
在这篇文章中,我们将首先看看Lasso和Ridge回归中一些常见的错误,然后我将描述我通常采取的步骤来优化超参数。代码是用Python编写的,我们主要依赖scikit-learn。本文章主要关注Lasso的例子,但其基本理论与Ridge非常相似。
起初,我并没有真正意识到需要另一个关于这个主题的指南——毕竟这是一个非常基本的概念。然而,当我最近想要确认一些事情时,我意识到,市面上的很多文章要么太学术化,要么太简单,要么就是完全错误。一个很常见的混淆来源是,在sklearn中总是有十多种不同的方法来计算同一件事情。
所以,废话少说,下面是我对这个话题的两点看法。
快速的理论背景回顾
Lasso和Ridge都是正则化方法,他们的目标是通过引入惩罚因子来正则化复杂的模型。它们在减少过拟合、处理多重共线性或自动特征工程方面非常出色。这听i来似乎有点神奇,但通过训练使模型更努力地拟合数据,我们得到一个更好的对底层结构的了解,从而对测试数据有了更好的泛化和更好的拟合。
LinearRegression
根据sklearn的公式,这是线性回归模型中最小的表达式,即所谓的普通最小二乘:
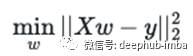
其中X矩阵为自变量,w为权重即系数,y为因变量。
Ridge
Ridge回归采用这个表达式,并在平方系数的最后添加一个惩罚因子:
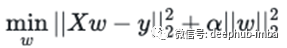
这里α是正则化参数,这是我们要优化的。该模型惩罚较大的系数,并试图更平均地分配权重。用外行人的话来说,这就是Ridge模型所做的:
X1,我们看到你做得很好,如果不是因为惩罚的因素,我们会很重视你。但是X2只比你们差一点点,如果我们在你们俩之间均分权重,我们会得到更低的惩罚,从而得到更好的总分。
Lasso
Lasso做了类似的事情,但使用绝对值之和(l1范数)的权重作为惩罚。
注: sklearn提供公式中还有一个n_samples,这是观察的数量,并且应该改变X和y。我发现没有解释这是为什么,也许是为了比较不同模型。
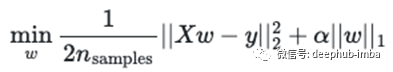
Lasso将开始降低不那么重要的变量的系数,也有可能将系数降低到0。通俗的说:
X1,你对总分数的最小贡献会被注意到。但是,根据最新的罚分,我们将不得不将你从回归中移除。
Elastic Net
值得注意的是,您还可以将同一模型中的两个惩罚与Elastic Net结合起来。您需要在那里优化两个超参数。在本指南中,我们将不讨论此选项。
所需要的类库
以下是需要的所有库的列表:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import \
r2_score, get_scorer
from sklearn.linear_model import \
Lasso, Ridge, LassoCV,LinearRegression
from sklearn.preprocessing import \
StandardScaler, PolynomialFeatures
from sklearn.model_selection import \
KFold, RepeatedKFold, GridSearchCV, \
cross_validate, train_test_split
三个秘诀
在本节中,我们将讨论一些常规技巧和常见错误,以避免涉及正则化回归。这些示例使用的是波士顿住房数据,您可以从Kaggle下载数据。
column_names = \
['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE',\
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV']
data = pd.read_csv("../datasets/housing.csv", \
header=None, delimiter=r"\s+", names=column_names)
y = data['MEDV']
X = data.drop(['MEDV'], axis = 1)
秘诀一:缩放自变量
如标题所示:需要缩放变量以进行正则回归。(我们知道,像缩放这样的线性变换不会对原始线性回归的预测产生影响。)很明显,如果您仔细查看一下公式,为什么必须对正则回归进行缩放:变量恰好在很小的范围内,其系数会很大,因此,由于惩罚会受到更大的惩罚。反之亦然,大规模变量将获得较小的系数,并且受惩罚的影响较小。Lasso and Ridge都是如此。
假设您执行以下操作。
(同样,该示例没有缩放比例,将不会产生正确的结果,请不要这样做。此外,请注意,除了缩放比例以外,还有其他问题,我们将在近期内再次讨论。)
# 错误,不要使用
cv = RepeatedKFold(n_splits=10, n_repeats=3, random_state=1)
lasso_alphas = np.linspace(0, 0.2, 21)lasso = Lasso()
grid = dict()
grid['alpha'] = lasso_alphas
gscv = GridSearchCV( \
lasso, grid, scoring='neg_mean_absolute_error', \
cv=cv, n_jobs=-1)
results = gscv.fit(X, y)print('MAE: %.5f' % results.best_score_)
print('Config: %s' % results.best_params_)
结果如下:
MAE: -3.37896
Config: {'alpha': 0.01}
但是,如果事先缩放X变量,通常会获得更好的分数。要缩放,我们可以使用sklearn的StandardScaler。此方法使变量以0为中心,并使标准偏差等于1。
sc = StandardScaler()X_scaled = sc.fit_transform(X)
X_scaled = pd.DataFrame(data = X_scaled, columns = X.columns)
如果在上面的代码块中用X_scaled替换X,我们将得到:
MAE: -3.35080
Config: {'alpha': 0.08}
是的,没有太大的改进,但这是由于许多因素,我们将在后面看到。最重要的是,波士顿的住房数据是一个很好的,经过量身定制的线性回归的示例,因此我们不能做太多改进。
总结:在进行正则化之前,使用StandardScaler缩放自变量。无需调整因变量。
秘诀二:当Alpha等于零时…
如果在Lasso和Ridge中为alpha参数选择0,则基本上是在拟合线性回归,因为在公式的OLS部分没有任何惩罚。
由于计算复杂性,sklearn文档实际上不建议使用alpha = 0的参数运行这些模型。因为他可能引起算问题,但我还没有遇到过这种情况,因为它总是给出与LinearRegression模型相同的结果。
总结:选择alpha = 0毫无意义,这只是线性回归。
秘诀三:多次尝试
在上面的示例中,我们浏览了一系列Alpha,对它们进行了全部尝试,然后选择了得分最高的Alpha。但是,像往常一样,当您使用GridSearchCV时,建议进行多次尝试。找到最高Alpha的区域,然后进行更详细的检查。
以我的经验,尤其是在使用Lasso时,选择最低的非零参数是一个常见的错误,而实际上,最佳参数要小得多。请参阅下面的示例。
注意:当然,我们永远不会使用网格搜索方法找到实际的最佳数字,但是我们可以足够接近。
您还可以可视化结果。这是未缩放版本的样子:
对于每个Alpha,GridSearchCV都适合模型,我们选择了Alpha,其中验证数据得分(例如,RepeatedKFold中测试折叠的平均得分)最高。在此示例中,您可以看到0到0.01之间可能没有疯狂的峰值。当然,这仍然是错误的,因为我们没有缩放。
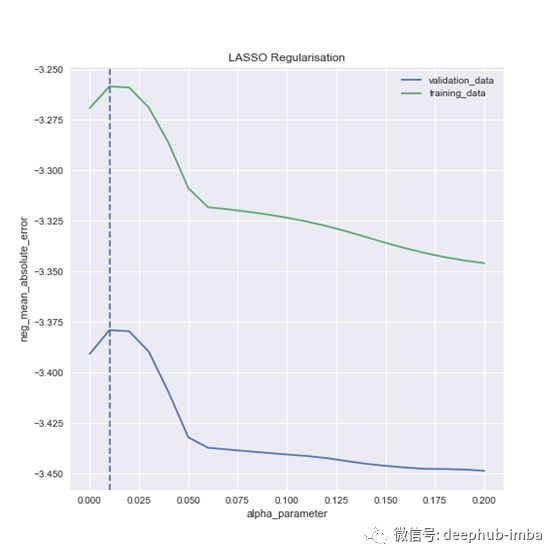
这是缩放版本的图:
再次看起来不错,在0.07和0.09之间可能没有任何奇怪的事情发生。
总结:可视化是你的朋友,请观察alpha曲线。确保您选择的Alpha位于漂亮的“弯曲”区域。
秘诀四:仔细考虑您的计分方法
您可能很想以其他方式进行计算以检查结果。如前所述,sklearn通常有很多不同的方法来计算同一件事。首先,有一个LassoCV方法将Lasso和GridSearchCV结合在一起。
您可以尝试执行以下操作以获得最佳Alpha(示例中不再使用未缩放的版本):
lasso = LassoCV(alphas=lasso_alphas, cv=cv, n_jobs=-1)
lasso.fit(X_scaled, y)
print('alpha: %.2f' % lasso.alpha_)
结果如下:
alpha: 0.03
等一下,难道不是上面的0.08的相同数据的Alpha吗?是的。差异的原因是什么?LassoCV使用R²得分,您无法更改它,而在更早的时候,我们在GridSearchCV对象中指定了MAE(正负MAE,但这只是为了使我们最大化并保持一致)。这是为什么说上个代码错误的原因:
scoring='neg_mean_absolute_error'
问题是,sklearn有数十种计分方法,您也可以选择max_error来衡量模型的性能。但是,该模型针对平方差进行了优化。但是我认为使用从平方差得出的任何东西都更加一致。,因为LassoCV使用R²,所以也许这是一个好的信号?
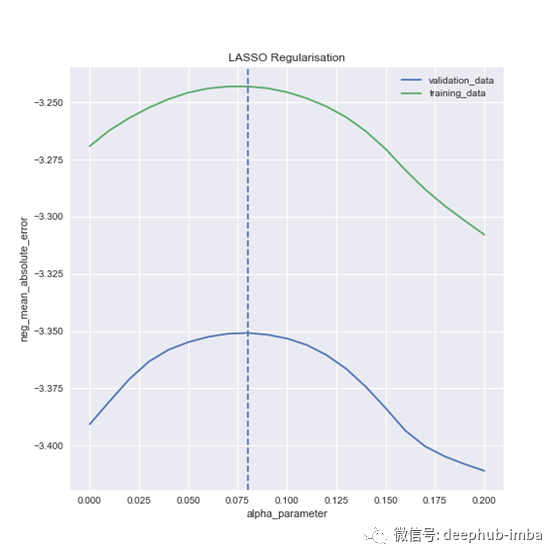
“在一个基础上进行优化,然后在另一个基础上进行性能比较”实际上在上面的图表中是很明显的。注意绿线的评分高了很多。那是因为这是训练的成绩。在正常情况下,施加惩罚因素后,它的性能不应更好。
通常,这就是您将看到的曲线的形状。训练数据得分立即下降,验证数据得分上升一段时间,然后下降:
总结:使用R²或另一个基于差异的平方模型作为回归的主要评分。
本文的方法
在这一节中,我将介绍我用来准备数据和拟合正则化回归的方法。
在得到X和y之前,我不会详细说明数据。我使用来自美国县级国家健康排名数据收集的一个版本来生成下面的结果,但对于这个示例来说,这真的无关紧要。
因此,假设您有一个漂亮而干净的X和y,下一步是使用方便的train_test_split留出一个测试数据集。如果想让结果重现,可以为my_random_state选择任何数字。
X_train , X_test, y_train, y_test = train_test_split(
X, y, test_size=1000, random_state=my_random_state)
下一步是包含多项式特性。我们将结果保存在多边形对象中,这很重要,我们将在以后使用它。
poly = PolynomialFeatures(
degree = 2, include_bias = False, interaction_only = False)
这将产生变量的所有二阶多项式组合。需要注意的是,我们将include_bias设置为False。这是因为我们不需要截距列,回归模型本身将包含一个截距列。
这是我们转换和重命名X的方法。它假设您将X保存在一个pandas DataFrame中,并且需要进行一些调整以保持列名可用。如果你不想要名字,你只需要第一行。
X_train_poly = poly.fit_transform(X_train)
polynomial_column_names = \
poly.get_feature_names(input_features = X_train.columns)
X_train_poly = \
pd.DataFrame(data = X_train_poly,
columns = polynomial_column_names )
X_train_poly.columns = X_train_poly.columns.str.replace(' ', '_')
X_train_poly.columns = X_train_poly.columns.str.replace('^', '_')
完成这一步后,下一步是扩展。在引入多项式之后,这就更加重要了,没有缩放,大小就会到处都是。
sc = StandardScaler()
X_train_poly_scaled = sc.fit_transform(X_train_poly)
X_train_poly_scaled = pd.DataFrame( \
data = X_train_poly_scaled, columns = X_train_poly.columns)
棘手的部分来了。如果我们想要使用测试数据集,我们需要应用相同的步骤。
但是,我们不需要再次适合这些对象。好吧,对于poly无所谓,但是对于sc,我们想要保留用于X_train_poly的方法。是的,这意味着测试数据不会完全标准化,这很好。我们用transform代替fit_transform。
X_test_poly = poly.transform(X_test)
X_test_poly_scaled = sc.transform(X_test_poly)
您可能想知道如何生成上面使用的图。我使用两个函数,构建在上面列出的库之上。第一个函数绘制一个图:
def regmodel_param_plot(
validation_score, train_score, alphas_to_try, chosen_alpha,
scoring, model_name, test_score = None, filename = None):
plt.figure(figsize = (8,8))
sns.lineplot(y = validation_score, x = alphas_to_try,
label = 'validation_data')
sns.lineplot(y = train_score, x = alphas_to_try,
label = 'training_data')
plt.axvline(x=chosen_alpha, linestyle='--')
if test_score is not None:
sns.lineplot(y = test_score, x = alphas_to_try,
label = 'test_data')
plt.xlabel('alpha_parameter')
plt.ylabel(scoring)
plt.title(model_name + ' Regularisation')
plt.legend()
if filename is not None:
plt.savefig(str(filename) + ".png")
plt.show()
第二个本质上是一个网格搜索,带有一些额外的东西:它也运行测试分数,当然还保存。
def regmodel_param_test(
alphas_to_try, X, y, cv, scoring = 'r2',
model_name = 'LASSO', X_test = None, y_test = None,
draw_plot = False, filename = None):
validation_scores = []
train_scores = []
results_list = []
if X_test is not None:
test_scores = []
scorer = get_scorer(scoring)
else:
test_scores = None
for curr_alpha in alphas_to_try:
if model_name == 'LASSO':
regmodel = Lasso(alpha = curr_alpha)
elif model_name == 'Ridge':
regmodel = Ridge(alpha = curr_alpha)
else:
return None
results = cross_validate(
regmodel, X, y, scoring=scoring, cv=cv,
return_train_score = True)
validation_scores.append(np.mean(results['test_score']))
train_scores.append(np.mean(results['train_score']))
results_list.append(results)
if X_test is not None:
regmodel.fit(X,y)
y_pred = regmodel.predict(X_test)
test_scores.append(scorer(regmodel, X_test, y_test))
chosen_alpha_id = np.argmax(validation_scores)
chosen_alpha = alphas_to_try[chosen_alpha_id]
max_validation_score = np.max(validation_scores)
if X_test is not None:
test_score_at_chosen_alpha = test_scores[chosen_alpha_id]
else:
test_score_at_chosen_alpha = None
if draw_plot:
regmodel_param_plot(
validation_scores, train_scores, alphas_to_try, chosen_alpha,
scoring, model_name, test_scores, filename)
return chosen_alpha, max_validation_score, test_score_at_chosen_alpha
我不想在这里讲得太详细,我认为这是不言自明的,稍后我们会看到如何调用它的例子。
有一件事,我认为非常酷:sklearn有一个get_scorer函数,它根据sklearn字符串代码返回一个scorer对象。例如:
scorer = get_scorer('r2')
scorer(model, X_test, y_test)
现在我们有另外一种方法来计算相同的东西。
一旦建立了这样的进程,我们所需要做的就是为不同的alpha数组运行函数。
这个过程的一个有趣之处在于,我们也在绘制测试分数:
- 取训练数据集和alpha值;
- 进行交叉验证,保存培训和验证分数;
- 假设这是我们选择并拟合模型的alpha值,而不需要对整个训练数据进行交叉验证;
- 计算该模型将对测试数据实现的分数,并保存测试分数。
这不是您在“现实生活”中会做的事情(除非您参加Kaggle竞赛),因为现在有了优化测试数据集的可能性。我们在这里仅仅是为了说明模型的性能。红线表示的是不同alpha的测试分数。
我们还需要一个交叉验证对象,这里没有一个好的答案,这是一个选项:
cv = KFold(n_splits=5, shuffle=True, random_state=my_random_state)
为了说明我关于多步参数搜索的重要性的观点,让我们假设我们想要检查这些alpha:
lasso_alphas = np.linspace(0, 0.02, 11)
运行函数后:
chosen_alpha, max_validation_score, test_score_at_chosen_alpha = \
regmodel_param_test(
lasso_alphas, X_train_poly_scaled, y_train,
cv, scoring = 'r2', model_name = 'LASSO',
X_test = X_test_poly_scaled, y_test = y_test,
draw_plot = True, filename = 'lasso_wide_search')
print("Chosen alpha: %.5f" % \
chosen_alpha)
print("Validation score: %.5f" % \
max_validation_score)
print("Test score at chosen alpha: %.5f" % \
test_score_at_chosen_alpha)
结果
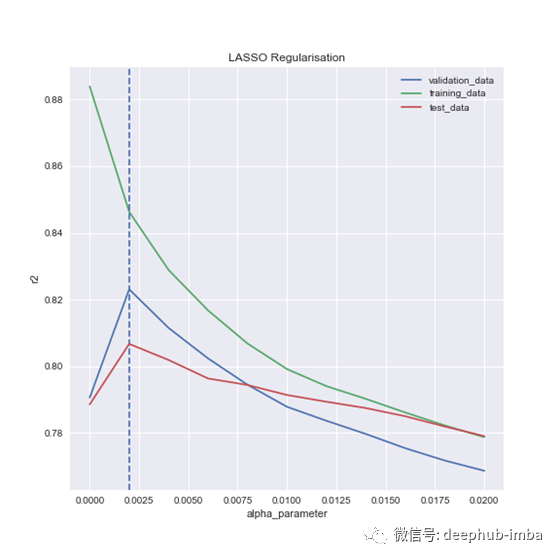
Chosen alpha: 0.00200
Validation score: 0.82310
Test score at chosen alpha: 0.80673
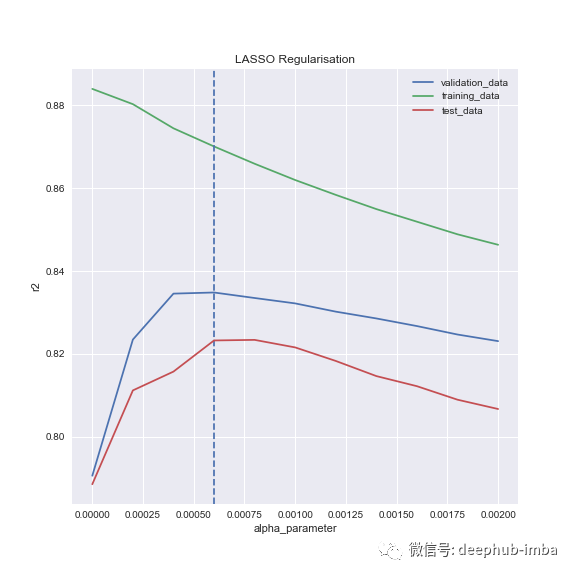
这是否意味着我们找到了最优?你可以看一下图,看到一个漂亮的尖刺,但是它是否够高了。不完全是。如果我们在更细粒度的层面上运行它:
lasso_alphas = np.linspace(0, 0.002, 11)
这是结果,请注意0.02,最右边的点是我们在上一个图表中出现峰值的地方:
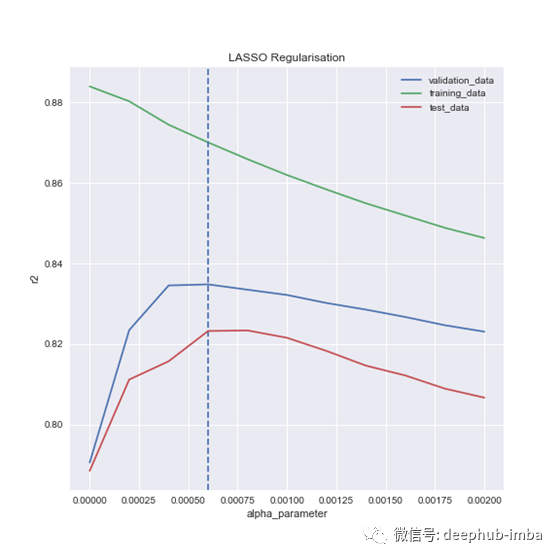
Chosen alpha: 0.00060
Validation score: 0.83483
Test score at chosen alpha: 0.82326
如果我们不进行详细的测试,我们就会选择一个能使整体检验R²降低2%的,我认为这很重要。
这篇文章的标题包括Ridge,除了理论介绍之外,我们还没有讨论过它。
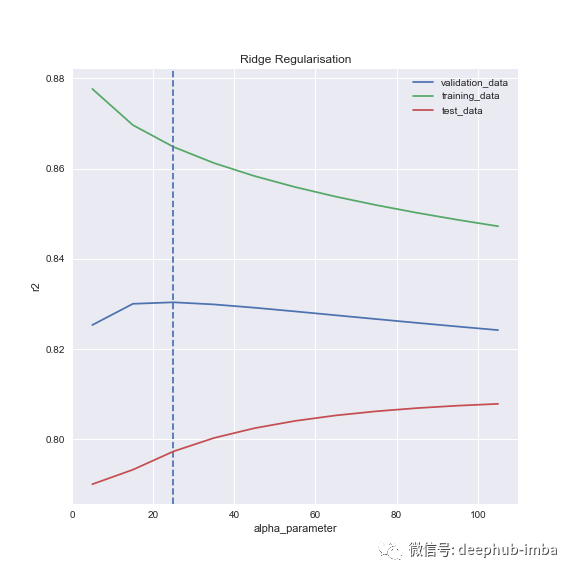
原因很简单:它的工作方式与Lasso完全一样,您可能只是想选择不同的alpha参数,并在model_name参数中传递' Ridge '。Ridge也存在同样的问题(我不包括搜索alpha范围的部分):
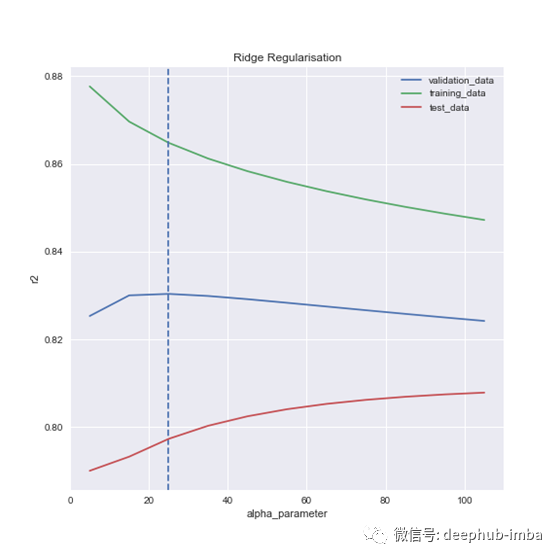
你会注意到,我们根据蓝线选择的点似乎不再是红线的最佳点。没错,但我觉得这对Lasso 模型来说是个巧合。
总结
这就是我为Lasso和Ridge做超参数调整的方法。希望对大家有所帮助,再次介绍一下要点:
- 记住缩放变量;
- alpha = 0是线性回归;
- 多步搜索最佳参数;
- 使用基于分数的平方差异来衡量表现。
作者:Mate Pocs
原文地址:https://towardsdatascience.com/hyperparameter-tuning-in-lasso-and-ridge-regressions-70a4b158ae6d
deephub翻译组