深入浅出PyTorch中的nn.CrossEntropyLoss
PyTorch中的交叉熵详解
花了2个晚上,拿到了吴恩达@斯坦福大学的机器学习课程证书
警告⚠️⚠️⚠️请认真阅读此文,操作不慎可能血亏真金白银吴恩达算是我的精神导师了,很早之前就是看他的视频入门机器学习。他的经典课程《机器学习》 2012 年上线,十年间近 500 万人注册。最近他开发的机器学习专项课程由deeplearning.ai和斯坦福大学提供,上线Coursera。我花了两个

pandas.read_csv() 处理 CSV 文件的 6 个有用参数
pandas.read_csv 有很多有用的参数,你都知道吗?本文将介绍一些 pandas.read_csv()有用的参数,这些参数在我们日常处理CSV文件的时候是非常有用的。
机器学习:李航-统计学习方法笔记(一)监督学习概论
目录1.1统计学习1.2统计学习的分类1.2.1基本分类监督学习定义: 无监督学习 强化学习半监督学习主动学习统计学习是关于计算机基于数据构建概率统计模型并运用模型对数据进行预测与分析的一门学科。也可以说统计学习就是计算机系统通过运用数据及统计方提高系统性能的机器学习。故统计学习也称为统计机器学习。

卷积神经网络在深度学习中新发展的5篇论文推荐
卷积神经网络在深度学习中新发展的5篇论文推荐
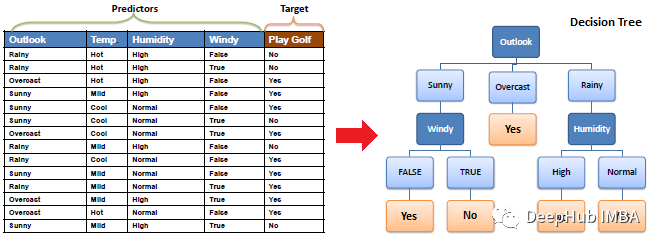
AI遮天传 ML-决策树
决策树学习是最早被提出的一批机器学习的方法之一,由于它好用且具有很强的可解释性,到现在依然在被广泛使用。

Github Copilot 值得购买吗?使用GitHub Copilot进行快速EDA的示例
本篇文章作为例子来演示如何将Copilot用于探索性分析,看看每月10美元是否值得
考虑关系的图卷积神经网络R-GCN的一些理解以及DGL官方代码的一些讲解
昨天写的GCN的一篇文章入榜了,可喜可贺。但是感觉距离我的目标还是有点远,因为最后要用R-GAT,我感觉可能得再懂一点R-GCN和GAT才可能比较好的理解R-GAT,今天就尝试一下把R-GCN搞搞清楚吧(至少得读懂DGL官方给的代码吧)R-GCN和GCN的区别就在于这个R。R-GCN考虑了关系对消息
基于图的 Affinity Propagation 聚类计算公式详解和代码示例
Affinity Propagation Clustering(简称AP算法)是2007提出的,当时发表在Science上《single-exemplar-based》。特别适合高维、多类数据快速聚类,相比传统的聚类算法,该算法算是比较新的,从聚类性能和效率方面都有大幅度的提升。
权重衰退(PyTorch)
权重衰退和正则项的影响本质以及Pytorch的代码实现
计算复杂度
计算复杂度的简单理解
图卷积神经网络GCN的一些理解以及DGL代码实例的一些讲解
近些年图神经网络十分火热,因为图数据结构其实在我们的现实生活中更常见,例如分子结构、人的社交关系、语言结构等等。NLP中的句法树、依存树就是一种特殊的图,因此,图神经网络的学习也是必不可少的。GCN是图卷积神经网络,初期研究者为了从数学上严谨的推导该公式是有效的,所以会涉及到诸如傅里叶变换,拉普拉斯

零样本和少样本学习
在本篇文章中,我们将讨论机器学习和深度学习的不同领域中的一个热门话题:零样本和少样本学习(Zero and Few Shot learning),它们在自然语言处理到计算机视觉中都有不同的应用场景。
机器学习西瓜书——第六章 支持向量机
从几何角度,对线性可分数据集,支持向量机就是找距离正负样本都最远的超平面,相比于感知机,其解是唯一的,且不偏不倚,泛化性能更好。给定训练样本集,分类学习最基本的想法就是基于训练集D在样本空间中找到一个划分超平面,将不同类别的样本分开,支持向量机倾向找到产生分类结果具有鲁棒性,对未见示例的泛化能力最强
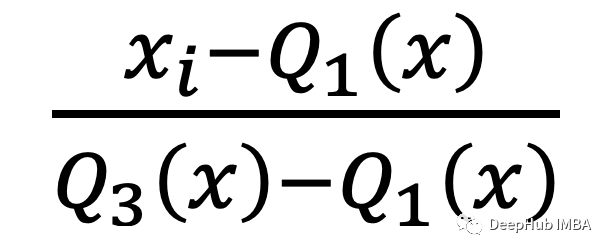
一个简单但是能上分的特征标准化方法
一般情况下我们在做数据预处理时都是使用StandardScaler来特征的标准化,如果你的数据中包含异常值,那么效果可能不好。
Pytorch(二) —— 激活函数、损失函数及其梯度
δ(x)=11+e−xδ′(x)=δ(1−δ)\delta(x)=\frac{1}{1+e^{-x}}\\\delta'(x)=\delta(1-\delta)δ(x)=1+e−x1δ′(x)=δ(1−δ)tanh(x)=ex−e−xex+e−x∂tanh(x)∂x=1−tanh2(x)tanh(

基于趋势和季节性的时间序列预测
分析时间序列的趋势和季节性,分解时间序列,实现预测模型
AI: 2021 年人工智能前沿科技报告02(更新中……)
AI: 2021 年人工智能前沿科技报告02(更新中……)2021 年对于人工智能技术和产业,依旧是不平凡的一年。随着算力、数据、算法等要素逐渐齐备,先进的算法结构不断涌现,各个研究方向研究成果不断突破,成熟的 AI 技术逐渐向代码库、平台和系统发展,实现产业和商业层面的落地应用,推动人工智能发展迈
【机器学习】向量化计算 -- 机器学习路上必经路
在求解矩阵中,往往有很多很好的,经过高度优化的线性代数库,如octave,matlib,python numpy, c++,java.我们使用这些线性代数库,可以短短几行实现 所要的效果。阅读本文内容(需要一点点线性代数的知识)例如 求公式:h(x)=∑i=1nθi∗xih(x) = \sum_{i
100+数据科学面试问题和答案总结 - 机器学习和深度学习
来自Amazon,谷歌,Meta, Microsoft等的面试问题,本文接着昨天的文章整理了机器学习和深度学习的问题



