
像numpy这样的软件包是当今数据科学工作的主要来源。然而,我们可能会遇到numpy无法轻松处理或只能以次优方式处理的情况

我最近遇到过这样的情况:在实现一个概率矩阵分解(PMF)推荐系统时,我必须将许多对矩阵U和V.T相乘,我的jupyte内核在调用numpy.tensordot来实现我的目标时崩溃了。
我不满足于在多核机器上一个接一个地乘矩阵,我转向jax。jax库被DeepMind(即AlphaGo音乐)和谷歌研究人员用于他们的日常工作——主要是在深度学习方面——并且围绕着它出现了一个丰富的生态系统。
在jax的优点中,我在这里关心的是它可以很容易地向量化(纯)函数,通过底层的并行化实现加速。因此,加速的代码可以在cpu、gpu和/或tpu上执行而无需修改!
问题陈述
为了具体化,这里是U和Vt的形状。它们是成批的矩阵,而不是成批的行,由于表格数据的流行,成批的行更常见。U和Vt分别包含100个矩阵,
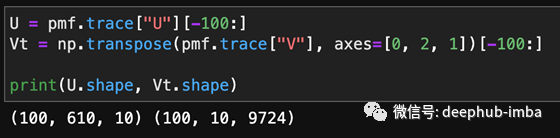
我想把每一对对应的矩阵相乘得到R,它的形状是(300 610,9724)换句话说,将U[0]与Vt[0]相乘,将U[1]与Vt[1]相乘,将U[300]与Vt[300]相乘。
然后,我要在0轴上求平均值——所有的300个R矩阵——最后得到一个610 × 9724的矩阵。
基准测试
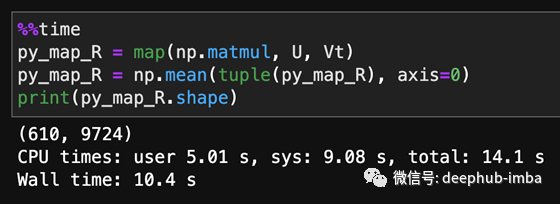
作为基线,让Python逐个乘以这些矩阵,然后在轴0上求平均值。在我2015年的Macbook Pro上,这只花了大约10秒,它有16g内存和Intel i7 cpu。
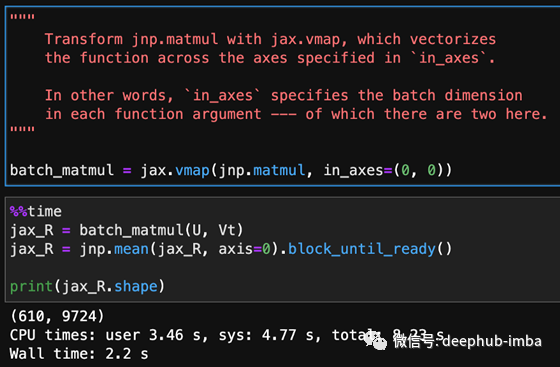
相比之下,如下图所示,jax完成同样的操作只需要2.2秒!注意,我必须在jnp.mean()之后添加.block_until_ready()以获得一个有意义的基准测试,因为jax遵循的是惰性/异步计算。
最后(但并非最不重要),当我将批处理中的矩阵数量从100增加到150时,上述运行时的伸缩方式不同。朴素序贯计算耗时50秒,而jax仅需3秒。换句话说,当问题需要更多内存时,使用jax的好处就显现出来了。
总结
也许有一种简单的方法可以在numpy中完成我想做的事情,但是使用jax也很简单——附加的好处是在设备类型和内存使用方面具有巨大的可伸缩性。
虽然jax有自己的数组数据类型,但它是numpy的一个子类。Ndarray和jax可以与现有的numpy工作流集成。
作者:Everest Law
deephub翻译组