
我最近读了一篇非常有趣的论文,叫做 Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case。我认为这可能是一个有趣的项目,他的实现是从头开始的,并且可以帮助你了解更多关于时间序列预测。
预测的任务
在时间序列预测中,目标是预测给定历史值的时间序列的未来值。时间序列预测任务的一些例子是:
预测流感流行病例:时间序列预测的深度变形模型:流感流行病例
能源生产预测:能源消耗预测使用堆叠非参数贝叶斯方法
天气预报:MetNet:一个用于降水预报的神经天气模型
例如,我们可以将一个城市的能源消耗指标存储几个月,然后训练一个模型,该模型将能够预测该城市未来的能源消耗。这可以用来估计能源需求,因此能源公司可以使用这个模型来估计任何给定时间需要生产的能源的最佳值。
模型
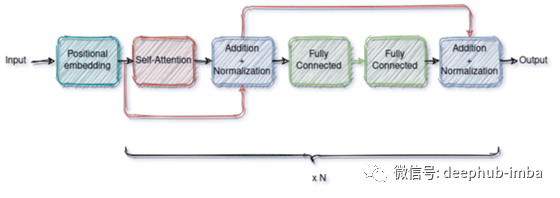
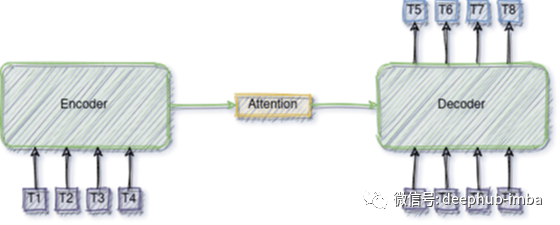
我们将使用的模型是一个编码器-解码器的Transformer,其中编码器部分将时间序列的历史作为输入,而解码器部分以自回归的方式预测未来的值。
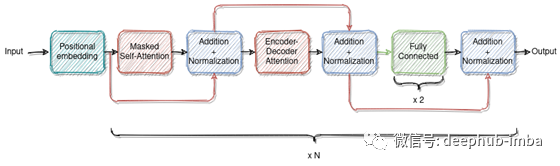
解码器使用注意力机制与编码器连接。通过这种方式,解码器可以学习在做出预测之前“关注”时间序列历史值中最有用的部分。
解码器使用了掩蔽的自注意力,这样网络就不会在训练期间获取未来的值,不会导致信息的泄露。
编码器:
解码器:
全部模型:
这个架构可以通过以下方式使用PyTorch构建:
encoder_layer = nn.TransformerEncoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
)
decoder_layer = nn.TransformerDecoderLayer(
d_model=channels,
nhead=8,
dropout=self.dropout,
dim_feedforward=4 * channels,
)
self.encoder = torch.nn.TransformerEncoder(encoder_layer, num_layers=8)
self.decoder = torch.nn.TransformerDecoder(decoder_layer, num_layers=8)
数据
每当我实现一种新方法时,我喜欢首先在合成数据上尝试它,以便更容易理解和调试。这降低了数据的复杂性,并将重点更多地放在实现/算法上。
我编写了一个小脚本,可以生成具有不同周期、偏移量和模式的时间序列。
def generate_time_series(dataframe):
clip_val = random.uniform(0.3, 1)
period = random.choice(periods)
phase = random.randint(-1000, 1000)
dataframe["views"] = dataframe.apply(
lambda x: np.clip(
np.cos(x["index"] * 2 * np.pi / period + phase), -clip_val, clip_val
)
* x["amplitude"]
+ x["offset"],
axis=1,
) + np.random.normal(
0, dataframe["amplitude"].abs().max() / 10, size=(dataframe.shape[0],)
)
return dataframe
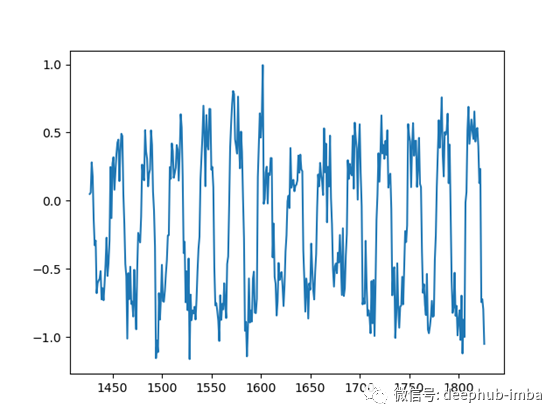
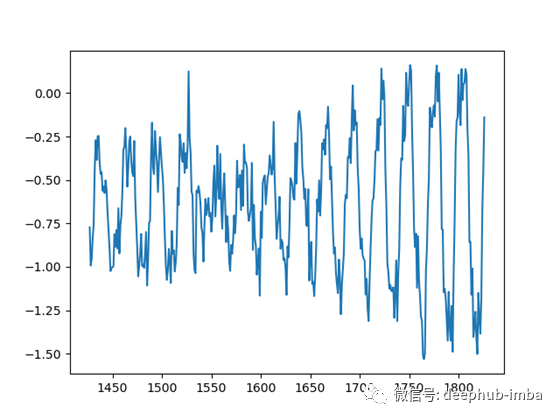
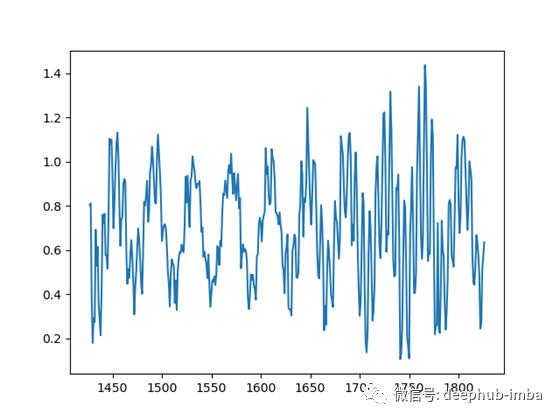
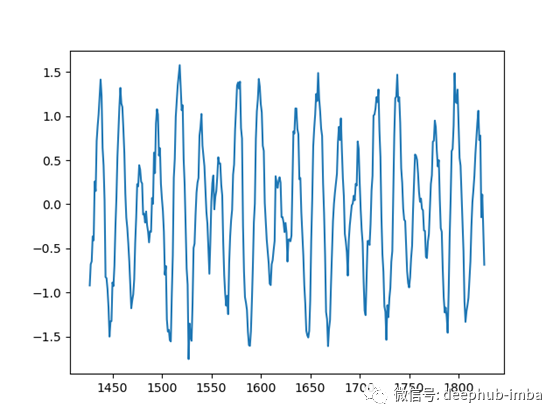
然后,该模型将一次性对所有这些时间序列进行训练:
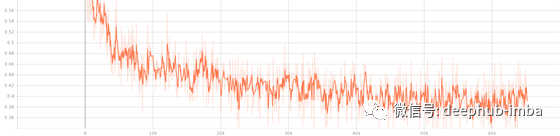
结果
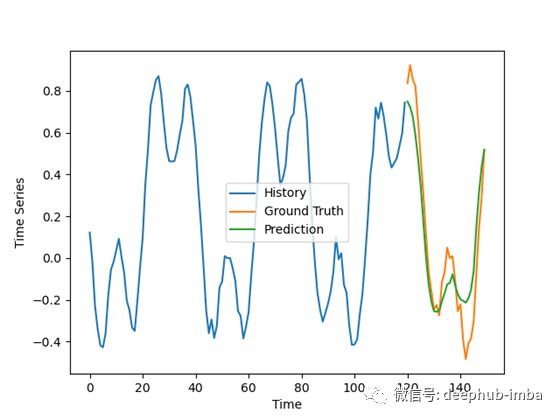
我们现在使用这个模型来预测这些时间序列的未来值。但是结果有些复杂:
预测未拟合的样例
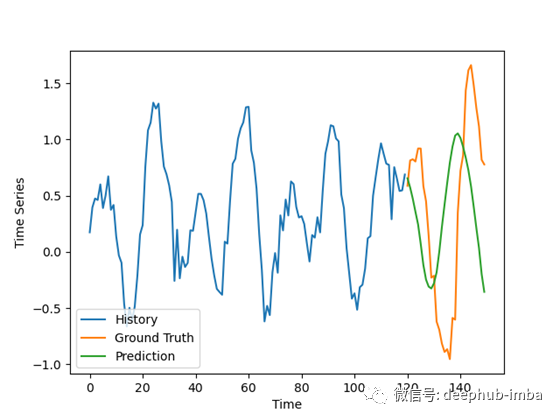
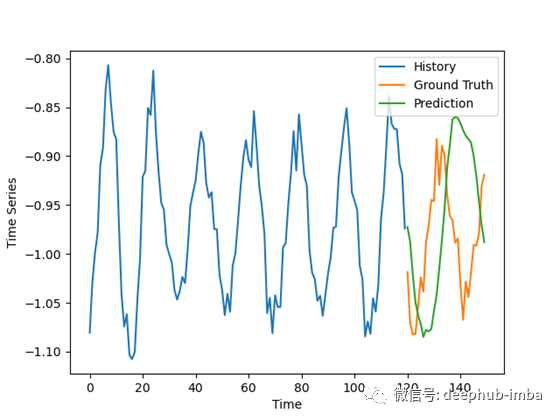
拟合样例:
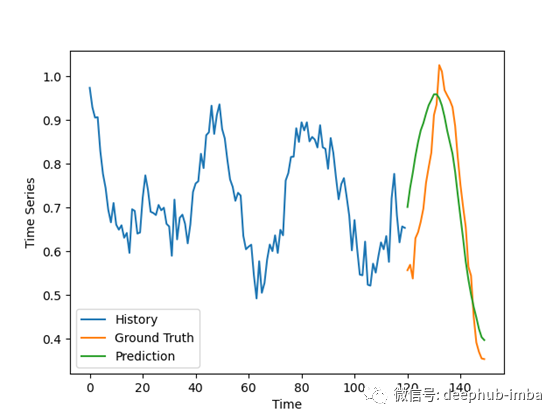
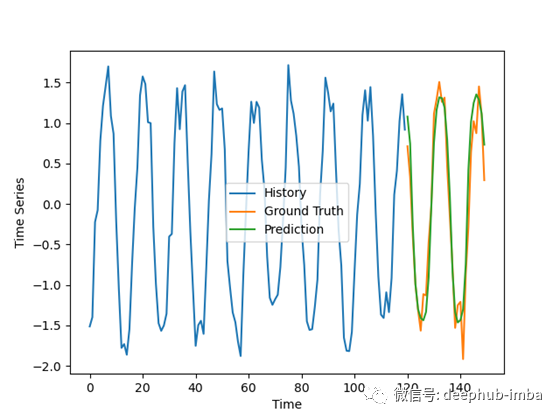
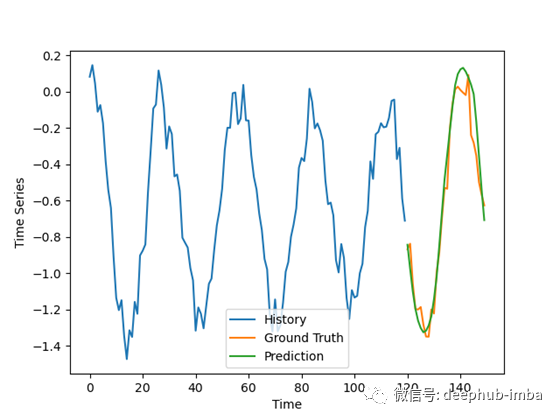
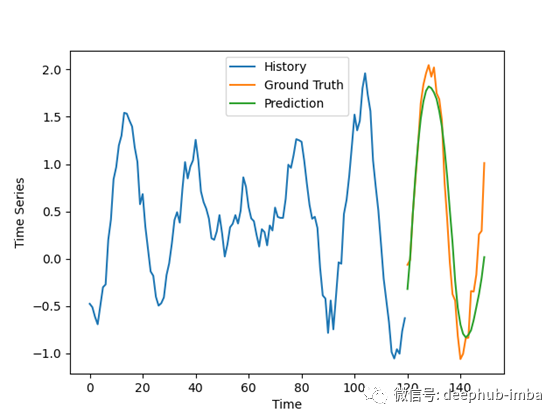
结果并不像我预期的那么好,特别是考虑到对合成数据做出好的预测通常很容易,但它们仍然令人鼓舞。
模型的预测有些不一致,对一些坏例子的振幅有轻微的过高估计。在好的例子中,预测与地面事实非常吻合,排除了噪声。
我可能需要调试我的代码多一点,并在我可以预期获得更好的结果之前优化超参数的工作。
总结
Transformers是目前在机器学习应用中非常流行的模型,所以它们将被用于时间序列预测是很自然的。但是Transformers应该不是你在处理时间序列时的第一个首选方法,但是可以做为尝试来进行测试。
本文代码:https://github.com/CVxTz/time_series_forecasting
提到的论文 arxiv:2001.08317
作者:Youness Mansar