取数据接口'
self.headers['Host'] = "xxx.xxxx.com"
self.headers['Referer'] = "http://xxx.xxxx.com/"
resp = requests.get(url, headers=self.headers)
resp.encoding = 'utf8'
stock_datas = json.loads(resp.text)['data']
if len(stock_datas) > 0:
break
HdDate = HdDate + timedelta(days=-1)
stock_df = pd.DataFrame(stock_datas)
rename_columns = {
"SCode": "股票代码",
"SName": "股票名称",
"HYName": "所属行业",
"HYCode": "行业代码",
"DQName": "所属地区",
"DQCode": "地区代码",
"ShareHold": "今日持股股数",
"ShareSZ": "今日持股市值",
"LTZB": "今日持股占流通股比",
"ZZB": "今日持股占总股本比",
"ShareHold_Chg_One": "今日增持股数",
"ShareSZ_Chg_One": "今日增持市值",
"LTZB_One": "今日增持占流通股比‰",
"ZZB_One": "今日增持占总股本比‰",
}
stock_df.rename(columns=rename_columns, inplace=True)
for col in rename_columns.values():
stock_df = stock_df[stock_df[col] != '-']
if col not in {'股票代码', '股票名称', '所属版块', '所属行业', '行业代码', '所属地区', '地区代码'}:
stock_df[col] = stock_df[col].astype(float)
drop_coumns = [f for f in stock_df.columns.tolist() if f not in set(rename_columns.values())]
stock_df.drop(drop_coumns, axis=1, inplace=True)
return HdDate, stock_df
4. 股票数据可视化分析与预测系统
4.1 系统注册登录
4.2 股票技术指标计算
获取的数据为股票的原始 K 线数据,包括 open、close、high、low、volume 等,基于这些数据我们可以计算股票的均线(MA)、布林线(BOLL)、KDJ 和 MACD 等常用技术指标,其计算方法如下:
def AVEDEV(seq: pd.Series, N):
"""
平均绝对偏差 mean absolute deviation
之前用mad的计算模式依然返回的是单值
"""
return seq.rolling(N).apply(lambda x: (np.abs(x - x.mean())).mean(), raw=True)
def MA(seq: pd.Series, N):
"""
普通均线指标
"""
return seq.rolling(N).mean()
def SMA(seq: pd.Series, N, M=1):
"""
威廉SMA算法
https://www.joinquant.com/post/867
"""
if not isinstance(seq, pd.Series):
seq = pd.Series(seq)
ret = []
i = 1
length = len(seq)
# 跳过X中前面几个 nan 值
while i < length:
if np.isnan(seq.iloc[i]):
i += 1
else:
break
preY = seq.iloc[i] # Y'
ret.append(preY)
while i < length:
Y = (M * seq.iloc[i] + (N - M) * preY) / float(N)
ret.append(Y)
preY = Y
i += 1
return pd.Series(ret, index=seq.tail(len(ret)).index)
def KDJ(data, N=3, M1=3, lower=20, upper=80):
# 假如是计算kdj(9,3,3),那么,N是9,M1是3,3
data['llv_low'] = data['low'].rolling(N).min()
data['hhv_high'] = data['high'].rolling(N).max()
data['rsv'] = (data['close'] - data['llv_low']) / (data['hhv_high'] - data['llv_low'])
data['k'] = data['rsv'].ewm(adjust=False, alpha=1 / M1).mean()
data['d'] = data['k'].ewm(adjust=False, alpha=1 / M1).mean()
data['j'] = 3 * data['k'] - 2 * data['d']
data['pre_j'] = data['j'].shift(1)
data['long_signal'] = np.where((data['pre_j'] < lower) & (data['j'] >= lower), 1, 0)
data['short_signal'] = np.where((data['pre_j'] > upper) & (data['j'] <= upper), -1, 0)
data['signal'] = data['long_signal'] + data['short_signal']
return {'k': data['k'].fillna(0).to_list(),
'd': data['d'].fillna(0).to_list(),
'j': data['j'].fillna(0).to_list()}
def EMA(seq: pd.Series, N):
return seq.ewm(span=N, min_periods=N - 1, adjust=True).mean()
def MACD(CLOSE, short=12, long=26, mid=9):
"""
MACD CALC
"""
DIF = EMA(CLOSE, short) - EMA(CLOSE, long)
DEA = EMA(DIF, mid)
MACD = (DIF - DEA) * 2
return {
'DIF': DIF.fillna(0).to_list(),
'DEA': DEA.fillna(0).to_list(),
'MACD': MACD.fillna(0).to_list()
}
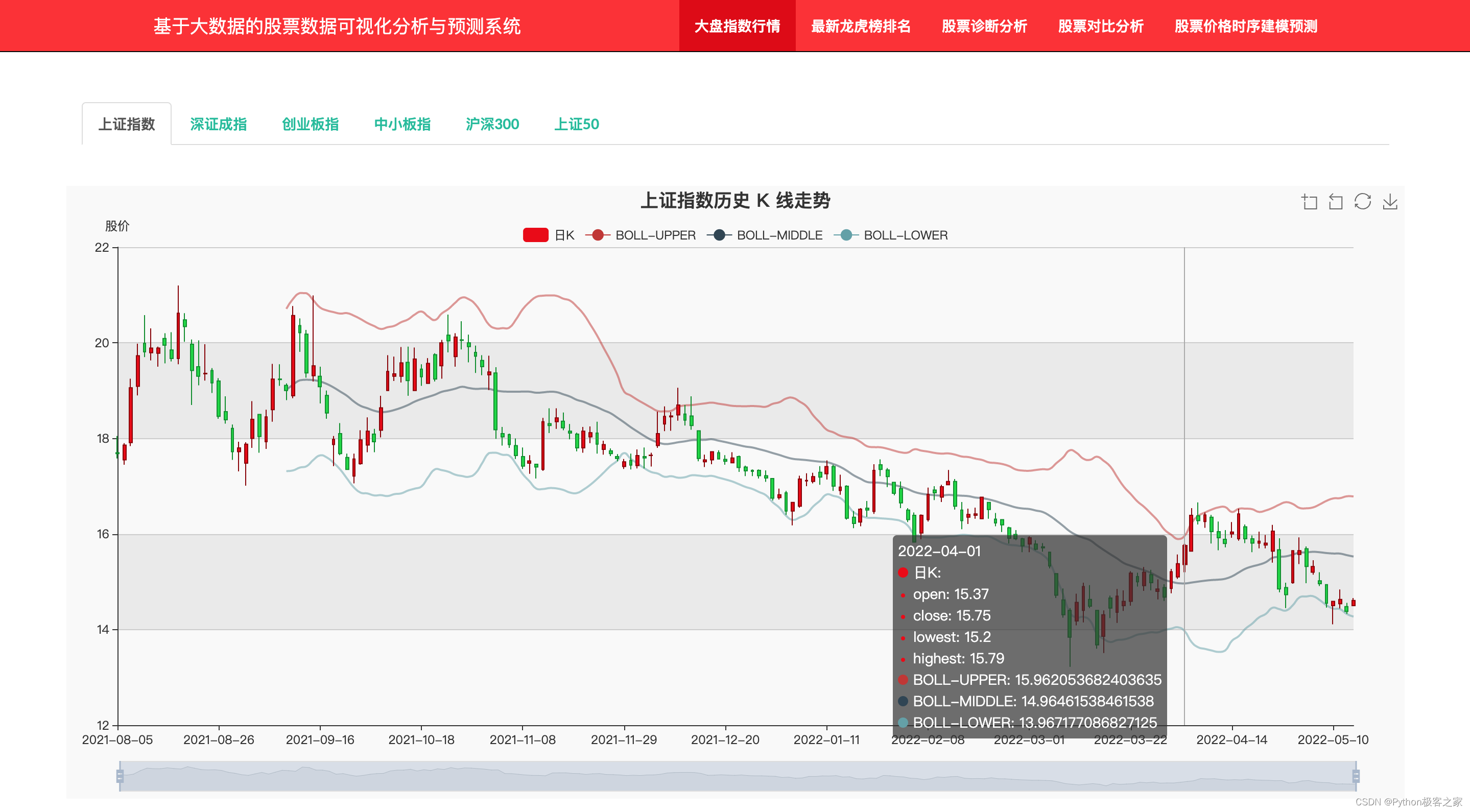
4.3 A股指数行情
指数主要包括上证指数、深证成指、创业板指、中小板指、沪深300、上证50等,通过点击指数的 tab 标签,实现该指数行情的 K线数据可视化展示,同时后端计算出 BOLL 指标,其效果如下:
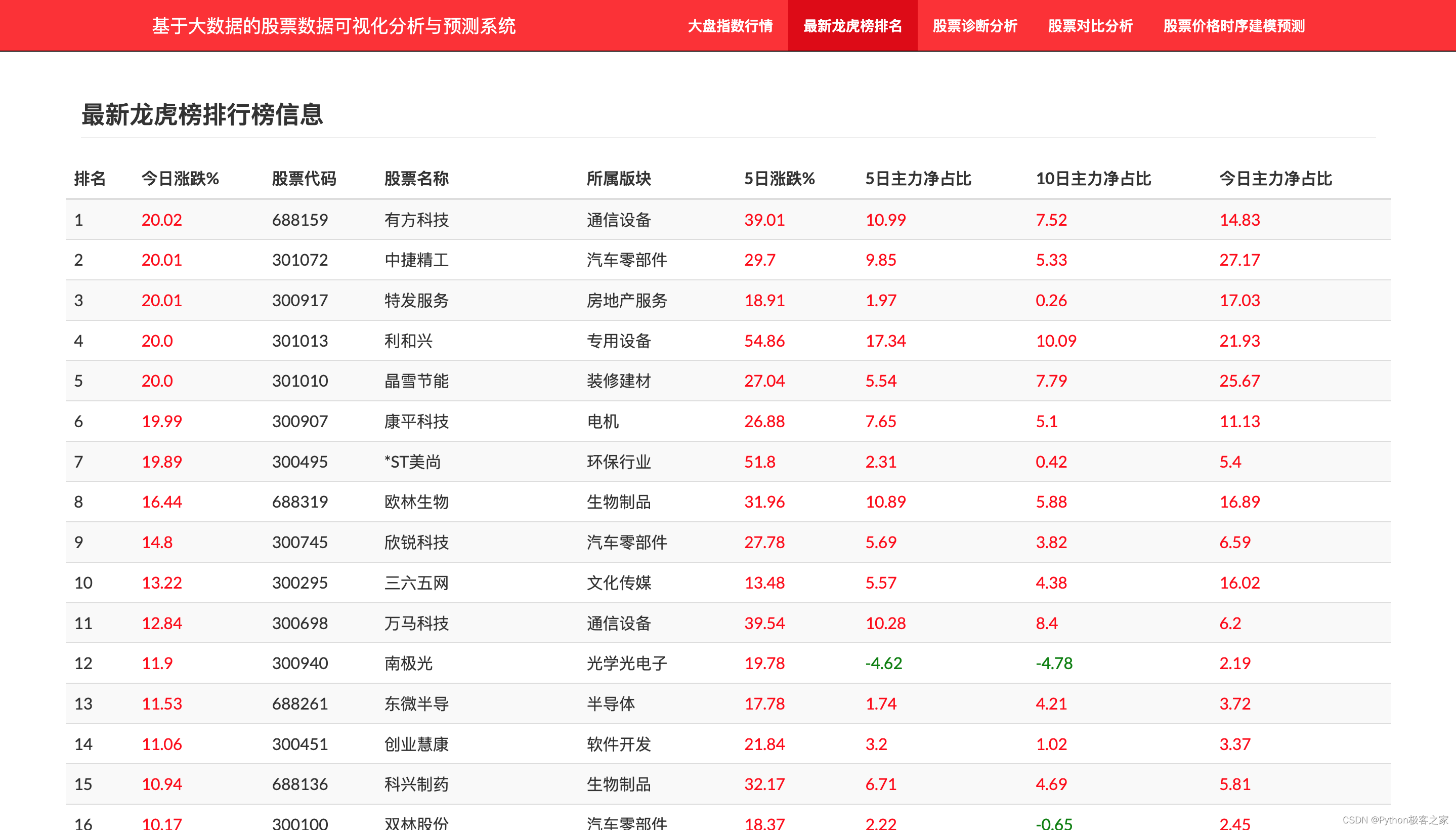
4.4 最新龙虎榜个股排名
利用爬虫获取某财经网站的最新龙虎榜数据,获取其股票代码、股票名称、所属版块、涨跌幅、主力资金净流入等信息。
4.5 个股诊断分析
个股的诊断主要围绕个股的基本面(公司简介)、资金面(各类财务指标)和技术面(各类技术指标)等来展开,同时提供自选列表功能,点击自选股列表个股快速诊断。也支持股票的模糊查询、代码查询等功能:
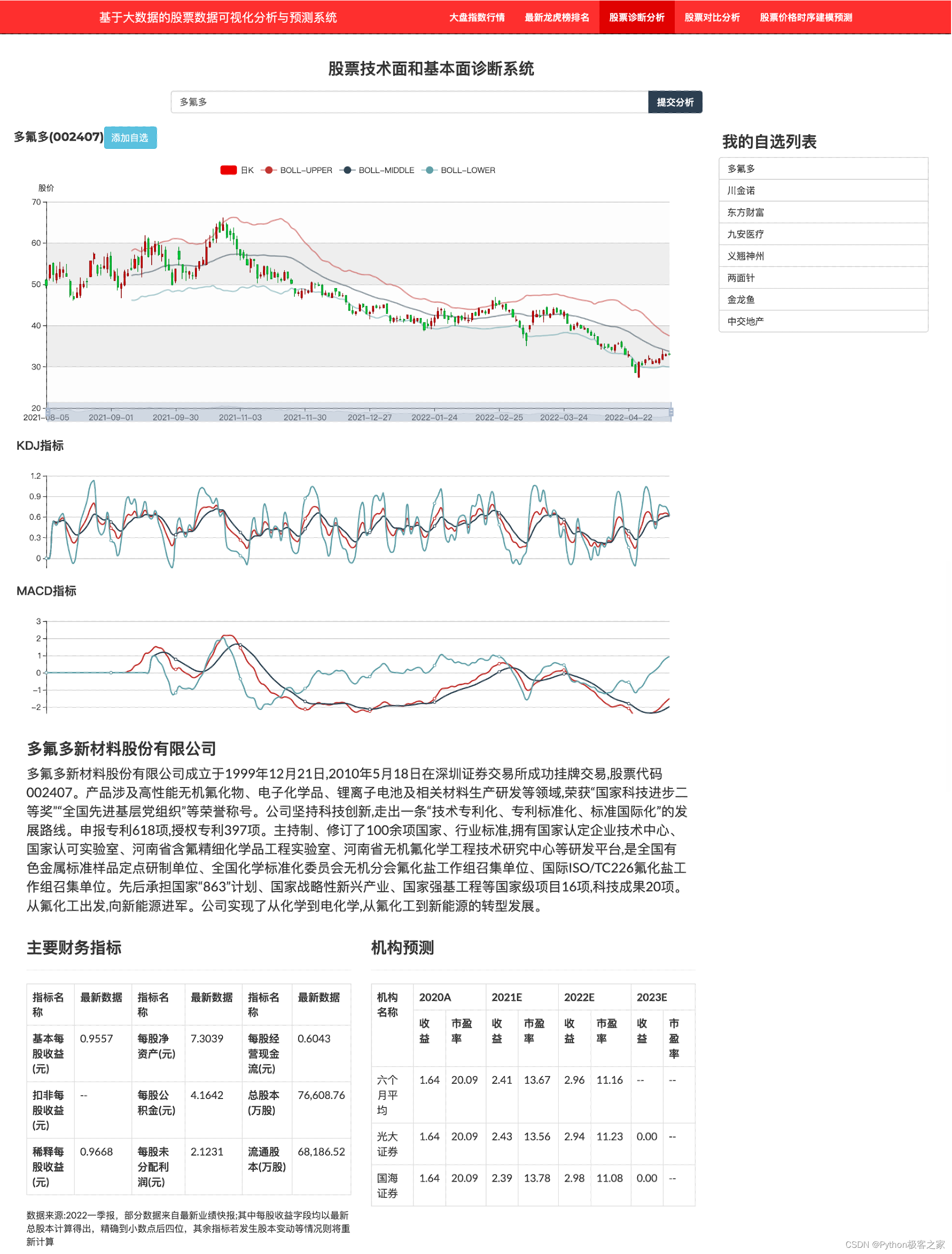
4.6 股票对比分析
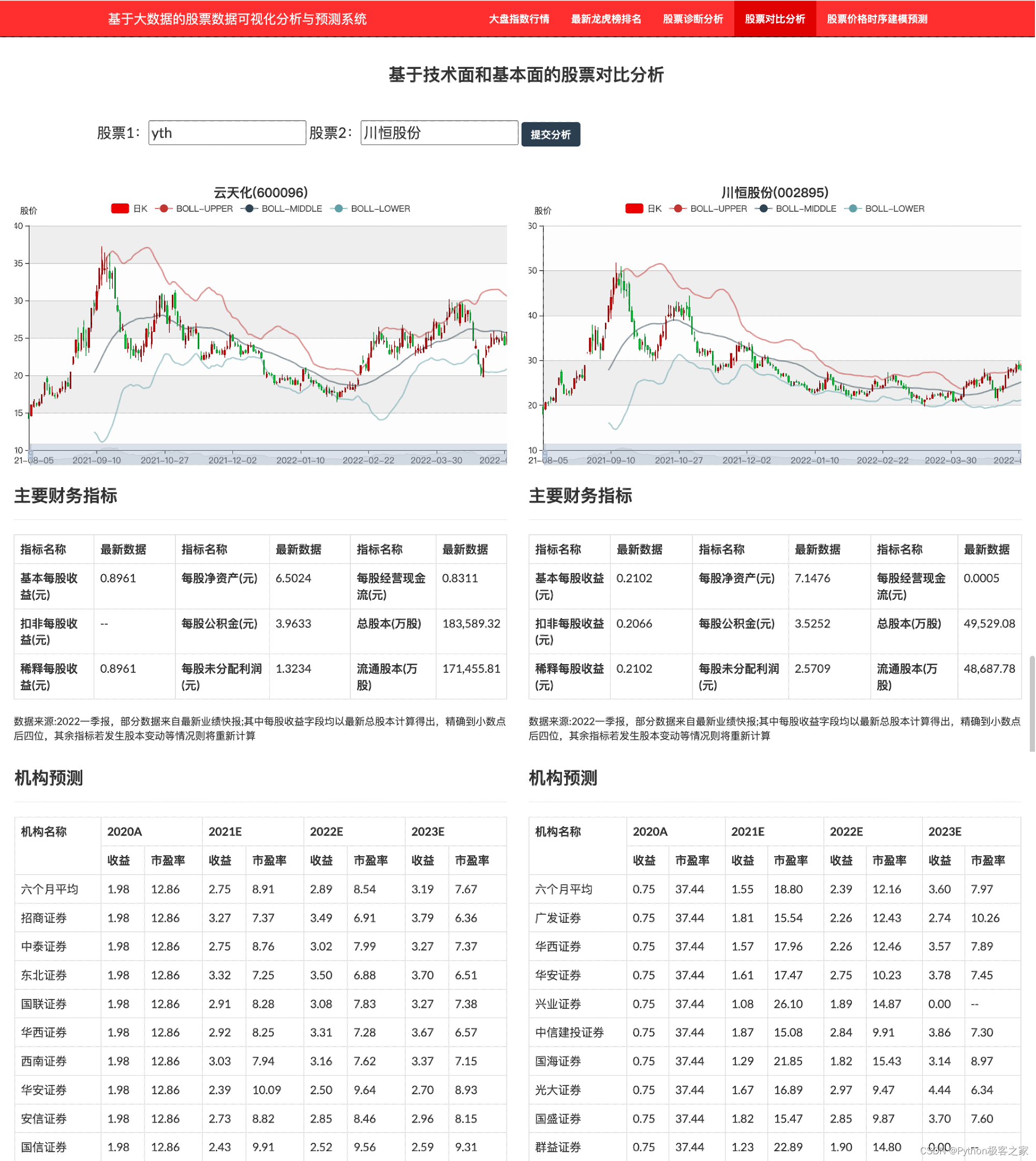
股票的对比分析主要围绕两只股票的技术指标、K先形态、财务状况以及机构预测盈利等信息,支持股票的模糊查询、代码查询等功能:
4.7 基于神经网络的股票价格预测
个股的历史行情数据为典型的时序数据,本项目采用循环神经网络实现股票价格的预测,通过调整时间窗口、训练的次数等参数,测试模型预测的效果: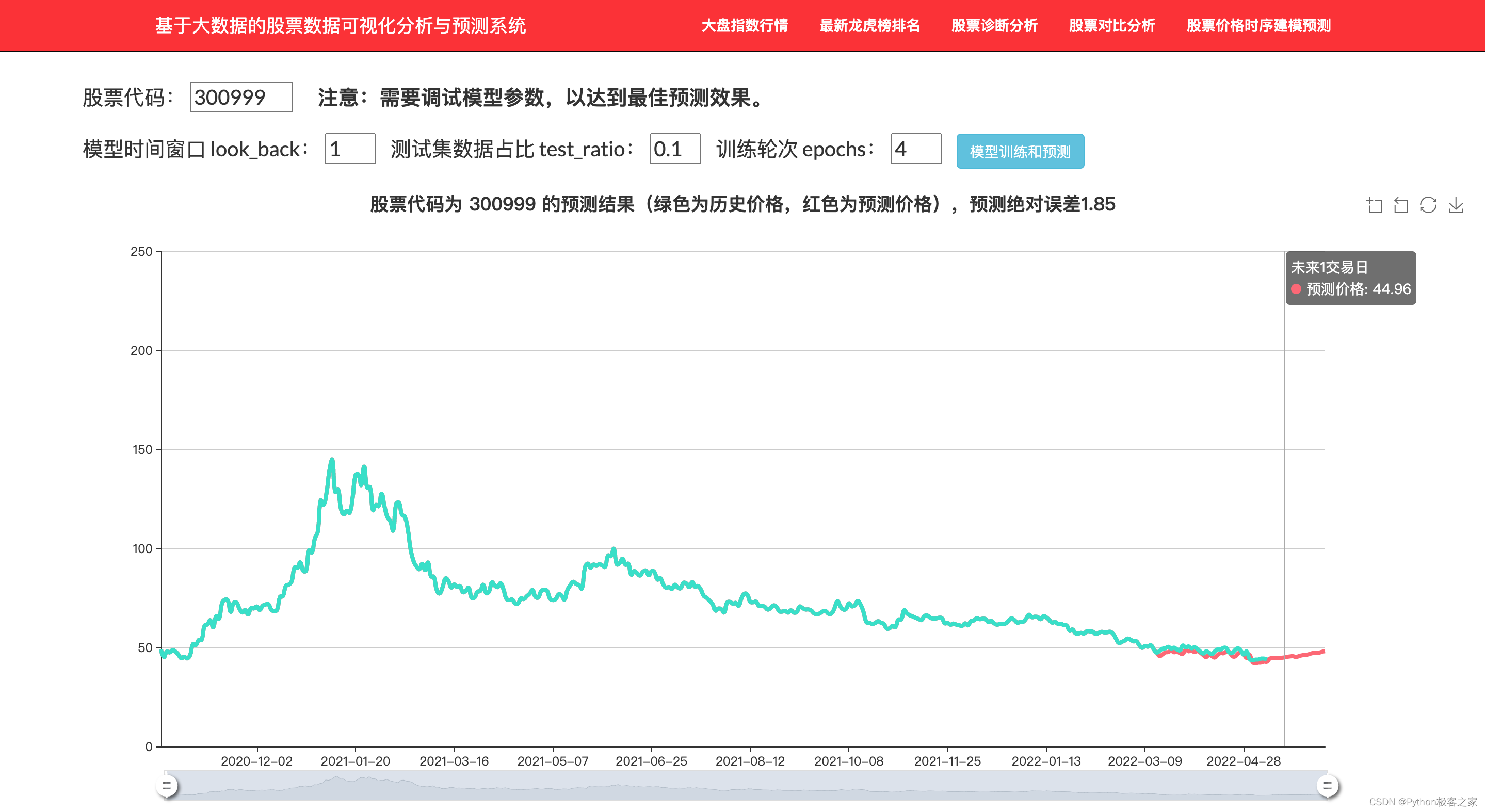
5. 总结
本项目利用 python 获取股票行情数据,包括K线数据、财务指标、机构预测、公司简介、资金流入等数据,并计算 MA、EMA、BOLL、KDJ 和 MACD 等技术指标,基于此实现股票的诊断、对比分析等功能,并利用循环神经网络实现对个股的未来趋势进行预测,为投资提供一定的参考。
由于篇幅有限,源码获取请扫描下方作者 QQ 名片 :)

本文转载自: https://blog.csdn.net/andrew_extra/article/details/124700667
版权归原作者 Python极客之家 所有, 如有侵权,请联系我们删除。
版权归原作者 Python极客之家 所有, 如有侵权,请联系我们删除。