
必读文章: https://blog.csdn.net/qq_37541097/article/details/117691873
论文名:Attention Is All You Need
文章目录
1、Self-Attention 自注意力机制
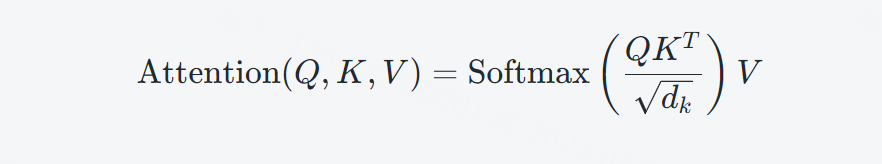
Query(Q)表示当前时间步的输入信息,它与Key(K)进行点积操作,用于计算注意力权重。
Key(K)表示序列中所有时间步的信息,与Query(Q)进行点积操作,用于计算注意力权重。
Value(V)包含了序列中每个时间步的隐藏状态或特征表示,根据注意力权重对其进行加权求和,得到最终的上下文向量。
注意力机制计算过程:
计算注意力分数(Attention Scores):注意力分数表示查询Q与键K之间的相关性,计算公式为:
A t t e n t i o n S c o r e ( Q , K ) = Q ⋅ K ⊤ d k Attention Score(Q, K) = \frac{Q \cdot K^\top}{\sqrt{d_k}}AttentionScore(Q,K)=dkQ⋅K⊤
其中,(d_k) 是查询和键的维度。
计算注意力权重(Attention Weights):通过对注意力分数应用softmax函数,将分数转换为注意力权重,使它们归一化并总和为1:
A t t e n t i o n W e i g h t ( Q , K ) = softmax ( A t t e n t i o n S c o r e ( Q , K ) ) Attention Weight(Q, K) = \text{softmax}(Attention Score(Q, K))AttentionWeight(Q,K)=softmax(AttentionScore(Q,K))
计算加权值(Weighted Values):使用注意力权重对值V进行加权,得到加权值,计算公式如下:
W e i g h t e d V a l u e s ( Q , K , V ) = Attention Weight ( Q , K ) ⋅ V Weighted Values(Q, K, V) = \text{Attention Weight}(Q, K) \cdot VWeightedValues(Q,K,V)=Attention Weight(Q,K)⋅V
在Transformer的编码器和解码器中,Q、K、V的定义稍有不同:
在编码器(Encoder)中:
- 查询(Q):来自上一层编码器的输出。
- 键(K):来自上一层编码器的输出。
- 值(V):来自上一层编码器的输出。
在解码器(Decoder)中,与编码器不同的是,还会使用编码器的输出作为额外的键(K)和值(V):
- 查询(Q):来自上一层解码器的输出。
- 键(K):来自编码器的输出。
- 值(V):来自编码器的输出。
2、Multi-Head Attention
Multi-Head Attention 是 Transformer 模型中的一种注意力机制,它扩展了普通的自注意力机制(Self-Attention)以捕获更丰富的上下文信息。
在 Multi-Head Attention 中,通过使用多组独立的注意力头(attention heads),可以从不同的表示子空间中学习到更多的关系。每个注意力头都有自己对应的 Q、K、V 矩阵,通过独立的线性映射将输入进行转换得到。然后对每个注意力头进行注意力计算,并将它们的输出进行拼接,最后再经过一个线性映射得到最终的输出。
具体而言,Multi-Head Attention 的计算过程如下:

使用多个注意力头可以让模型同时关注不同位置和表示子空间的信息,从而提升模型的表达能力和泛化性能。
版权归原作者 XD742971636 所有, 如有侵权,请联系我们删除。