

在数据湖中,对于数据清理和注释、架构匹配、数据发现和跨多个数据来源进行分析等许多操作,查找相似的列有着重要的应用。如果不能从多个不同的来源准确查找和分析数据,就会严重拉低效率,不论是数据科学家、医学研究人员、学者,还是金融和政府分析师,所有人都会深受其害。
传统解决方案涉及到使用词汇关键字搜索或正则表达式匹配,这些方法容易受到数据质量问题的影响,例如缺少列名或者不同数据集中采用了不同的列命名约定(例如, zip_code、zcode、postalcode )。
在这篇文章中,我们演示了一种解决方案,基于列名和/或列内容对相似列执行搜索。该解决方案使用 Amazon OpenSearch Service 中提供的近似最近邻算法来搜索具有相似语义的列。为了协助进行搜索,我们使用 Amazon SageMaker 中通过 sentence-transformers 库预训练的 Transformer 模型,为数据湖中的各个列创建特征表示(嵌入对象)。最后,为了从解决方案进行交互并可视化结果,我们构建了在 Amazon Fargate 上运行的交互式 Streamlit Web 应用程序。
我们提供了一个代码教程,您可用它来部署资源,以便对示例数据或自己的数据运行该解决方案。
解决方案概览
以下架构图展示了查找具有相似语义列的工作流程,分为两个阶段。第一阶段运行 Amazon Step Functions 工作流,从表格列创建嵌入对象并构建 OpenSearch Service 搜索索引。第二阶段是在线推理阶段,通过 Fargate 运行 Streamlit 应用程序。Web 应用程序收集输入搜索查询,并从 OpenSearch Service 索引中检索与该查询近似的 k 个最相似列。
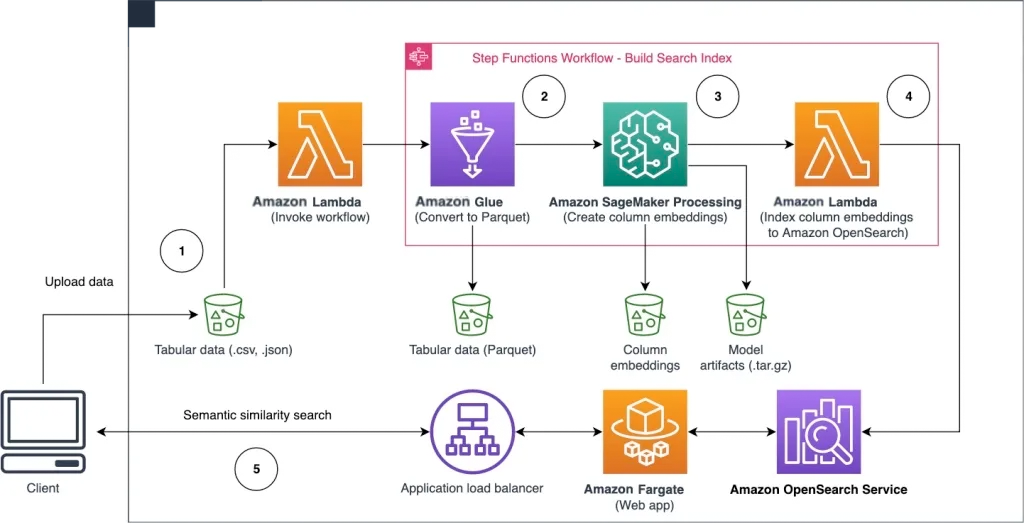
图1 解决方案架构
自动化工作流按以下步骤进行:
- 用户将表格数据集上传到 Amazon Simple Storage Service (Amazon S3) 存储桶中,这会调用 Amazon Lambda 函数来启动 Step Functions 工作流。
- 该工作流首先启动 Amazon Glue 作业,将 CSV 文件转换为 Apache Parquet 数据格式。
- SageMaker Processing 作业使用预训练模型或自定义列嵌入模型,为各个列创建嵌入对象。SageMaker Processing 作业将每个表的列嵌入对象保存在 Amazon S3 中。
- Lambda 函数创建 OpenSearch Service 域和集群,以索引上一步中生成的列嵌入对象。
- 最后,使用 Fargate 部署交互式 Streamlit Web 应用程序。Web 应用程序为用户提供了一个界面,用于输入查询,从而在 OpenSearch Service 域中搜索相似的列。
您可以从 GitHub 下载代码教程,在示例数据或自己的数据上试用此解决方案。Github 上提供了如何部署本教程所需资源的说明。
先决条件
要实施此解决方案,您需要:
- 亚马逊云科技账户。
- 对亚马逊云服务有一些基本了解,例如 Amazon Cloud Development Kit(Amazon CDK)、Lambda、OpenSearch Service 和 SageMaker Processing。
- 用于创建搜索索引的表格数据集。您可以使用自己的表格数据,也可以在 GitHub 上下载示例数据集。
构建搜索索引
第一阶段中将构建列搜索引擎索引。下图展示了运行此阶段的 Step Functions 工作流。
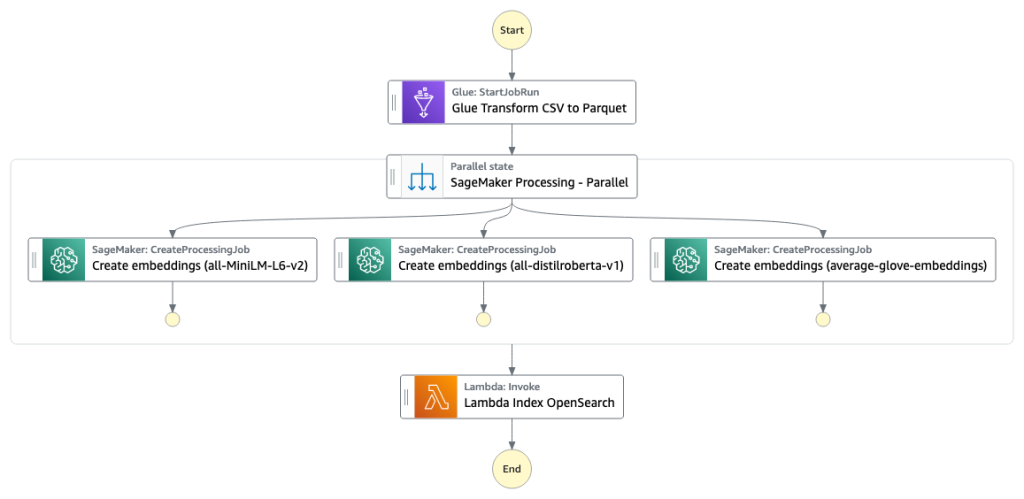
图 2 Step Functions 工作流 – 多个嵌入模型
数据集
在这篇文章中,我们构建了一个搜索索引,包括了超过 25 个表格数据集中的 400 多个列。数据集来自以下公共来源:
- s3://sagemaker-sample-files/datasets/tabular/
- NYC Open Data
- Chicago Data Portal
有关索引中包含的表的完整列表,请参阅 GitHub 上的代码教程(https://github.com/aws-samples/tabular-column-semantic-search/blob/main/sample-batch-datasets.json)。
您可以使用自己的表格数据集来扩充示例数据,或者构建自己的搜索索引。我们提供了两个 Lambda 函数用于启动 Step Functions 工作流,这两个函数分别为单个 CSV 文件或批量 CSV 文件构建搜索索引。
将 CSV 转换为 Parquet
使用 Amazon Glue 将原始 CSV 文件转换为 Parquet 数据格式。Parquet 是一种面向列格式文件的格式,是大数据分析中的首选格式,可提供高效的压缩和编码。在我们的实验中,与原始 CSV 文件相比,Parquet 数据格式显著减少了所需的存储空间。我们还使用 Parquet 作为通用数据格式来转换其他数据格式(例如 JSON 和 NDJSON),因为它支持高级嵌套数据结构。
创建表格列嵌入对象
在本文中,为了对示例表格数据集中的单个表列提取嵌入对象,我们使用了从 sentence-transformers 库预训练的以下模型。有关其他模型,请参阅 Pretrained Models(预训练模型,https://www.sbert.net/docs/pretrained_models.html)
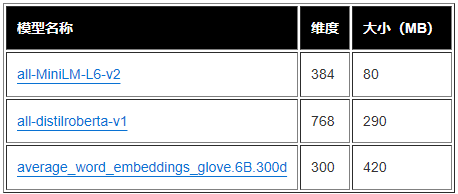
SageMaker Processing 作业为单个模型运行 create_embeddings.py (代码:https://github.com/aws-samples/tabular-column-semantic-search/blob/main/assets/s3/scripts/create_embeddings.py)。要从多个模型中提取嵌入对象,工作流会并行运行 SageMaker Processing 作业,如 Step Functions 工作流所示。我们使用该模型创建两组嵌入对象:
- column_name_embeddings – 列名的嵌入对象(标题)
- **column_content_embeddings – **列中所有行的平均嵌入对象
有关列嵌入过程的更多信息,请参阅 GitHub 上的代码教程(https://github.com/aws-samples/tabular-column-semantic-search)。
SageMaker Processing 步骤的替代方法是创建 SageMaker 批量变换,用于在大型数据集上获取列嵌入对象。这将需要将模型部署到 SageMaker 端点。有关更多信息,请参阅 Use Batch Transform(使用批量转换)。
**使用 OpenSearch Service **
对嵌入对象编制索引
在本阶段的最后一步,Lambda 函数将列嵌入对象添加到 OpenSearch Service 近似 k 近邻(kNN,k-Nearest-Neighbor)搜索索引中。向每个模型分配自己的搜索索引。有关近似 kNN 搜索索引参数的更多信息,请参阅 k-NN (https://opensearch.org/docs/latest/search-plugins/knn/index/)。
使用 Web 应用程序
进行在线推理和语义搜索
工作流程的第二阶段运行 Streamlit Web 应用程序,您可以在其中提供输入数据,然后在 OpenSearch Service 中搜索编制了索引的具有相似语义的列。应用层使用应用程序负载均衡器、Fargate 和 Lambda。应用程序基础设施作为解决方案的一部分自动部署。
使用该应用程序,您可以提供输入数据,然后搜索具有相似语义的列名和/或列内容。此外,您可以选择嵌入模型以及搜索中返回的最近邻的数量。应用程序接收输入数据,使用指定模型嵌入输入数据,并在 OpenSearch Service 中使用 kNN 搜索,以此来搜索编制了索引的列嵌入对象,并查找与给定输入数据最相似的列。显示的搜索结果包括表名、列名和所确定列的相似度分数,以及数据在 Amazon S3 中的位置,以供进一步探索。
下图显示了 Web 应用程序的示例。在此示例中,我们在数据湖中搜索具有与 district (负载)相似的 Column Names (负载类型)的列。应用程序使用 all-MiniLM-L6-v2 作为嵌入模型,从 OpenSearch Service 索引中返回了 10 个(k)最近邻。
根据 OpenSearch Service 中索引的数据,应用程序返回 transit_district 、 city 、 borough 和 location 作为四个最相似的列。此示例演示了搜索方法识别数据集中相似语义列的功能。

图 3:Web 应用程序用户界面
清理
要删除本教程中由 Amazon CDK 创建的资源,请运行以下命令:
Bash
cdk destroy --all
左滑查看更多
总结
在这篇文章中,我们介绍了为表格列构建语义搜索引擎的端到端工作流程。
您可以使用我们在 GitHub (https://github.com/aws-samples/tabular-column-semantic-search) 上提供的代码教程,开始处理自己的数据。如果您需要帮助加快在产品和流程中使用机器学习功能的速度,请联系 Amazon Machine Learning Solutions Lab (https://aws.amazon.com/ml-solutions-lab/)。
Original URL:
本篇作者

**Kachi Odoemene **
亚马逊云科技人工智能部门的应用科学家。他构建人工智能/机器学习解决方案,为亚马逊云科技客户解决业务问题。

Taylor McNally
Amazon Machine Learning Solutions Lab 的深度学习架构师。他帮助来自不同行业的客户利用亚马逊云科技上的人工智能/机器学习构建解决方案。他喜欢醇美咖啡,爱好户外活动,并享受与家人和活泼好动的狗子共度时光。

**Austin Welch **
Amazon ML Solutions Lab 的数据科学家。他开发自定义深度学习模型,帮助亚马逊云科技公共部门客户加快人工智能和云的采用。在业余时间,他喜欢阅读、旅行和柔术。


听说,点完下面4个按钮
就不会碰到bug了!

版权归原作者 亚马逊云开发者 所有, 如有侵权,请联系我们删除。