
我记得我在选修一门课程时,教授花了两节课反复研究决策树的数学原理,然后才宣布:“同学们,决策树算法不使用任何这些。”很显然,这些课程并不是关于基尼系数或熵增益的。教授在讲课时几分钟就避开了他们。这两节课是180分钟的贝叶斯定理和贝塔分布的交锋。那么,为什么我们被鼓励去研究所有这些数学呢?好吧,增长决策树的常用方法是该贝叶斯模型的近似值。但这不是。该模型还包含一个初级集成方法的思想。这样一来,让我们投入一些数学知识,并探讨贝叶斯定理的优越性。(注意:我假设您知道概率概念,例如随机变量,贝叶斯定理和条件概率)
应对挑战
我想你应该熟悉决策树以及它们是如何利用基尼系数或熵损失来工作的。所以,我们将用贝叶斯定理来代替它。考虑一个需要使用决策树来解决的二元分类问题。我们的挑战是通过在决策过程中包括所有树来对新数据实例x进行分类。您将如何进行呢?
如前所述,您必须使用贝叶斯来处理这个问题,它计算x属于特定类Y (y1或y2)的概率。利用这个概率,您可以决定合适的类。注意,从现在开始,我们将把X和Y看作随机变量(RV)。但你只需要这些RV吗?不,估计P(Y|X= X)依赖于另外两个东西。
让我们考虑一下涉及所有可能的决策树的难题。并不是所有的树都足够“绿”来解决这个问题。为什么如此?对于任何问题,通常使用基尼系数或熵增益来挖掘出最能隔离训练数据的树。这表明任何特定的数据集d都有一个唯一的拟合树。因此,如果你认为树和数据集是RVs,那么,对于一个特定的树T= T和训练数据集D= D,你可以找到概率估计,P(T= T |D= D), T如何在D上工作。理想的树将有最大值P(T= T |D= D)。此外,每个树还将对数据实例进行不同的分类。本质上,属于任何类P(Y|X= X, T= T, D= D)的新数据实例的概率在不同的树之间是不同的。现在,你是否意识到为了完成这个奇怪挑战,你需要为每棵树设置两种讨论过的概率?观察下面的方程。你怎么看?
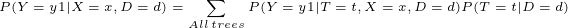
L.H.S是属于y1的x的最终概率估计。这取决于训练数据集,因为对于不同的数据集,树将进行修改。R.H.S建议在决策过程中包括所有树,我们应将x属于树t的y1的概率乘以树是理想候选者的概率,然后将所有乘积求和。换句话说,您做出的最终决定应该是所有树的分类概率的加权总和。因此,如果一棵树很好地分离了训练数据,则P(T = t | D = d)很高,它将在最终决策中有更多发言权。
等式的可能扩展
在最可靠的预测模型中,高级集成方法也可以根据上述公式运行。他们使用来自众多小树的预测的加权总和来对数据实例进行分类。请注意,与我的挑战不同,集成方法不能评估所有可能的树的预测。那会浪费计算能力。通过基尼系数或熵增益之类的过程,它们隐式地逼近P(T | D)并忽略了伪劣树。因此,基尼(Gini)和熵(Entropy)只是计算效率高的方法,可以解决贝叶斯解决方案的其他问题。
但是我们不必一定将方程式限制在树上。您可以使用不同的分类或回归模型(ML算法)来代替几棵树,并计算其概率预言的加权平均值以做出最终决定。在这里,您只需要用另一个随机变量M替换随机变量T,该随机变量M包含各种模型(算法)的数组。
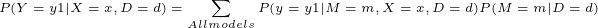
总结
本文是关于贝叶斯定理如何形成集成方法症结的一个极其简短的概述。目的是从贝叶斯的角度理解决策树,并突出显示贝叶斯统计数据在任何ML算法的背景下如何总是隐秘地工作。我故意没有讨论过如何计算所讨论方程式中的每个项。这将花费很长时间,并且还涉及其他一些数学概念,例如Beta分布等。虽然本问主要说的贝叶斯理论但是,决策树是很重要的这个是肯定的。
作者:shashank kumar
deephub翻译组