
2022年, Vision Transformer (ViT)成为卷积神经网络(cnn)的有力竞争对手,卷积神经网络目前是计算机视觉领域的最先进技术,广泛应用于许多图像识别应用。在计算效率和精度方面,ViT模型超过了目前最先进的(CNN)几乎四倍。
ViT是如何工作的?
ViT模型的性能取决于优化器、网络深度和特定于数据集的超参数等, 标准 ViT stem 采用 16 *16 卷积和 16 步长。

CNN 将原始像素转换为特征图。然后,tokenizer 将特征图转换为一系列令牌,这些令牌随后被送入transformer。然后transformer使用注意力方法生成一系列输出令牌。
projector 最终将输出令牌标记重新连接到特征图。
vision transformer模型的整体架构如下:
- 将图像拆分为补丁(固定大小)
- 展平图像块
- 从这些展平的图像块中创建低维线性嵌入
- 包括位置嵌入
- 将序列作为输入发送到transformer编码器
- 使用图像标签预训练 ViT 模型,然后在广泛的数据集上进行训练
- 在图像分类的下游数据集进行微调
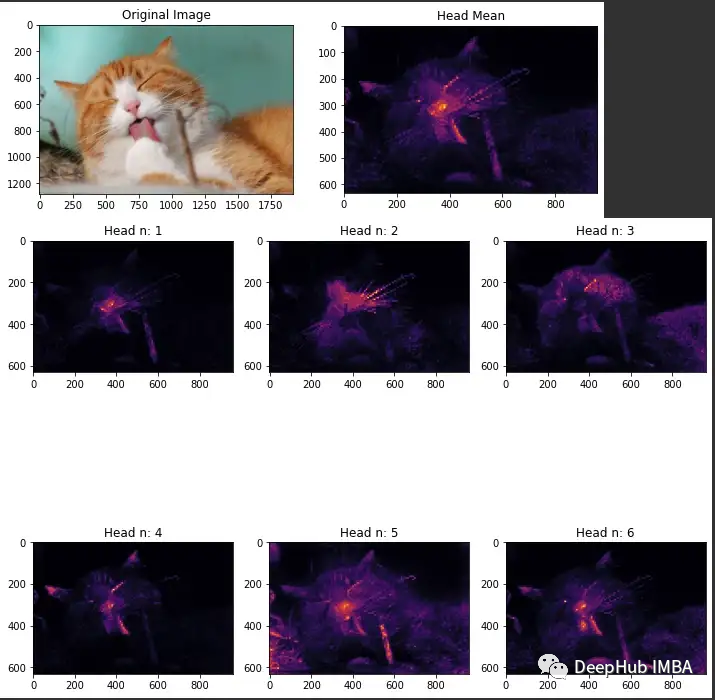
可视化注意力
ViT中最主要的就是注意力机制,所以可视化注意力就成为了解ViT的重要步骤,所以我们这里介绍如何可视化ViT中的注意力
导入库
importos
importtorch
importnumpyasnp
importmath
fromfunctoolsimportpartial
importtorch
importtorch.nnasnn
importipywidgetsaswidgets
importio
fromPILimportImage
fromtorchvisionimporttransforms
importmatplotlib.pyplotasplt
importnumpyasnp
fromtorchimportnn
importwarnings
warnings.filterwarnings("ignore")
创建一个VIT
deftrunc_normal_(tensor, mean=0., std=1., a=-2., b=2.):
# type: (Tensor, float, float, float, float) -> Tensor
return_no_grad_trunc_normal_(tensor, mean, std, a, b)
def_no_grad_trunc_normal_(tensor, mean, std, a, b):
# Cut & paste from PyTorch official master until it's in a few official releases - RW
# Method based on https://people.sc.fsu.edu/~jburkardt/presentations/truncated_normal.pdf
defnorm_cdf(x):
# Computes standard normal cumulative distribution function
return (1.+math.erf(x/math.sqrt(2.))) /2.
defdrop_path(x, drop_prob: float=0., training: bool=False):
ifdrop_prob==0.ornottraining:
returnx
keep_prob=1-drop_prob
# work with diff dim tensors, not just 2D ConvNets
shape= (x.shape[0],) + (1,) * (x.ndim-1)
random_tensor=keep_prob+ \
torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor_() # binarize
output=x.div(keep_prob) *random_tensor
returnoutput
classDropPath(nn.Module):
"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"""
def__init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob=drop_prob
defforward(self, x):
returndrop_path(x, self.drop_prob, self.training)
classMlp(nn.Module):
def__init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features=out_featuresorin_features
hidden_features=hidden_featuresorin_features
self.fc1=nn.Linear(in_features, hidden_features)
self.act=act_layer()
self.fc2=nn.Linear(hidden_features, out_features)
self.drop=nn.Dropout(drop)
defforward(self, x):
x=self.fc1(x)
x=self.act(x)
x=self.drop(x)
x=self.fc2(x)
x=self.drop(x)
returnx
classAttention(nn.Module):
def__init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0.):
super().__init__()
self.num_heads=num_heads
head_dim=dim//num_heads
self.scale=qk_scaleorhead_dim**-0.5
self.qkv=nn.Linear(dim, dim*3, bias=qkv_bias)
self.attn_drop=nn.Dropout(attn_drop)
self.proj=nn.Linear(dim, dim)
self.proj_drop=nn.Dropout(proj_drop)
defforward(self, x):
B, N, C=x.shape
qkv=self.qkv(x).reshape(B, N, 3, self.num_heads, C//
self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v=qkv[0], qkv[1], qkv[2]
attn= ([email protected](-2, -1)) *self.scale
attn=attn.softmax(dim=-1)
attn=self.attn_drop(attn)
x= (attn@v).transpose(1, 2).reshape(B, N, C)
x=self.proj(x)
x=self.proj_drop(x)
returnx, attn
classBlock(nn.Module):
def__init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm):
super().__init__()
self.norm1=norm_layer(dim)
self.attn=Attention(
dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale, attn_drop=attn_drop, proj_drop=drop)
self.drop_path=DropPath(
drop_path) ifdrop_path>0.elsenn.Identity()
self.norm2=norm_layer(dim)
mlp_hidden_dim=int(dim*mlp_ratio)
self.mlp=Mlp(in_features=dim, hidden_features=mlp_hidden_dim,
act_layer=act_layer, drop=drop)
defforward(self, x, return_attention=False):
y, attn=self.attn(self.norm1(x))
ifreturn_attention:
returnattn
x=x+self.drop_path(y)
x=x+self.drop_path(self.mlp(self.norm2(x)))
returnx
classPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def__init__(self, img_size=224, patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
num_patches= (img_size//patch_size) * (img_size//patch_size)
self.img_size=img_size
self.patch_size=patch_size
self.num_patches=num_patches
self.proj=nn.Conv2d(in_chans, embed_dim,
kernel_size=patch_size, stride=patch_size)
defforward(self, x):
B, C, H, W=x.shape
x=self.proj(x).flatten(2).transpose(1, 2)
returnx
classVisionTransformer(nn.Module):
""" Vision Transformer """
def__init__(self, img_size=[224], patch_size=16, in_chans=3, num_classes=0, embed_dim=768, depth=12,
num_heads=12, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop_rate=0., attn_drop_rate=0.,
drop_path_rate=0., norm_layer=nn.LayerNorm, **kwargs):
super().__init__()
self.num_features=self.embed_dim=embed_dim
self.patch_embed=PatchEmbed(
img_size=img_size[0], patch_size=patch_size, in_chans=in_chans, embed_dim=embed_dim)
num_patches=self.patch_embed.num_patches
self.cls_token=nn.Parameter(torch.zeros(1, 1, embed_dim))
self.pos_embed=nn.Parameter(
torch.zeros(1, num_patches+1, embed_dim))
self.pos_drop=nn.Dropout(p=drop_rate)
# stochastic depth decay rule
dpr= [x.item() forxintorch.linspace(0, drop_path_rate, depth)]
self.blocks=nn.ModuleList([
Block(
dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[i], norm_layer=norm_layer)
foriinrange(depth)])
self.norm=norm_layer(embed_dim)
# Classifier head
self.head=nn.Linear(
embed_dim, num_classes) ifnum_classes>0elsenn.Identity()
trunc_normal_(self.pos_embed, std=.02)
trunc_normal_(self.cls_token, std=.02)
self.apply(self._init_weights)
def_init_weights(self, m):
ifisinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
ifisinstance(m, nn.Linear) andm.biasisnotNone:
nn.init.constant_(m.bias, 0)
elifisinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
definterpolate_pos_encoding(self, x, w, h):
npatch=x.shape[1] -1
N=self.pos_embed.shape[1] -1
ifnpatch==Nandw==h:
returnself.pos_embed
class_pos_embed=self.pos_embed[:, 0]
patch_pos_embed=self.pos_embed[:, 1:]
dim=x.shape[-1]
w0=w//self.patch_embed.patch_size
h0=h//self.patch_embed.patch_size
# we add a small number to avoid floating point error in the interpolation
# see discussion at https://github.com/facebookresearch/dino/issues/8
w0, h0=w0+0.1, h0+0.1
patch_pos_embed=nn.functional.interpolate(
patch_pos_embed.reshape(1, int(math.sqrt(N)), int(
math.sqrt(N)), dim).permute(0, 3, 1, 2),
scale_factor=(w0/math.sqrt(N), h0/math.sqrt(N)),
mode='bicubic',
)
assertint(
w0) ==patch_pos_embed.shape[-2] andint(h0) ==patch_pos_embed.shape[-1]
patch_pos_embed=patch_pos_embed.permute(0, 2, 3, 1).view(1, -1, dim)
returntorch.cat((class_pos_embed.unsqueeze(0), patch_pos_embed), dim=1)
defprepare_tokens(self, x):
B, nc, w, h=x.shape
x=self.patch_embed(x) # patch linear embedding
# add the [CLS] token to the embed patch tokens
cls_tokens=self.cls_token.expand(B, -1, -1)
x=torch.cat((cls_tokens, x), dim=1)
# add positional encoding to each token
x=x+self.interpolate_pos_encoding(x, w, h)
returnself.pos_drop(x)
defforward(self, x):
x=self.prepare_tokens(x)
forblkinself.blocks:
x=blk(x)
x=self.norm(x)
returnx[:, 0]
defget_last_selfattention(self, x):
x=self.prepare_tokens(x)
fori, blkinenumerate(self.blocks):
ifi<len(self.blocks) -1:
x=blk(x)
else:
# return attention of the last block
returnblk(x, return_attention=True)
defget_intermediate_layers(self, x, n=1):
x=self.prepare_tokens(x)
# we return the output tokens from the `n` last blocks
output= []
fori, blkinenumerate(self.blocks):
x=blk(x)
iflen(self.blocks) -i<=n:
output.append(self.norm(x))
returnoutput
classVitGenerator(object):
def__init__(self, name_model, patch_size, device, evaluate=True, random=False, verbose=False):
self.name_model=name_model
self.patch_size=patch_size
self.evaluate=evaluate
self.device=device
self.verbose=verbose
self.model=self._getModel()
self._initializeModel()
ifnotrandom:
self._loadPretrainedWeights()
def_getModel(self):
ifself.verbose:
print(
f"[INFO] Initializing {self.name_model} with patch size of {self.patch_size}")
ifself.name_model=='vit_tiny':
model=VisionTransformer(patch_size=self.patch_size, embed_dim=192, depth=12, num_heads=3, mlp_ratio=4,
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6))
elifself.name_model=='vit_small':
model=VisionTransformer(patch_size=self.patch_size, embed_dim=384, depth=12, num_heads=6, mlp_ratio=4,
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6))
elifself.name_model=='vit_base':
model=VisionTransformer(patch_size=self.patch_size, embed_dim=768, depth=12, num_heads=12, mlp_ratio=4,
qkv_bias=True, norm_layer=partial(nn.LayerNorm, eps=1e-6))
else:
raisef"No model found with {self.name_model}"
returnmodel
def_initializeModel(self):
ifself.evaluate:
forpinself.model.parameters():
p.requires_grad=False
self.model.eval()
self.model.to(self.device)
def_loadPretrainedWeights(self):
ifself.verbose:
print("[INFO] Loading weights")
url=None
ifself.name_model=='vit_small'andself.patch_size==16:
url="dino_deitsmall16_pretrain/dino_deitsmall16_pretrain.pth"
elifself.name_model=='vit_small'andself.patch_size==8:
url="dino_deitsmall8_300ep_pretrain/dino_deitsmall8_300ep_pretrain.pth"
elifself.name_model=='vit_base'andself.patch_size==16:
url="dino_vitbase16_pretrain/dino_vitbase16_pretrain.pth"
elifself.name_model=='vit_base'andself.patch_size==8:
url="dino_vitbase8_pretrain/dino_vitbase8_pretrain.pth"
ifurlisNone:
print(
f"Since no pretrained weights have been found with name {self.name_model} and patch size {self.patch_size}, random weights will be used")
else:
state_dict=torch.hub.load_state_dict_from_url(
url="https://dl.fbaipublicfiles.com/dino/"+url)
self.model.load_state_dict(state_dict, strict=True)
defget_last_selfattention(self, img):
returnself.model.get_last_selfattention(img.to(self.device))
def__call__(self, x):
returnself.model(x)
创建可视化函数
deftransform(img, img_size):
img=transforms.Resize(img_size)(img)
img=transforms.ToTensor()(img)
returnimg
defvisualize_predict(model, img, img_size, patch_size, device):
img_pre=transform(img, img_size)
attention=visualize_attention(model, img_pre, patch_size, device)
plot_attention(img, attention)
defvisualize_attention(model, img, patch_size, device):
# make the image divisible by the patch size
w, h=img.shape[1] -img.shape[1] %patch_size, img.shape[2] - \
img.shape[2] %patch_size
img=img[:, :w, :h].unsqueeze(0)
w_featmap=img.shape[-2] //patch_size
h_featmap=img.shape[-1] //patch_size
attentions=model.get_last_selfattention(img.to(device))
nh=attentions.shape[1] # number of head
# keep only the output patch attention
attentions=attentions[0, :, 0, 1:].reshape(nh, -1)
attentions=attentions.reshape(nh, w_featmap, h_featmap)
attentions=nn.functional.interpolate(attentions.unsqueeze(
0), scale_factor=patch_size, mode="nearest")[0].cpu().numpy()
returnattentions
defplot_attention(img, attention):
n_heads=attention.shape[0]
plt.figure(figsize=(10, 10))
text= ["Original Image", "Head Mean"]
fori, figinenumerate([img, np.mean(attention, 0)]):
plt.subplot(1, 2, i+1)
plt.imshow(fig, cmap='inferno')
plt.title(text[i])
plt.show()
plt.figure(figsize=(10, 10))
foriinrange(n_heads):
plt.subplot(n_heads//3, 3, i+1)
plt.imshow(attention[i], cmap='inferno')
plt.title(f"Head n: {i+1}")
plt.tight_layout()
plt.show()
classLoader(object):
def__init__(self):
self.uploader=widgets.FileUpload(accept='image/*', multiple=False)
self._start()
def_start(self):
display(self.uploader)
defgetLastImage(self):
try:
foruploaded_filenameinself.uploader.value:
uploaded_filename=uploaded_filename
img=Image.open(io.BytesIO(
bytes(self.uploader.value[uploaded_filename]['content'])))
returnimg
except:
returnNone
defsaveImage(self, path):
withopen(path, 'wb') asoutput_file:
foruploaded_filenameinself.uploader.value:
content=self.uploader.value[uploaded_filename]['content']
output_file.write(content)
对一个图像的注意力进行可视化
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
if device.type == "cuda":
torch.cuda.set_device(1)
name_model = 'vit_small'
patch_size = 8
model = VitGenerator(name_model, patch_size,
device, evaluate=True, random=False, verbose=True)
# Visualizing Dog Image
path = '/content/corgi_image.jpg'
img = Image.open(path)
factor_reduce = 2
img_size = tuple(np.array(img.size[::-1]) // factor_reduce)
visualize_predict(model, img, img_size, patch_size, device)

本文代码
https://colab.research.google.com/drive/1tRRuT21W3VUvORCFRazrVaFLSWYbYoqL?usp=sharing
作者:Aryan Jadon