
对Add&Norm层的理解
Add操作
首先我们还是先来回顾一下Transformer的结构:Transformer结构主要分为两大部分,一是Encoder层结构,另一个则是Decoder层结构,Encoder 的输入由 Input Embedding 和 Positional Embedding 求和输入Multi-Head-Attention,再通过Feed Forward进行输出。
由下图可以看出:在Encoder层和Decoder层中都用到了Add&Norm操作,即残差连接和层归一化操作。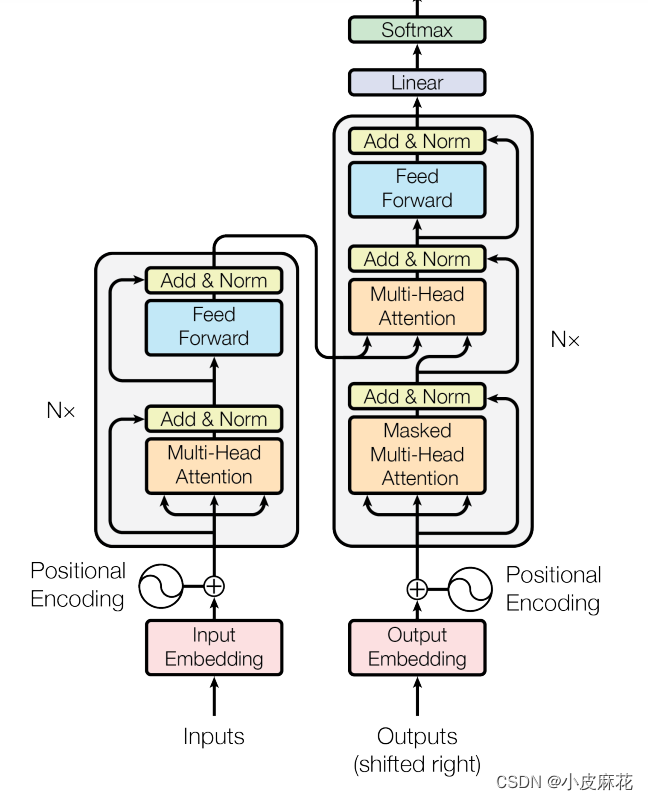
什么是残差连接呢?残差连接就是把网络的输入和输出相加,即网络的输出为F(x)+x,在网络结构比较深的时候,网络梯度反向传播更新参数时,容易造成梯度消失的问题,但是如果每层的输出都加上一个x的时候,就变成了F(x)+x,对x求导结果为1,所以就相当于每一层求导时都加上了一个常数项‘1’,有效解决了梯度消失问题。
Norm操作
首先要明白Norm做了一件什么事,从刚开始接触Transformer开始,我认为所谓的Norm就是BatchNorm,但是有一天我看到了这篇文章,才明白了Norm是什么。
假设我们输入的词向量的形状是(2,3,4),2为批次(batch),3为句子长度,4为词向量的维度,生成以下数据:
[[w11, w12, w13, w14],[w21, w22, w23, w24],[w31, w32, w33, w34][w41, w42, w43, w44],[w51, w52, w53, w54],[w61, w62, w63, w64]]
如果是在做BatchNorm(BN)的话,其计算过程如下:BN1=(w11+w12+w13+w14+w41+
w42+w43+w44)/8,同理会得到BN2和BN3,最终得到[BN1,BN2,BN3] 3个mean
如果是在做LayerNorm(LN)的话,则会进如下计算:LN1=(w11+w12+w13+w14+w21+
w22+w23+w24+w31+w32+w33+w34)/12,同理会得到LN2,最终得到[LN1,LN2]两个mean
如果是在做InstanceNorm(IN)的话,则会进如下计算:IN1=(w11+w12+w13+w14)/4,同理会得到IN2,IN3,IN4,IN5,IN6,六个mean,[[IN1,IN2,IN3],[IN4,IN5,IN6]]
下图完美的揭示了,这几种Norm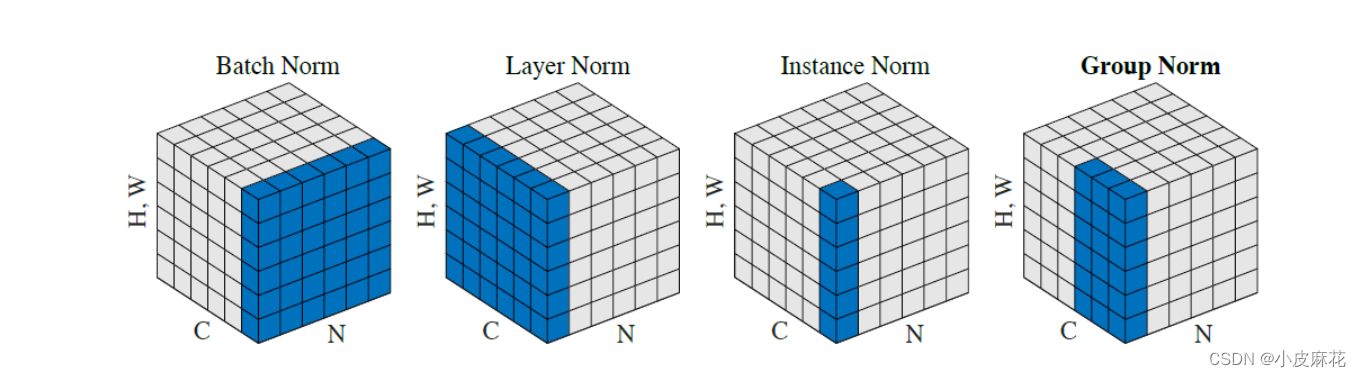
接下来我们来看一下Transformer中的Norm:首先生成[2,3,4]形状的数据,使用原始的编码方式进行编码:
import torch
from torch.nn import InstanceNorm2d
random_seed =123
torch.manual_seed(random_seed)
batch_size, seq_size, dim =2,3,4
embedding = torch.randn(batch_size, seq_size, dim)
layer_norm = torch.nn.LayerNorm(dim, elementwise_affine =False)print("y: ", layer_norm(embedding))
输出:
y: tensor([[[1.5524,0.0155,-0.3596,-1.2083],[0.5851,1.3263,-0.7660,-1.1453],[0.2864,0.0185,1.2388,-1.5437]],[[1.1119,-0.3988,0.7275,-1.4406],[-0.4144,-1.1914,0.0548,1.5510],[0.3914,-0.5591,1.4105,-1.2428]]])
接下来手动去进行一下编码:
eps:float=0.00001
mean = torch.mean(embedding[:,:,:], dim=(-1), keepdim=True)
var = torch.square(embedding[:,:,:]- mean).mean(dim=(-1), keepdim=True)print("mean: ", mean.shape)print("y_custom: ",(embedding[:,:,:]- mean)/ torch.sqrt(var + eps))
mean: torch.Size([2,3,1])
y_custom: tensor([[[1.1505,0.5212,-0.1262,-1.5455],[-0.6586,-0.2132,-0.8173,1.6890],[0.6000,1.2080,-0.3813,-1.4267]],[[-0.0861,1.0145,-1.5895,0.6610],[0.8724,0.9047,-1.5371,-0.2400],[0.1507,0.5268,0.9785,-1.6560]]])
可以发现和LayerNorm的结果是一样的,也就是说明Norm是对d_model进行的Norm,会给我们[batch,sqe_length]形状的平均值。
加下来进行batch_norm,
layer_norm = torch.nn.LayerNorm([seq_size,dim], elementwise_affine =False)
eps:float=0.00001
mean = torch.mean(embedding[:,:,:], dim=(-2,-1), keepdim=True)
var = torch.square(embedding[:,:,:]- mean).mean(dim=(-2,-1), keepdim=True)print("mean: ", mean.shape)print("y_custom: ",(embedding[:,:,:]- mean)/ torch.sqrt(var + eps))
输出:
mean: torch.Size([2,1,1])
y_custom: tensor([[[1.1822,0.4419,-0.3196,-1.9889],[-0.6677,-0.2537,-0.8151,1.5143],[0.7174,1.2147,-0.0852,-0.9403]],[[-0.0138,1.5666,-2.1726,1.0590],[0.6646,0.6852,-0.8706,-0.0442],[-0.1163,0.1389,0.4454,-1.3423]]])
可以看到BN的计算的mean形状为[2, 1, 1],并且Norm结果也和上面的两个不一样,这就充分说明了Norm是在对最后一个维度求平均。
那么什么又是Instancenorm呢?接下来再来实现一下instancenorm
instance_norm = InstanceNorm2d(3, affine=False)
output = instance_norm(embedding.reshape(2,3,4,1))#InstanceNorm2D需要(N,C,H,W)的shape作为输入
layer_norm = torch.nn.LayerNorm(4, elementwise_affine =False)print(layer_norm(embedding))
输出:
tensor([[[1.1505,0.5212,-0.1262,-1.5455],[-0.6586,-0.2132,-0.8173,1.6890],[0.6000,1.2080,-0.3813,-1.4267]],[[-0.0861,1.0145,-1.5895,0.6610],[0.8724,0.9047,-1.5371,-0.2400],[0.1507,0.5268,0.9785,-1.6560]]])
可以看出无论是layernorm还是instancenorm,还是我们手动去求平均计算其Norm,结果都是一样的,由此我们可以得出一个结论:Layernorm实际上是在做Instancenorm!
如果喜欢文章请点个赞,笔者也是一个刚入门Transformer的小白,一起学习,共同努力。
版权归原作者 江 东 所有, 如有侵权,请联系我们删除。