
文章目录
前言
经过一段时间的学习,初步了解了机器学习的一些东西,但是在这次测试中仍旧可以看出自己在这方面的了解还只是了解,以下是我在这次测试之后对测试题的纠错和相关的一系列知识。
机器学习方面
1.写出你所知道的激活函数,写出其表达式以及图像(6)
首先,得知道激活函数是什么,当时看到激活函数整个人都懵了。
激活函数:
在人工神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
激活函数的作用:
也就是说它主要起到了一个映射的作用,在没有引入激活函数之前,输入和输出都是线性组合,跟没有隐藏层的效果是一样的,网络不易收敛,学习能力有限,就比如原始的感知机一样。激活函数的使用相当于引入了非线性函数,使模型更易于收敛,神经网络的逼近能力就更加强大。
常用的激活函数:
常用的激活函数大概有三种,分别是sigmoid函数、tanh函数、Relu函数,它们都有各自的特点。
sigmoid函数
表达式: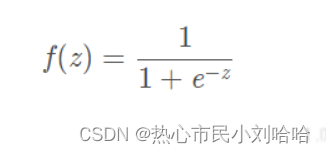
图像: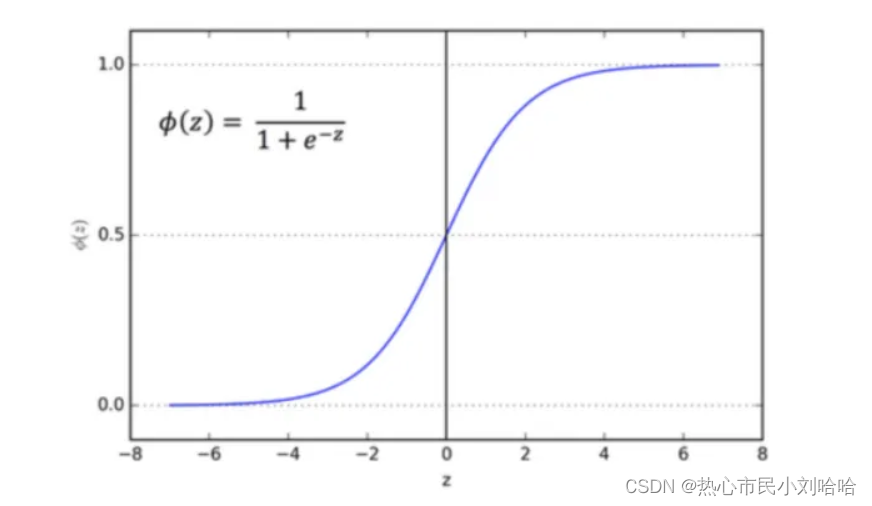 特点:它可以把输入的连续实值转换为0到1之间的数字并输出,有两条渐近线分别为0和1,但是函数中含有幂运算,对计算机求解比较耗时,且有可能在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,而且其输出不是零均值。
特点:它可以把输入的连续实值转换为0到1之间的数字并输出,有两条渐近线分别为0和1,但是函数中含有幂运算,对计算机求解比较耗时,且有可能在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失,而且其输出不是零均值。
tanh函数
表达式: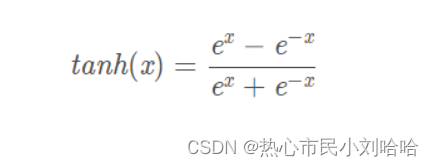
图像: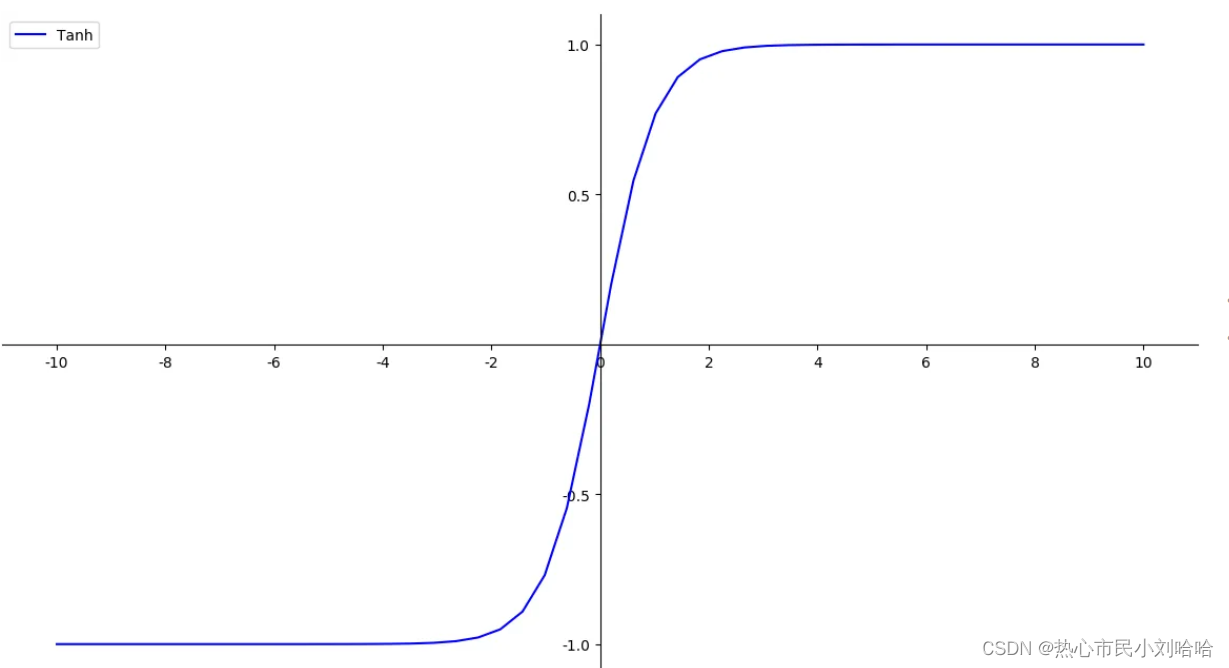 特点:sigmoid函数的输出不是零均值,而tanh函数解决了该问题,但是仍然含有幂运算,对计算机求解比较耗时,且有可能在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失。
特点:sigmoid函数的输出不是零均值,而tanh函数解决了该问题,但是仍然含有幂运算,对计算机求解比较耗时,且有可能在深度神经网络中梯度反向传递时导致梯度爆炸和梯度消失。
Relu函数:
表达式: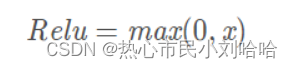
图像: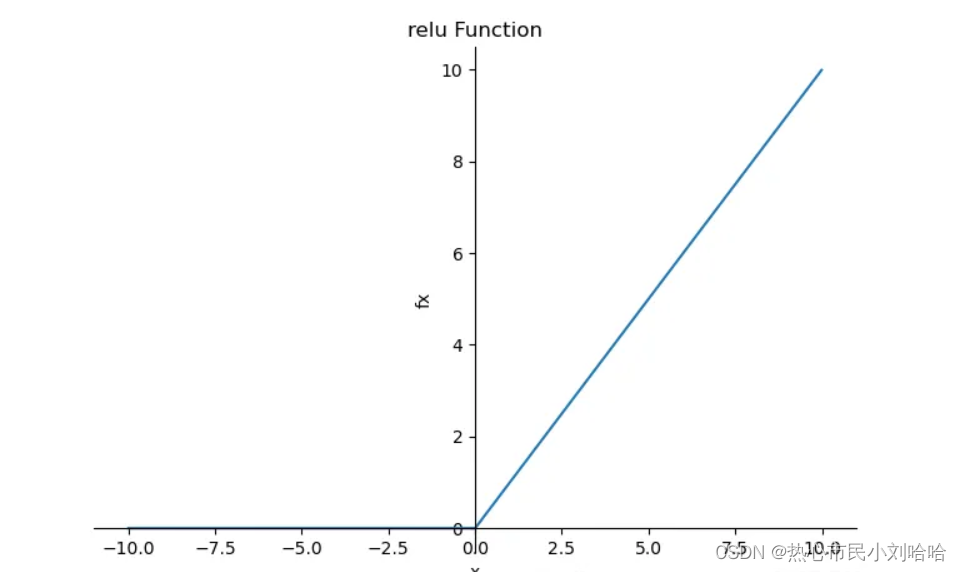 特点:
特点:
计算速度快,收敛速度快,不是零均值,无幂运算。
2.为什么在机器学习中引入激活函数,例如在房价预测中加入激活函数(3)
即上面提到的激活函数的作用:也就是说它主要起到了一个映射的作用,在没有引入激活函数之前,输入和输出都是线性组合,跟没有隐藏层的效果是一样的,网络不易收敛,学习能力有限,就比如原始的感知机一样。激活函数的使用相当于引入了非线性函数,使模型更易于收敛,神经网络的逼近能力就更加强大。
在房价预测中模型数据多且数据数值大,加入激活函数使其更利于收敛,达到最终目的。
3.请简述随机梯度下降,批梯度下降的区别和各自的优点(6)
批量梯度下降(Batch Gradient Descent,BGD)
优点:
一次迭代对所有样本进行计算,利用了矩阵进行操作,实现了并行;
由全数据集确定方向,能够更好地代表样本总体,从而更准确地指向极值所在的方向;当目标函数为凸函数时,BGD一定可以得到全局最优。
缺点:
样本数目 很大时,每迭代一步都要对所有样本进行计算,过程会很慢。
(运算量大,浪费资源)
随机梯度下降(Stochastic Gradient Descent,SGD)
优点:
不是在全部数据上的损失函数,而是在每轮迭代中,随机优化某一条数据上的损失函数,这样每一轮参数更新速度都会加快。
缺点:
准确度下降。即使目标函数为强凸函数,SGD也无法线性收敛;
可能会收敛到局部最优。单个样本不能代表所有样本的趋势;
不易于并行实现。
4.线性判别分析(LDA)中,我们想要最优化的两个数值是什么(聚类算法也是以这两个数据为目标进行优化).(3)
1.让同类样例投影点的协方差尽可能小
2.让类中心之间的距离尽可能大
5.请写出交叉熵损失函数(CrossEntropyLoss)(3)
交叉熵损失函数
表达式:
二分类:
在二分的情况下,模型最后需要预测的结果只有两种情况,所以每个类别我们的预测得到的概率为 p 和 1-p ,此时表达式为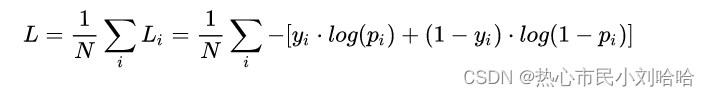 此处p表示样本i预测为正类的概率。
此处p表示样本i预测为正类的概率。
多分类:
相当于对二分类的扩展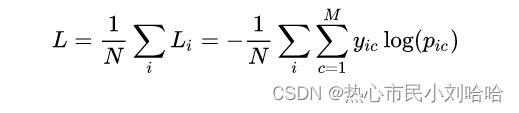
此处,m为类别的数量,y为符号函数(取0或1),p表示观测样本i属于c类别的预测概率。
图像特点: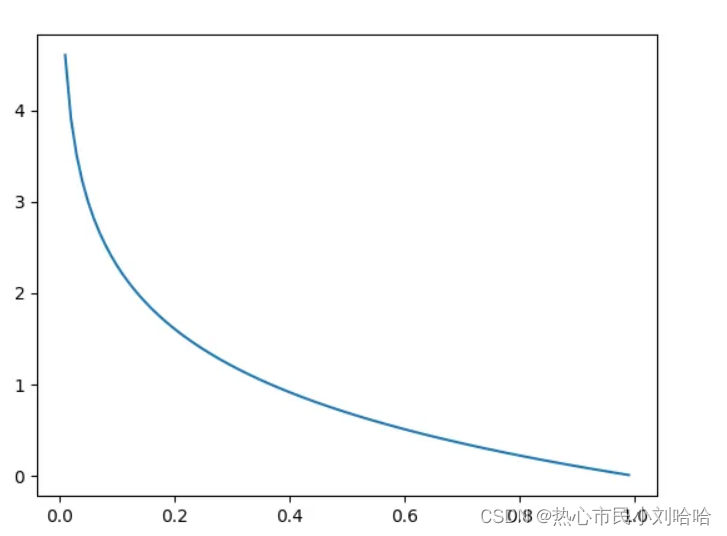 为凸函数,求导后能够得到全局最优值。
为凸函数,求导后能够得到全局最优值。
6.下面回归模型中的哪个步骤/假设最能影响过拟合和欠拟合之间的平衡因素( )(3)
A. 多项式的阶数
B. 是否通过矩阵求逆或梯度下降学习权重
C.使用常数项
答案:A
选取合适的多项式阶数对于回归的拟合程度会产生重要的影响。多项式阶数越高,越容易产生过拟合现象。
7.关于MLE(最大似然估计),下面哪一项或几项说法是正确的()(3)
1 MLE可能不存在
2 MLE总是存在
3 如果MLE存在,可能不是唯一的
4 如果MLE存在,肯定是唯一的
答案:1和3
MLE可以不是转折点,即可以不是似然(和对数似然)函数的一阶导数的消失点。
MLE可以不是唯一的。
8.以下关于线性回归和逻辑回归描述错误的是( )(3)
A.线性回归要求因变量是连续性数值变量,而逻辑回归要求因变量是分类型变量
B.线性回归直接分析因变量与自变量的关系,而逻辑回归分析因变量取某个值的概率与自变量的关系
C.线性回归要求因变量是分类型变量,而逻辑回归要求因变量是连续性数值变量
D.逻辑回归的因变量可以是二分类的,也可以是多分类的
答案:C
线性回归要求因变量是连续性数值变量,而逻辑回归要求因变量是分类型变量
9.类别不平衡问题会带来什么影响,如何有效处理类别不平衡的问题。(3)
类别不平衡:
概念:
指不同类别的样本数量差别非常大。
影响:
类别不平衡会导致出现无效的学习器。
常用的处理方法:
过采样(oversampling)
欠采样(undersampling)
代价敏感学习
`10.我们知道信息量的多少由信息的不确定性来衡量,信息量越大,信息的不确定性越大,信息熵的值越大。信息量越少,信息的不确定性越小,信息熵的值越小。请写出信息熵的公式。注:设集合D中第k类样本所占的比例为Pk(k=1,2,3,……,m)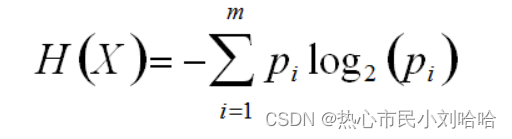
11.回归任务中最常用的性能度量是_______均方误差________。(3)

13,画出分类结果的混淆矩阵,并写出查准率P和查全率R。(6)
正例反例正例TPFN反例FPTN
查准率 P=TP/(TP+FP)
查全率 R=TP/(TP+FN)
14.什么是假设检验?(3)
假设检验又称统计假设检验,是用来判断样本与样本、样本与总体的差异是由抽样误差引起还是本质差别造成的统计推断方法。
显著性检验是假设检验中最常用的一种方法,也是一种最基本的统计推断形式,其基本原理是先对总体的特征做出某种假设,然后通过抽样研究的统计推理,对此假设应该被拒绝还是接受做出推断。常用的假设检验方法有二项检验、交叉验证t检验、McNemar检验、Friedman检验、Nemenyu后续检验等。
15.评价一个模型的好坏一般用什么来评价?(3)
均方误差,错误率,精度,查准率,查全率,F1,ROC,AUC,代价敏感错误率与代价曲线。
16.完整的机器学习项目主要步骤有哪些?(6)
收集数据,准备该数据,选择模型,训练,评估,超参数调整,预言
机考题
根据图片完成下列操作
1.一次性画出六个图形的轮廓
2.每次单独画出一个图形的轮廓,并输出该图形的颜色
3.输出图形颜色的同时判断图形的形状
import matplotlib.pyplot as plt
import cv2
defcv_show(name,img):
cv2.imshow(name, img)
cv2.waitKey(0)
cv2.destroyAllWindows()
img = cv2.imread('./OriginalImage1.png')
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(gray,127,255, cv2.THRESH_BINARY)#binary 为二值图像 contours是图像轮廓点信息 hierarchy表示层级# opencv 3.4.3.18 以下版本返回三个参数 ,以上版本返回2个参数
contours, hierarchy = cv2.findContours(thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours,-1,(0,0,255),2)# -1表示画出所有轮廓,2表示线条厚度,(0,0,256)是红色
cv_show('res', res)for i inrange(6,4,-1):
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, i,(0,0,255),2)# -1表示画出所有轮廓,2表示线条厚度,(0,0,256)是红色
cv_show('res', res)if(i==6):print('red yuan\n')if(i==5):print('zise sanjiaoxing\n')
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours,7,(0,0,255),2)# -1表示画出所有轮廓,2表示线条厚度,(0,0,256)是红色print('blue yuan\n')
cv_show('res', res)for i inrange(2,5):
draw_img = img.copy()
res = cv2.drawContours(draw_img, contours, i,(0,0,255),2)# -1表示画出所有轮廓,2表示线条厚度,(0,0,256)是红色
cv_show('res', res)if(i==2):print('blue sanjiaoxing\n')if(i==3):print('black juxing\n')if(i==4):print('red juxing\n')
类与对象
17.定义一个学生类
一.有下面属性:姓名,年龄,成绩(语文,数学,英语)[成绩类型为整数]
二.类方法
1.获取学生的姓名:get_name()返回类型:str
2.获取学生的年龄:get_age()返回类型:int
3.返回三门中最高的分数:get_course()返回类型:int
classStudent(object):def__init__(self,name,age,grade):
self.name=name
self.age=age
self.grade=grade
defget_name(self):print(str(self.name))defget_age(self):print(int(self.age))defget_course(self):
a =list(self.grade.values())print(max(a))
zm=Student('zm',18,{'语文':99,'数学':100,'英语':99})
zm.get_name()
zm.get_age()
zm.get_course()

18.__init__方法有什么作用,如何定义。
当使用类名()的方法去创建对象的时候
python解释器会自动调用__init__方法
因此可以在__init__方法中做一些初始化的设定
在每次创建新对象时,都自动完成这些初始化的设定
19.定义一个水果类,然后通过水果类,创建苹果对象、橘子对象、西瓜对象并分别为其添上颜色属性。
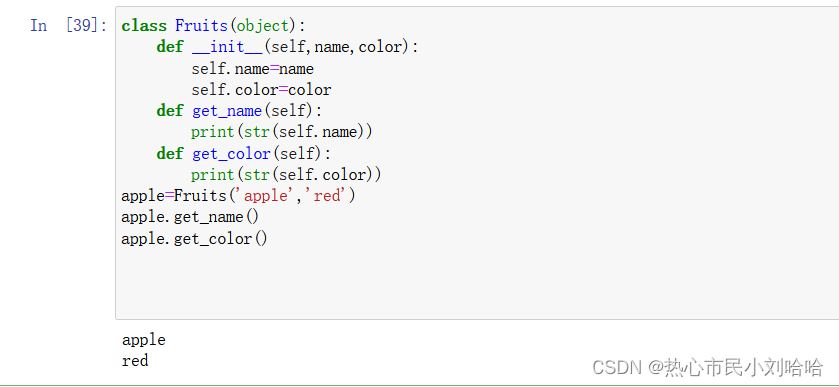
classFruits(object):def__init__(self,name,color):
self.name=name
self.color=color
defget_name(self):print(str(self.name))defget_color(self):print(str(self.color))
apple=Fruits('apple','red')
apple.get_name()
apple.get_color()
总结
经过一段时间的学习,再加上这次考核让我意识到了自己的一些问题:
1.由于是刚接触到这一类型的知识,再加上可能这类型知识本来就比较抽象,所以对这类型的知识还有很多的问题。可能学习方法也有点问题,就在那干巴巴的啃书,不仅仅让自己很累而且还遗留了很多问题,希望以后可以把书本上的知识和一些代码或者是视频结合起来,更助于理解。
2.因为一些个人原因导致在这一块用的时间比较少,所以反映出来这么多问题也是可以理解的,希望可以在接下来的日子里继续努力,愿勤能补拙吧。
版权归原作者 热心市民小刘哈哈 所有, 如有侵权,请联系我们删除。