
Deephub
更多文章请关注公众号:Deephub-IMBA

论文解释:SeFa ,在潜在空间中为 GAN 寻找语义向量
SeFa — Closed-Form Factorization of Latent Semantics in GANs

优化算法之手推遗传算法(Genetic Algorithm)的详细步骤图解
遗传算法(Genetic Algorithm, GA)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。

5分钟 NLP :Hugging Face 主要类和函数介绍 🤗
主要包括Pipeline, Datasets, Metrics, and AutoClasses
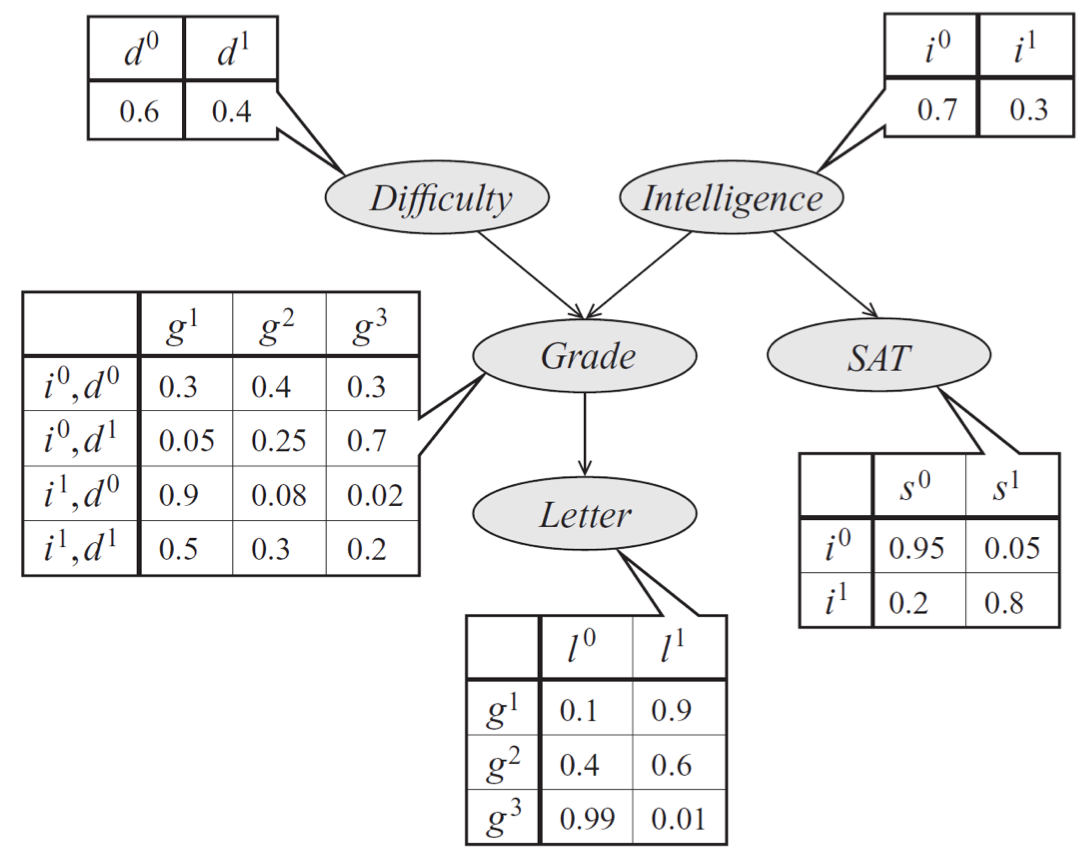
贝叶斯网络的D-separation详解和Python代码实现
D分离(D-Separation)又被称作有向分离,是一种用来判断变量是否条件独立的图形化方法。相比于非图形化方法,D-Separation更加直观且计算简单。
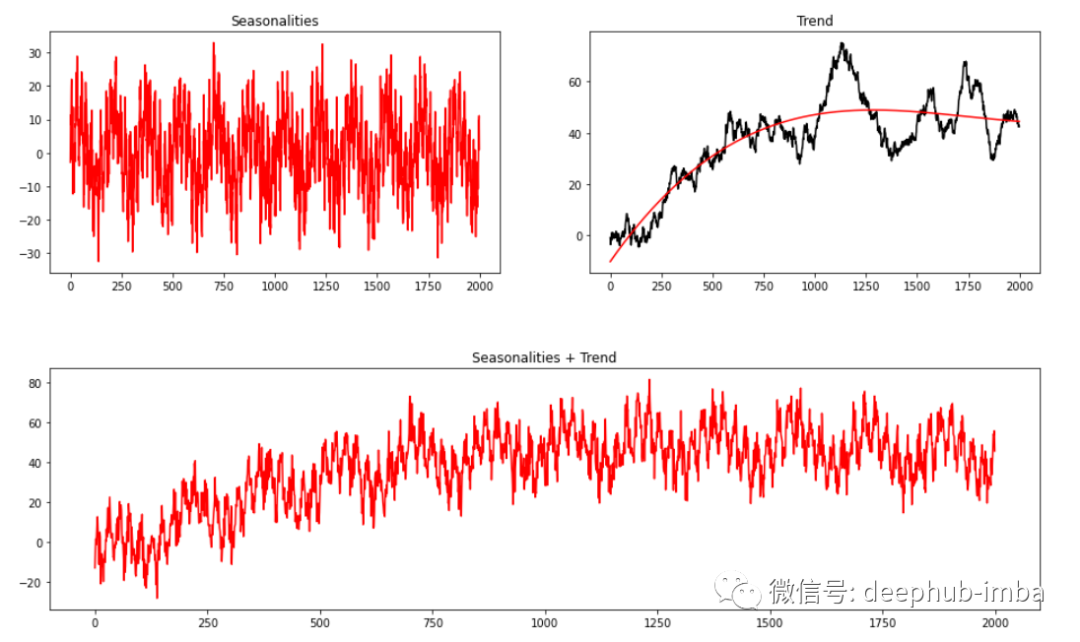
3种时间序列混合建模方法的效果对比和代码实现
本文中将讨论如何建立一个有效的混合预测器,并对常见混合方式进行对比和分析
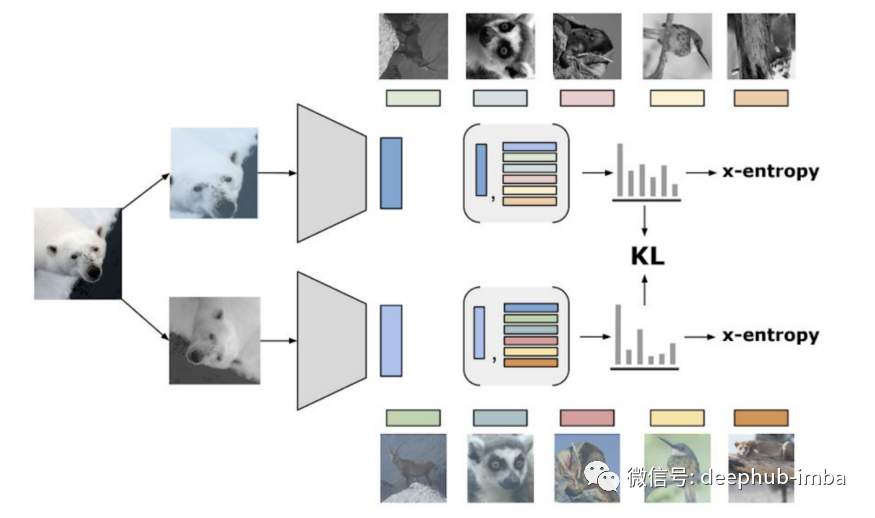
论文推荐:ReLICv2 ,新的自监督学习能否在ResNet 上超越监督学习?
自监督 ResNets 能否在 ImageNet 上没有标签的情况下超越监督学习?

深度特征合成与遗传特征生成,两种自动特征生成策略的比较
特征工程是从现有特征创建新特征的过程,本文中将通过一个示例比较两种自动特征生成的方法:DFS和GFG
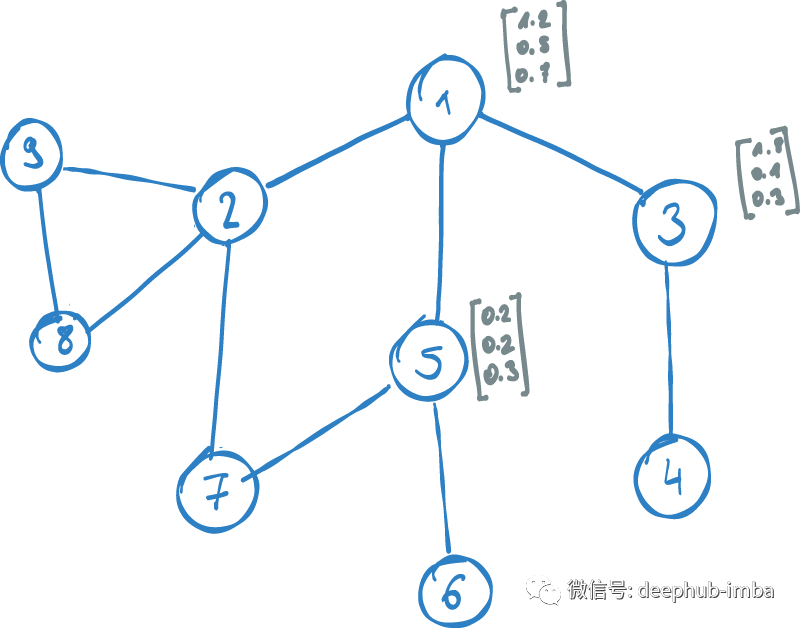
图嵌入中节点如何映射到向量
所有的机器学习算法都需要输入数值型的向量数据,图嵌入通过学习从图的结构化数据到矢量表示的映射来获得节点的嵌入向量。它的最基本优化方法是将具有相似上下文的映射节点靠近嵌入空间。
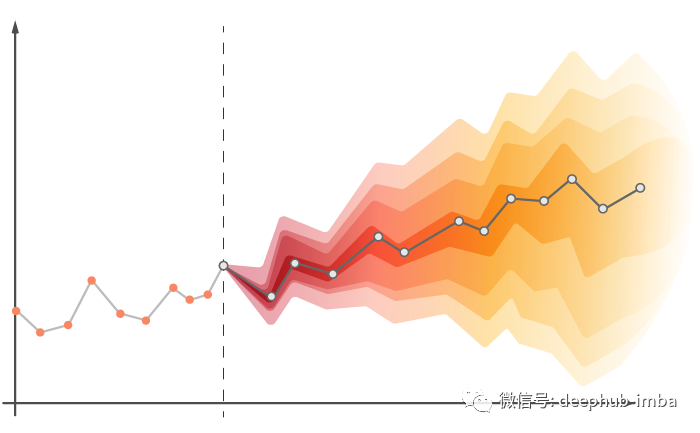
4大类11种常见的时间序列预测方法总结和代码示例
本篇文章将总结时间序列预测方法,并将所有方法分类介绍并提供相应的python代码示例
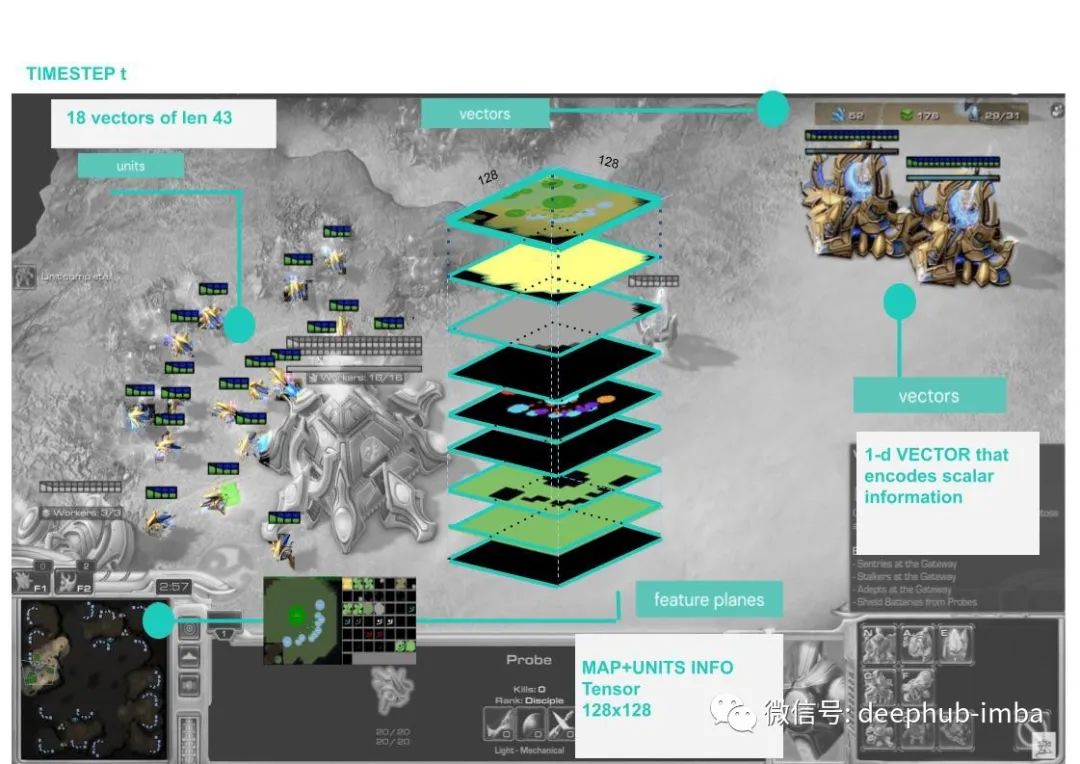
论文推荐:StarCraft II Unplugged 离线强化学习
在本文中,我们将介绍 StarCarft II Unplugged 论文 [1],本论文可以将AlphaStar进行了扩展或者说更好的补充解释,绝对值得详细阅读。
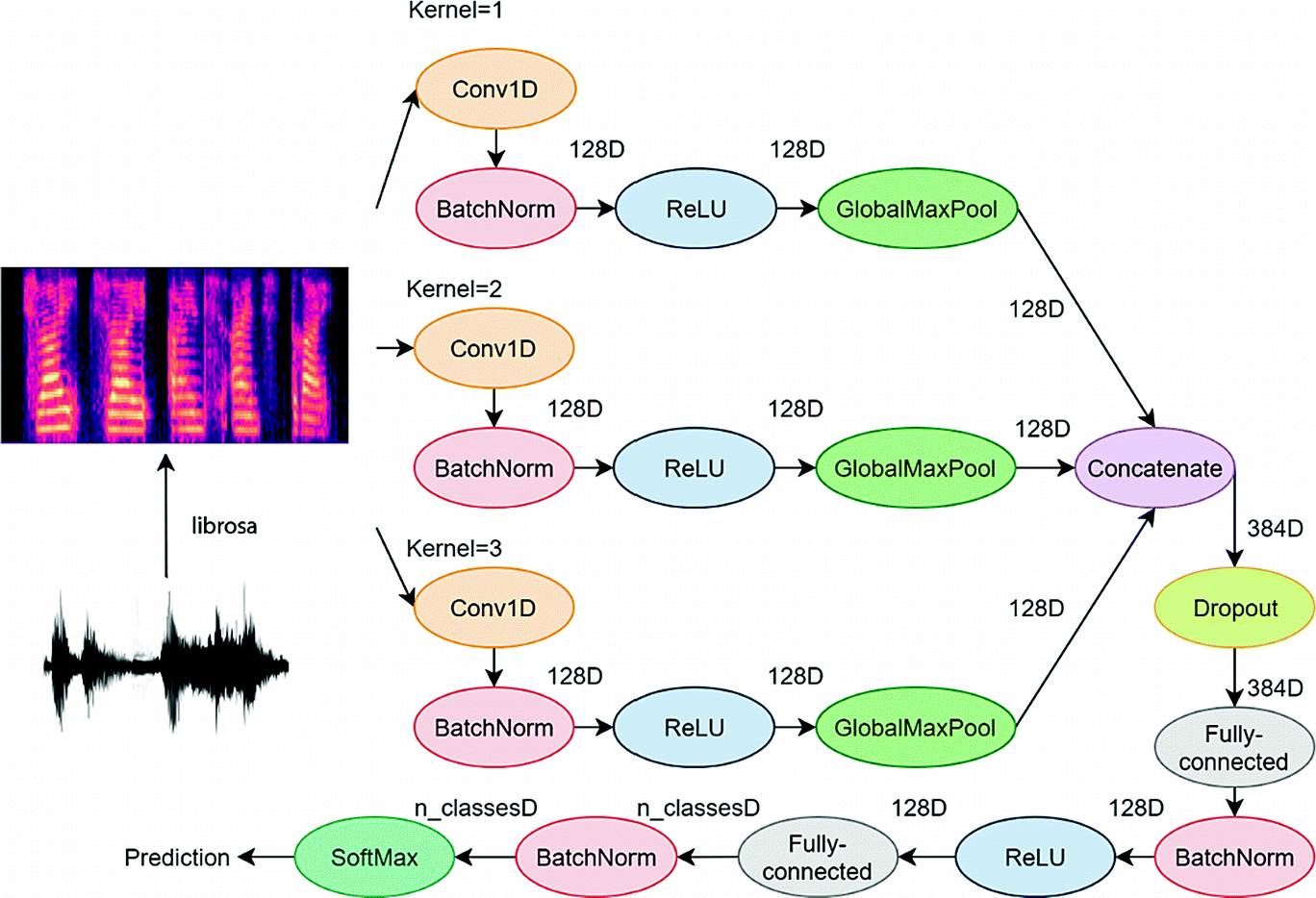
音频数据建模全流程代码示例:通过讲话人的声音进行年龄预测
从EDA、音频预处理到特征工程和数据建模的完整源代码演示
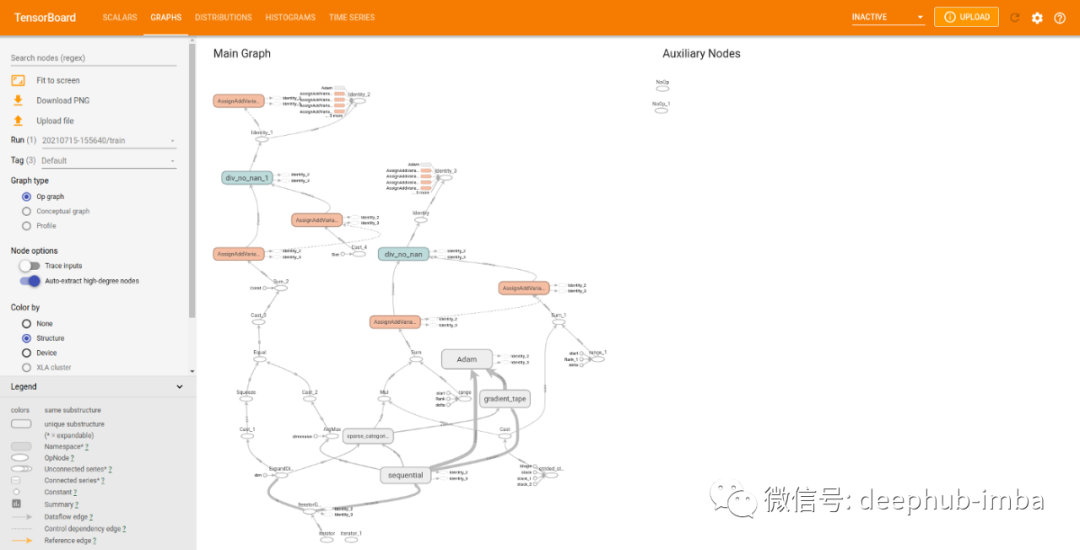
TensorBoard的最全使用教程:看这篇就够了
本文详细介绍了 TensorBoard 所有基本组件以及高级的功能,并推荐了常用插件和使用方法,提供与PyTorch结合使用的方法代码。
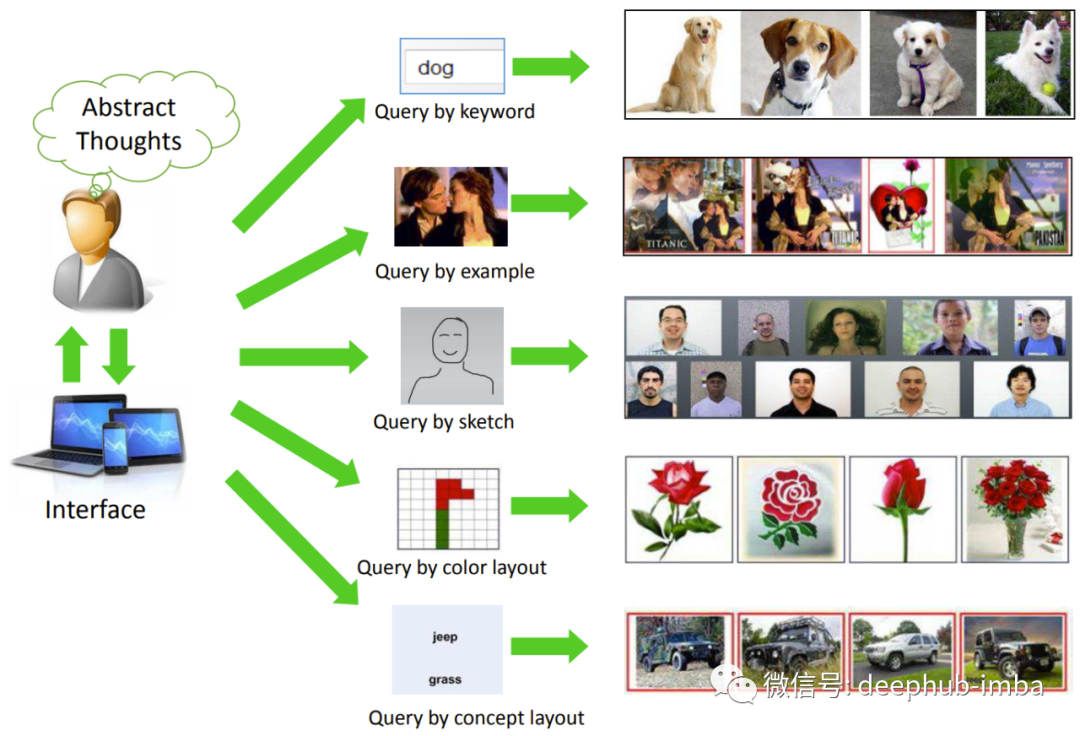
构建可以查找相似图像的图像搜索引擎的深度学习技术详解
在本文中将介绍如何查找相似图像的蛇毒学习理论基础并且使用一个用于查找商标的系统为例介绍相关的技术实现,阅读本文后你将有能够从头开始为创建类似图像的搜索引擎的能力。

5分钟NLP:快速实现NER的3个预训练库总结
在本文中,将介绍对文本数据执行 NER 的 3 种技术。这些技术将涉及预训练和定制训练的命名实体识别模型。
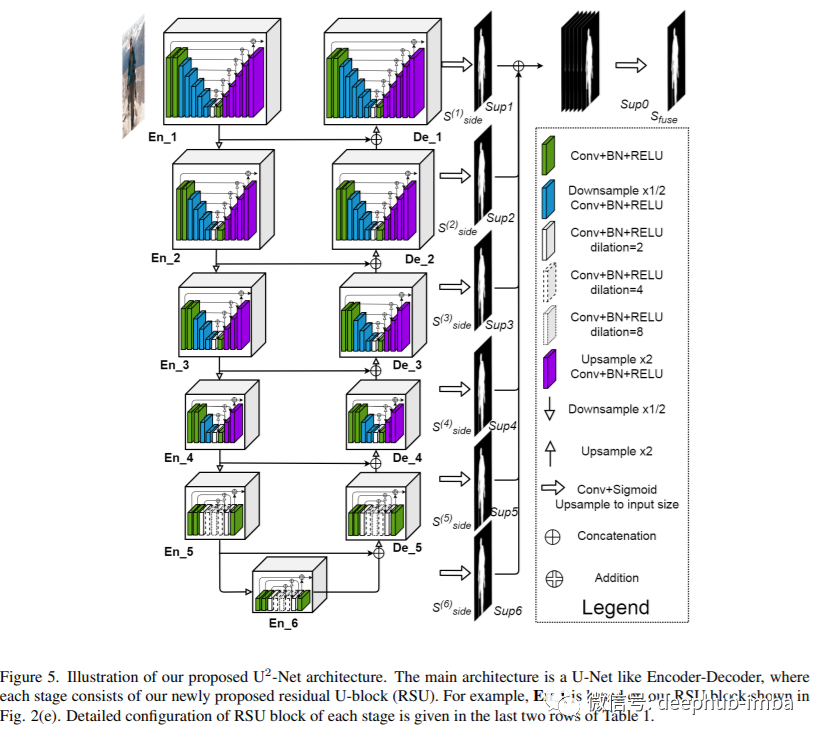
论文回顾:U2-Net,由U-Net组成的U-Net
在这篇文章中,我们将介绍2020年发布的一种称为 U²-Net 或 U-squared Net 的 U-net 变体。U²-Net基本上是由U-Net组成的U-Net。
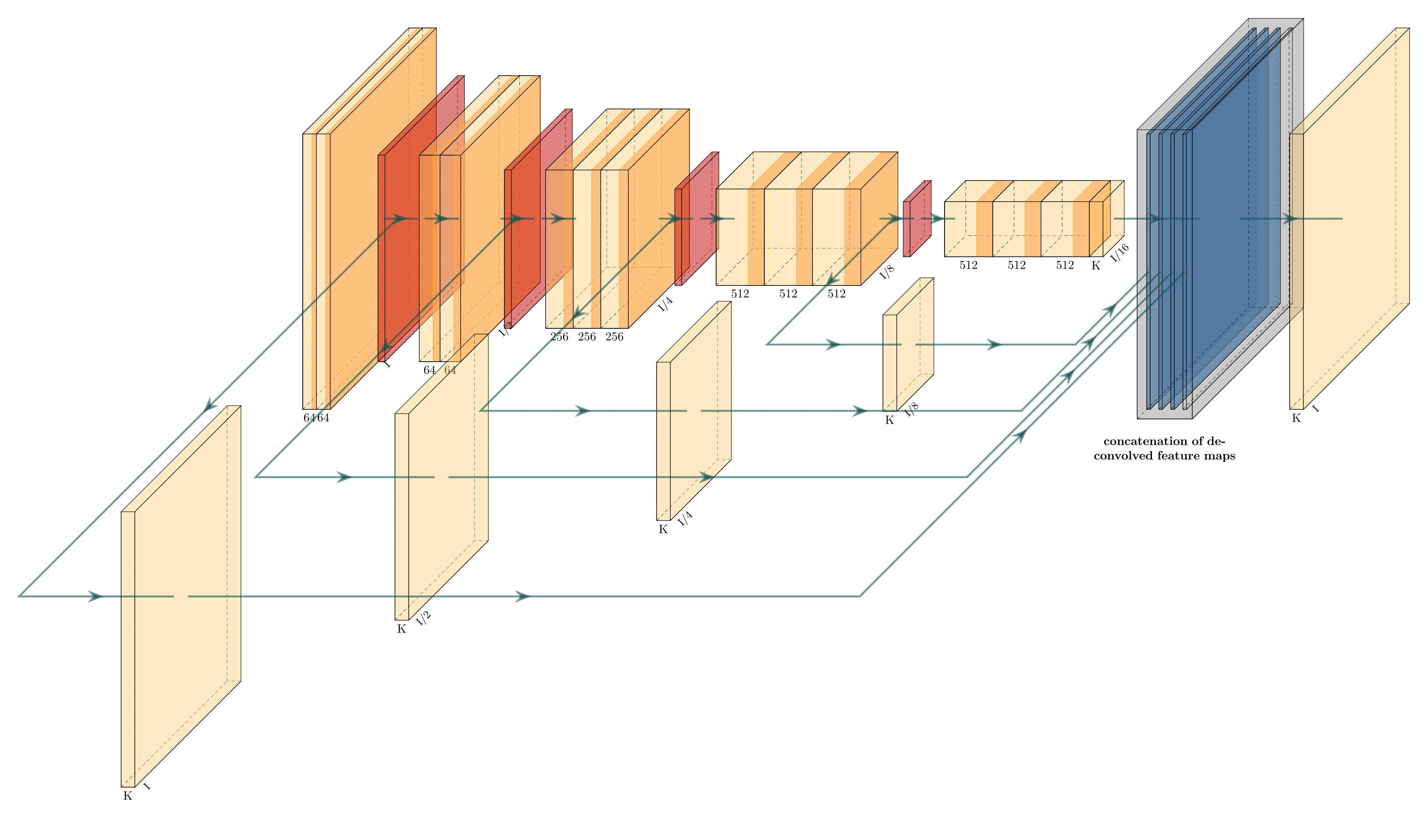
可视化深度学习模型架构的6个常用的方法总结
可视化有助于解释和理解深度学习模型的内部结构。本文将使用 Keras 和 PyTorch 构建一个简单的深度学习模型,然后使用不同的工具和技术可视化其架构。
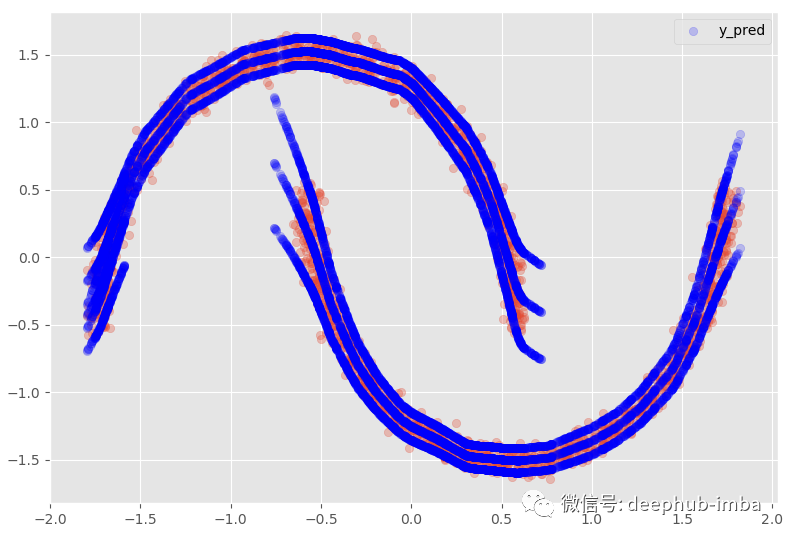
混合密度网络(MDN)进行多元回归详解和代码示例
在本文中,首先简要解释一下 混合密度网络 MDN (Mixture Density Network)是什么,然后将使用Python 代码构建 MDN 模型,最后使用构建好的模型进行多元回归并测试效果。
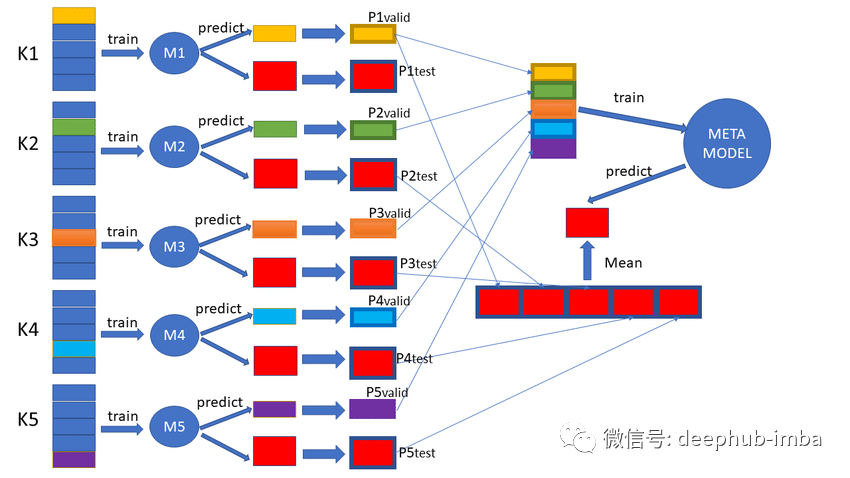
使用折外预测(oof)评估模型的泛化性能和构建集成模型
折外预测在机器学习中发挥着重要作用,可以提高模型的泛化性能。

集成学习中的软投票和硬投票机制详解和代码实现
集成方法是将两个或多个单独的机器学习算法的结果结合在一起,并试图产生比任何单个算法都准确的结果
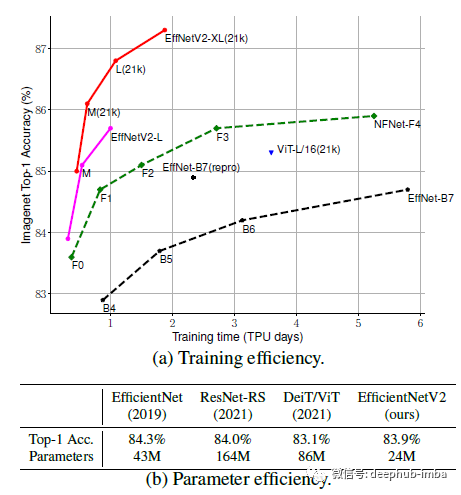
EfficientNetV2 - 通过NAS、Scaling和Fused-MBConv获得更小的模型和更快的训练
EfficientNetV2是由 Google Research,Brain Team发布在2021 ICML的一篇论文,比EfficientNetV1的训练速度快得多,同时体积小 6.8 倍。