
一、概述
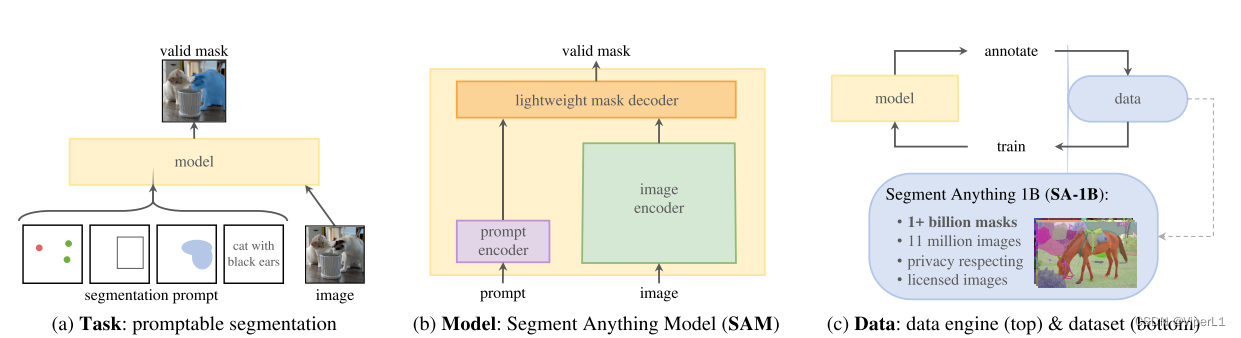
本文建立了一个基础图像分割模型,并将其在一个巨大的数据集上进行训练,目的是解决一系列下游任务。本文的关键点有3个:**task**,**model**,**data**。
Task
本文定义了一个可提示的通用分割任务,可以提供的预训练目标来支持下游任务的应用。提示仅指定在图像中分割的什么(如对象的空间/文本信息),这个提示可以是**模糊**的,输出会针对这些对象输出至少一个合理的掩码。
Model
** 本任务需要支持灵活提示的模型,且这个模型需要提示时实时输出分割掩码。满足三个约束:①图像编码器(负责图像嵌入);②提示编码器(负责提示嵌入);③结合前面两个信源的轻量级掩码解码器;该模型称为:Segment Anything Model**(SAM);该模型还有歧义意识,能自然的处理歧义。
Data
本项目使用了一个大规模数据源SA-1B;同时为了管理好这些数据,本项目建立了一个数据引擎(Data engine),分为三个阶段:**辅助-手动**、**半自动**和**全自动**。
二、网络结构
本文从NLP中获得启发,将**token**用于基础模型的训练,通过即时的工程解决各种下游任务。SAM会从单个模糊点提示生成3个有效掩码,分别为:**整体、部分、子部分**,如下图所示:

**Segment Anything Model**(SAM)的网络结构如下图所示:

1.Image encoder(图像编码器)
使用了一个MAE预训练的**Vision Transformer**(ViT)作为图像编码器。ViT网络可以参见往期博文[自注意力神经网络]Transfomer架构。
2.Prompt Encoder(提示编码器)
本设计中有2组提示,分为:稀疏的(点、框、文本)和密集的(掩码)。**点和框**可以由**位置编码**表示,位置编码综合了来自每种提示的学习嵌入和任意形式的文字(使用CLIP处理)。而掩码则通过**卷积嵌入**后与图像诸元素求和。
3.Lightweight mask decoder(轻量化掩码解码器)
掩码解码器可以有效的将**图嵌入**、**提示嵌入**和**输出标记**映射到掩码。本模型的解码器基于**Transformer**的解码器块修改,在解码器后添加了**动态掩码预测头**。解码器使用了提示自注意力和交叉注意力在**提示到图嵌入**(**prompt-to-image embedding**)和**副反转**(**vice-versa**,这个翻译不好 )两个方面进行了修改。完成这两个部分后,对图像进行上采样再使用MLP将输出标记映射到动态线性分类器上,最终得出每个图像位置的蒙板前景概率。

每层解码器执行以下4个步骤:
①对token进行自注意力
②从token(作为查询)和图(嵌入向量)进行交叉注意
③MLP逐点更新到每个token
④从图(嵌入向量)到token(作为查询)进行交叉注意
为了保证解码器能访问到关键几何信息,当他们参与注意层运算时,位置编码都会被添加到图嵌入向量中;此外,整个原始token(包含位置信息)也会被重新添加到图嵌入向量中。
4.其他技术细节
①歧义感知(Ambiguity-aware)
对于一个不确定的提示,模型会给出多个有效掩码,经过修改SAM可以由单个提示预测输出多个掩码(一般是3个--**整体**、**部分**、**子部分**)。训练时,仅掩码进行反向传播。为了对掩码进行排名,模型会预测每个掩码的置信分数(使用**IOU**度量)
②损失函数和训练(Losses and training)
本项目使用焦点损失函数(**focal loss**)和筛子损失函数(**dice loss**)的线性组合作为损失函数来监督掩码预测。对于文本提示,采用几何提示的方法进行混合训练。随后,随机抽取11轮中的每种掩码进行模拟交互,由于这种设计,SAM可以被无缝的接入**数据引擎**。
三、SAD数据引擎(Segment Anything Data Engine)
本小节对应前面的Data部分,主要用来从互联网上收集蒙板数据集SA-1B。数据引擎分为三个阶段:
1)**辅助手动阶段**(Assisted-manual stage)
进行人工标注,此阶段SAM先使用常见数据集进行分割训练,在标记了足够多数据时,SAM仅使用新注释的掩码进行再训练。
2)**半自动阶段**(Semi-automatic stage)
这个阶段的目标主要是增加遮罩的多样性以提高模型的切割能力。首先SAM会预测一些掩码,这些掩码会被展示给标注者,由标注者对任何其他未标注的地方进行标注,一增强模型在不显眼位置的能力。
3)**全自动阶段**(Fully automatic stage)
这个阶段标注是全自动的,由于歧义感知的存在,即是在模棱两可的情况下也能预测出有效掩码。对于最终得到的预测掩码,需要使用非极大抑制(NMS)来过滤重复项。
本文转载自: https://blog.csdn.net/weixin_37878740/article/details/130004084
版权归原作者 ViperL1 所有, 如有侵权,请联系我们删除。
版权归原作者 ViperL1 所有, 如有侵权,请联系我们删除。