
Deephub
更多文章请关注公众号:Deephub-IMBA
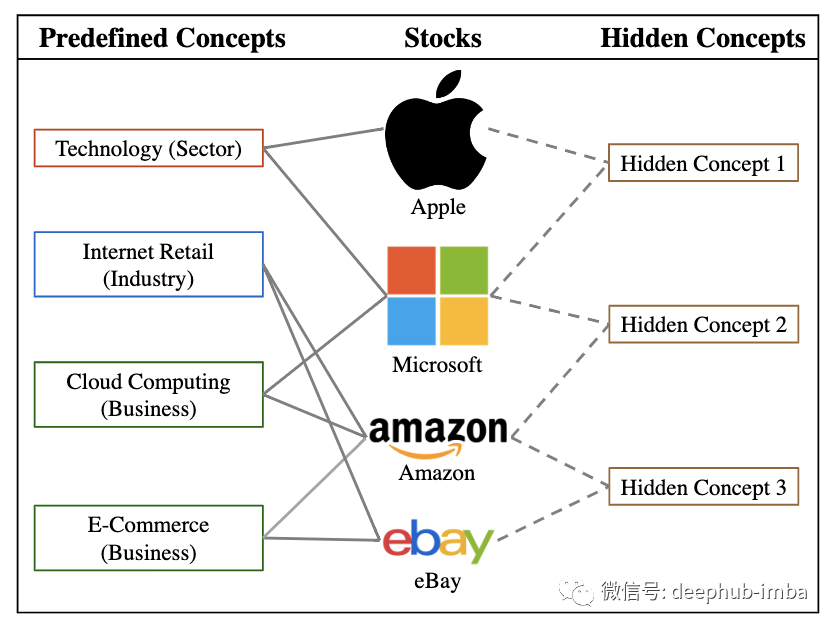
HIST:微软最新发布的基于图的可以挖掘面向概念分类的共享信息的股票趋势预测框架
2022 年 1 月微软研究院的提出了一种新颖的股票趋势预测框架,可以充分挖掘该概念面向来自预定义概念和隐藏概念的共享信息
2022 年 5 篇与降维方法的有关的论文推荐
本篇文章整理了2022年新发布的5篇与降维技术有关的文章
NLP 进行文本摘要的三种策略代码实现和对比:TextRank vs Seq2Seq vs BART
本文将使用 Python 实现和对比解释 NLP中的3 种不同文本摘要策略:老式的 TextRank(使用 gensim)、著名的 Seq2Seq(使基于 tensorflow)和最前沿的 BART(使用Transformers )
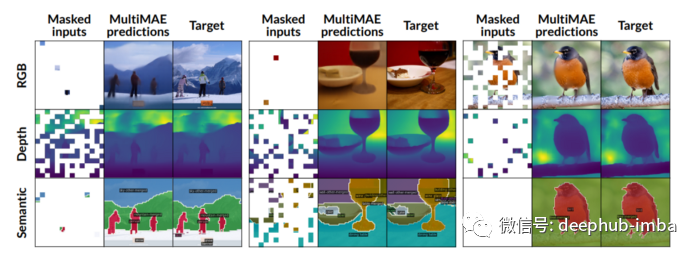
MultiMAE:一种简单、灵活且有效的 ViT 预训练策略
Multi-modal Multi-task Masked Autoencoders (MultiMAE),也是一种预训练策略,可以对掩码进行自动编码处理并执行多模态和多任务的训练。

自动化的机器学习:5个常用AutoML 框架介绍
AutoML 可以为预测建模问题自动找到数据准备、模型和模型超参数的最佳组合,本文整理了5个最常见且被熟知的开源AutoML 框架。
将梯度提升模型与 Prophet 相结合可以提升时间序列预测的效果
将Prophet的预测结果作为特征输入到 LightGBM 模型中进行时序的预测

2022 年 4 月 10篇 ML 研究论文推荐
Google 的 5400 亿参数 PaLM、Pathways、Kubric、Tensor Programs、Bootstrapping Reasoning With Reasoning、Sparse all-MLP 架构
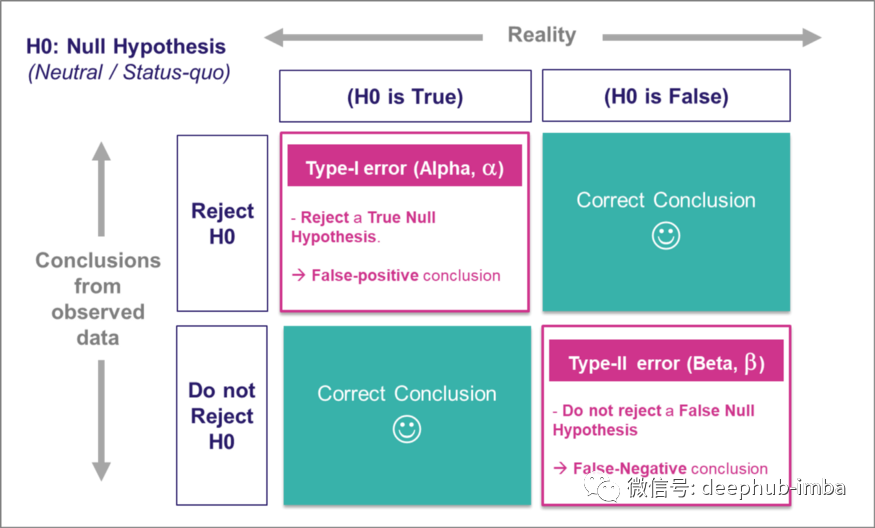
假设检验中的第一类错误和第二类错误
这是支撑统计学中假设检验的最重要概念
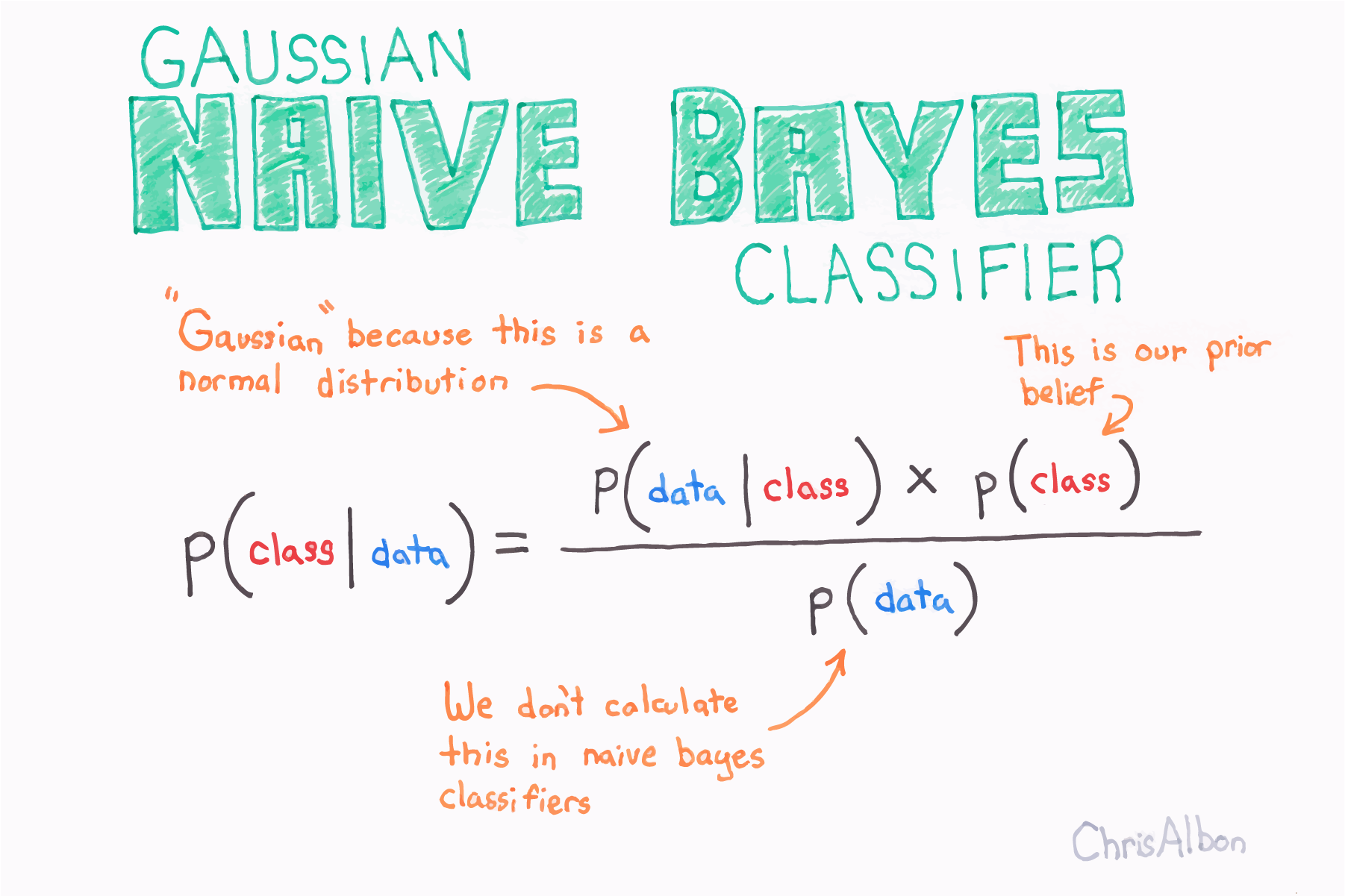
高斯朴素贝叶斯分类的原理解释和手写代码实现
朴素贝叶斯假设每个参数(也称为特征或预测变量)具有预测输出变量的独立能力。所有参数的预测组合是最终预测,它返回因变量被分类到每个组中的概率,最后的分类被分配给概率较高的分组(类)。
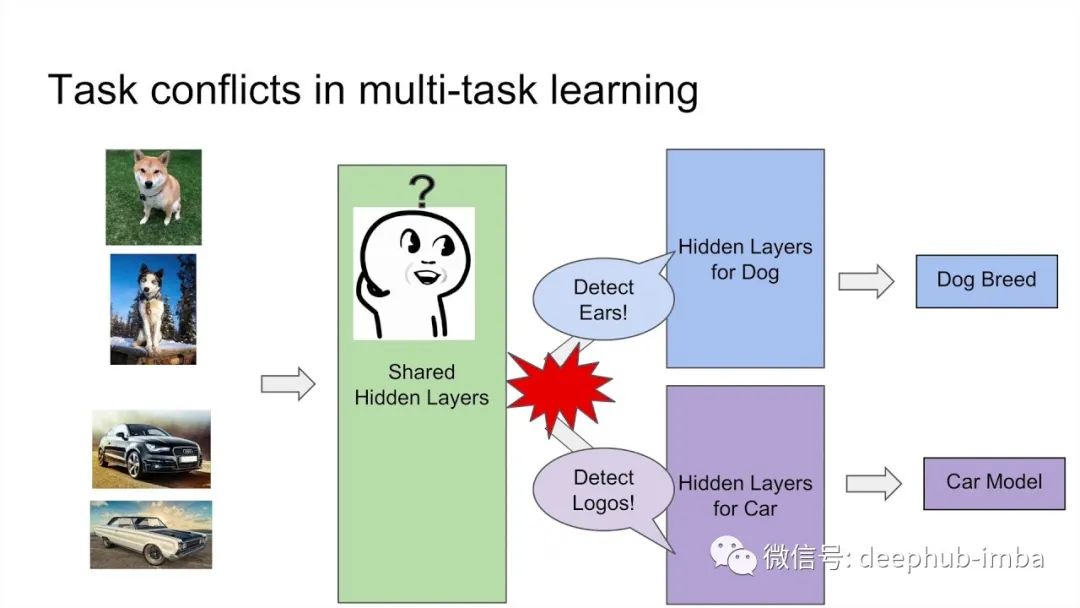
多任务学习中的网络架构和梯度归一化
多任务学习(Multi-task learning, MTL),旨在用其他相关任务来提升主要任务的泛化能力,多个任务共享一个结构并在一次正向传递中产生多个推理。
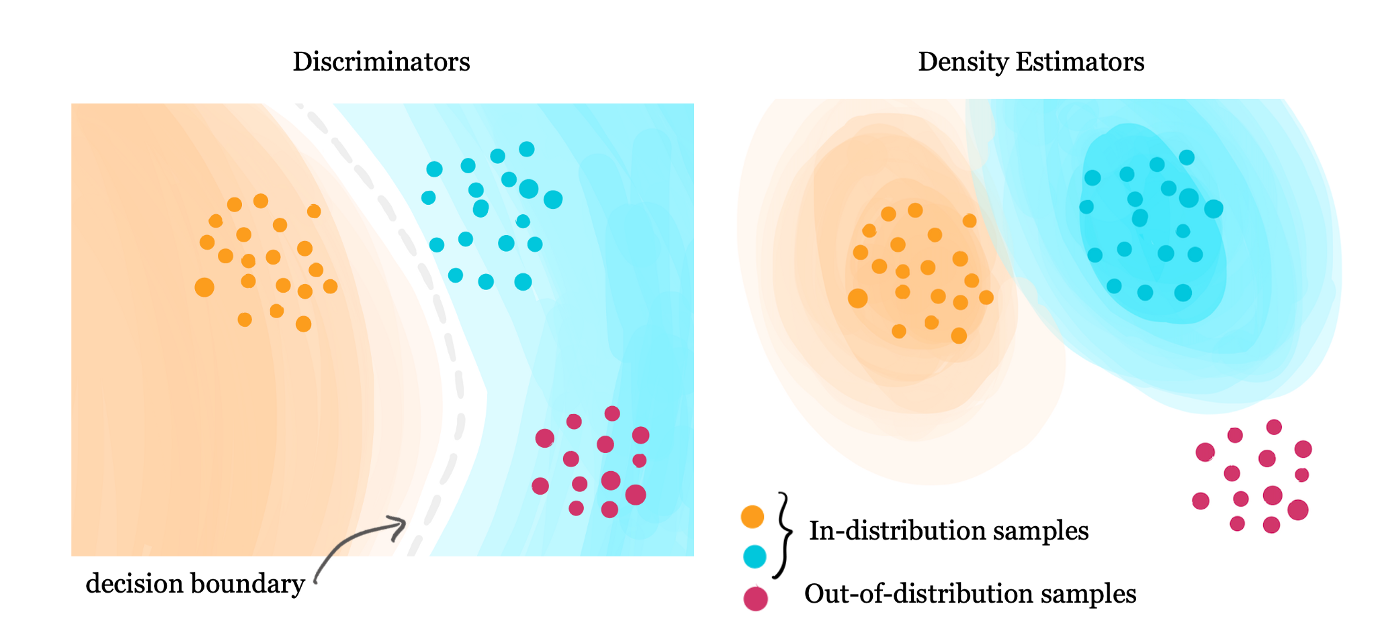
使用分布外数据去除不需要的特征贡献,提高模型的稳健性
分布外数据增强训练可以提高 DNN 的准确性和效率,通过抗性训练可以让 DNN 更加健壮,让模型更不容易受到扰动的影响。
计算机视觉的半监督模型:Noisy student, π-Model和Temporal Ensembling
今天我将讨论一些在过去十年中出现的主要的半监督学习模型。

JoJoGAN One-Shot Face Stylization:使用 StyleGAN 创建 JoJo风格人脸头像
JoJoGAN 是一种One-Shot风格迁移模型,可让将人脸图像的风格迁移为另一种风格。
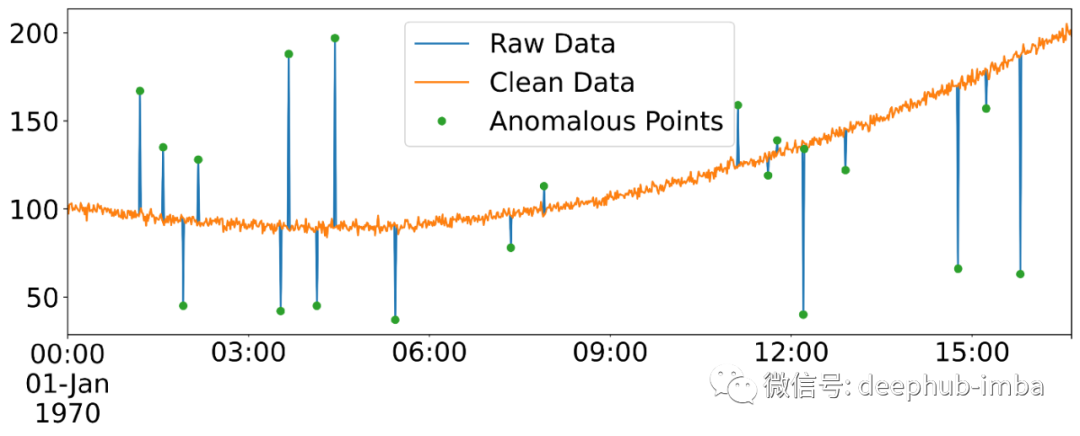
用于时间序列异常检测的学生化残差( studentized residual)的理论和代码实现
学生化这个词其实就是studentized的中文直译,因为约定俗成了所以也没什办法,studentized就是把其他分布转换成t分布,所以其实 studentized residual 翻译为 化残差,要比 学生化残差 更自然,也更好理解

深度学习项目示例 使用自编码器进行模糊图像修复
本文将介绍使用深度学习技术实现一个对图像进行去模糊处理的项目的完整流程,希望对你有所帮助

用于Transformer的6种注意力的数学原理和代码实现
Transformer 的出色表现让注意力机制出现在深度学习的各处。本文整理了深度学习中最常用的6种注意力机制的数学原理和代码实现。

深度学习的显卡对比评测:2080ti vs 3090 vs A100
显卡大幅降价了但是还可以再等等,新的40系列显卡也要发售了,所以我们先看看目前上市的显卡的性能对比,这样也可以估算下40显卡的性能,在以后购买时作为参考。

5篇关于强化学习在金融领域中应用的论文推荐
近年来机器学习在各个金融领域各个方面均有应用,其实金融领域的场景是很适合强化学习应用
使用 Python 进行数据清洗的完整指南
在本文中将列出数据清洗中需要解决的问题并展示可能的解决方案,通过本文可以了解如何逐步进行数据清洗。
7种不同的数据标准化(归一化)方法总结
本文总结了 7 种常见的数据标准化(归一化)的方法。