AAAI2023 | DeMT: CNN+Transformer实现多任务学习(分割/深度等)
本文结合了可变形CNN和query-based 的Transformer优点,提出了一种新的MTL模型,用于密集预测的多任务学习,基于简单有效的编码器-解码器架构(即,可变形混合器编码器和任务感知transformer解码器),称之为DeMT。
学习Transformer:自注意力与多头自注意力的原理及实现
自从Transformer[3]模型在NLP领域问世后,基于Transformer的深度学习模型性能逐渐在NLP和CV领域(Vision Transformer)取得了令人惊叹的提升。本文的主要目的是介绍经典Transformer模型和Vision Transformer的技术细节及基本原理,以方便
对Transformer中Add&Norm层的理解
首先我们还是先来回顾一下Transformer的结构:Transformer结构主要分为两大部分,一是Encoder层结构,另一个则是Decoder层结构,Encoder 的输入由 Input Embedding 和 Positional Embedding 求和输入Multi-Head-Atten
Github复现-测试基于transformer的变化检测模型BIT_CD
基于Transformer 的变化检测模型测试
Transformer与看图说话
Transformer与看图说话
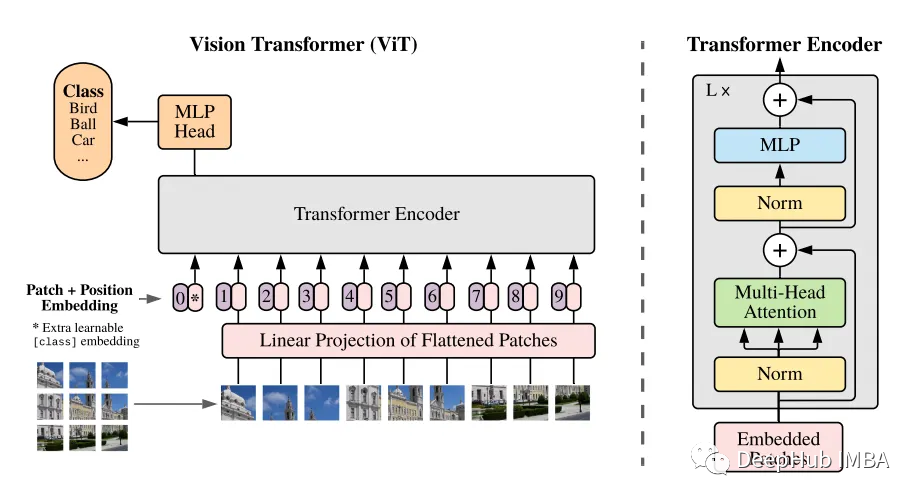
使用JAX实现完整的Vision Transformer
本文将展示如何使用JAX/Flax实现Vision Transformer (ViT),以及如何使用JAX/Flax训练ViT。
如何用DETR(detection transformer)训练自己的数据集
DETR(detection transformer)简介DETR是Facebook AI的研究者提出的Transformer的视觉版本,是CNN和transformer的融合,实现了端到端的预测,主要用于目标检测和全景分割。DETR的Github地址:link

可视化VIT中的注意力
ViT中最主要的就是注意力机制,所以可视化注意力就成为了解ViT的重要步骤,所以我们这里介绍如何可视化ViT中的注意力
Transformer时间序列预测
Transformer时间序列预测
改进YOLO:YOLOv5结合swin transformer
yolov5改进,添加swing transformer
图像恢复 SWinIR : 彻底理解论文和源代码 (注释详尽)
文章目录SwinIR 论文SWinIR 网络结构整体框架浅层特征提取深层特征提取图像重建模块主要代码理解SwinIRMLPPatch EmbeddingWindow Attention残差 Swin Transformer 块 (RSTB)HQ Image Reconstruction一个测试实例参
Vision Transformer这两年
在NLP领域取得巨大成功后,Transformer架构在计算机视觉方面的作用日渐凸显,成为越来越普遍的CV工具。自2020年10月Vision Transformer模型推出以来,人们开始高度关注Transformer模型在计算机视觉上的应用。
Swin-Transformer网络结构详解
文章目录0 前言1 网络整体框架2 Patch Merging详解3 W-MSA详解Ω(MSA)\Omega (MSA)Ω(MSA)模块计算量Ω(W−MSA)\Omega (W-MSA)Ω(W−MSA)模块计算量4 SW-MSA详解5 Relative Position Bias详解6 模型详细配
DEFORMABLE DETR详解
transformer组件在处理图像特征图中的不足。在初始化时,注意模块对特征图中的所有像素施加了几乎一致的注意权重。长时间的训练周期是为了学习注意权重,以关注稀疏的有意义的位置。另一方面,transformer编码器中的注意权值计算是二次计算w.r.t.像素数。因此,处理高分辨率的特征映射具有非常
深度学习 Transformer架构解析
2018年10月,Google发出一篇论文《BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding》, BERT模型横空出世, 并横扫NLP领域11项任务的最佳成绩!而在BERT中发挥重要作用的
变形金刚——Transformer入门刨析详解
Transformer详解
Swin Transformer做backbone的YoloX目标检测
使用Swin Transformer做骨干网络进行YoloX目标检测
深度网络架构的设计技巧(三)之ConvNeXt:打破Transformer垄断的纯CNN架构
正当其时的“2020s”年代,从Transformer开始,引爆了一股“咆哮”的热潮,各种框架层出不穷,借用凯明一句话“without bells and whistles”,沉淀下来的实用性如何?本文作者长篇分析设计CNN架构的若干技巧,对照Swin Transformer的设计理念,渐进式“现代
改进YOLOv5系列:9.BoTNet Transformer结构的修改
目标检测小白科研Trick改进推荐 | 包括Backbone、Neck、Head、注意力机制、IoU损失函数、NMS、Loss计算方式、自注意力机制、数据增强部分、激活函数
图像恢复 SWinIR : 彻底理解论文和源代码 (注释详尽)
文章目录SwinIR 论文SWinIR 网络结构整体框架浅层特征提取深层特征提取图像重建模块主要代码理解SwinIRMLPPatch EmbeddingWindow Attention残差 Swin Transformer 块 (RSTB)HQ Image Reconstruction一个测试实例参



