
ViLBERT(Lu et al.2019)代表视觉与语言BERT。听起来确实像是BERT模型的一个版本(Devlin等人,2018年),该模型很快就变成了NLP任务的SOTA,并集成了视觉输入。ViLBERT是用于多模态任务,如视觉问答(VQA)和参考表达式。
方法总结
该模型有效地继承了BERT模型,BERT模型的许多部分在该方法中保持不变。
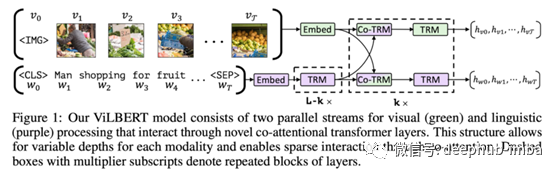
首先分别处理图像和文本输入。文本编码使用几个Transformer层独立于图像特征。所述图像特征被嵌入可输入到Transformer中;边界框用于查找和选择图像区域,向量用于存储每个编码图像区域的空间位置。接下来,引入共同注意力Transformer层,其中共同注意力用于学习文本输入中的单词和图像中区域之间的映射。该模型生成一个隐藏表示,可以用作多个多模式任务的起点。
ViLBERT首先在标签生成数据集上接受训练,该数据集包含与图像内容相关的标题图像。完成这一阶段后,可以对模型进行微调,以执行VQA等其他任务。
我觉得最有趣的是
这种方法的许多部分并不新颖。图像和文本之间的共同注意力在以前已经被探索过。此外,这是一种迁移学习方法,该模型从概念字幕数据集中的330万对图像-字幕对中学习,然后进行微调,以在较小的数据集执行特定任务。这种迁移学习已经被证明在视觉和自然语言处理环境中都有效。不用说,我发现许多部分令人兴奋,因为这是我正在阅读的多模态学习的第一篇论文之一。
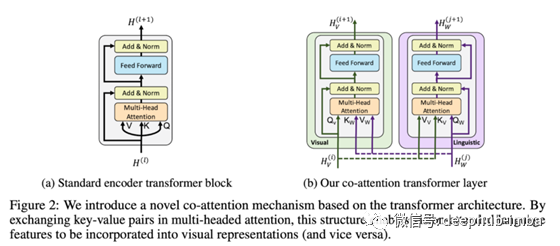
共同注意力是一个很有趣的话题。这是对我们在ML模型中看到的通常注意力机制的一个简单修改。简单地说,注意力是一种方法,模型可以在得出预测的同时查看输入的一部分或隐藏的表示。在共同注意力中,这种注意被扩展到关注不同形态的特征,即图像的共同转换块看到来自编码文本的表示,反之亦然。这里有很多与Transformer模型相关的细节,我现在将其省略。
结果表明,该模型适用于多模式任务。我认为这是Transformer架构和BERT的又一次胜利。但我也认为这是许多未来工作的基础——如果进行更多的微调和修改,这个模型将在许多特定任务上表现得更好。

为什么你应该(我)感到兴奋?
继CNN之后,Transformers 似乎是机器学习应用的下一个重大进展。
该模型很好地实现了图像与文字的视觉基础匹配。我最兴奋的是看到这样一个模型将如何执行参考图像分割,其中输出是一个完整的分割掩码。一个修改的解码器和/或一个单独的分割管道可能需要得到细化的结果。
作者:Aditya Chinchure
deephub翻译组