
在开发机器学习解决方案时,需要清除的最大障碍一直是数据。像ImageNet和COCO这样的大规模、干净、完全注释的数据集并不容易获得,特别是对于小众任务。这在深度学习中尤其如此,而且随着深度学习的日益普及,这种情况会越来越明显。为了克服标记数据瓶颈,研究人员和开发人员正在开发各种技术,如迁移学习、领域适应、合成数据生成以及许多半监督和自监督技术。
半监督和自监督技术的世界是一个特别迷人的领域,因为它看起来几乎像魔术。我们如何利用世界上看似无穷无尽的无标记数据来帮助我们解决监督学习问题?事实证明,这些技术比你想象的更容易理解,你可以立即开始应用它们。
Self-Supervised学习
在我们深入研究之前,让我们先定义这些术语的含义。自监督学习本质上是从完全无标记的数据中提取监督信息来创建监督学习任务的实践。基本上,我们创建了一个“人工”监督学习任务,它具有以下特性:
它鼓励网络学习关于数据的语义上有用的信息。
它的标签可以从数据扩充中派生出来。
一个最简单,但仍然非常有效的从无标记数据学习的技术来自于一篇由Gidaris等人发表的题为“Unsupervised Representation Learning by Predicting Image Rotations”的论文。这个辅助任务非常直观:给定一个输入图像,随机旋转0、90、180或270度。然后训练您的模型来预测一个“0”、“90”、“180”或“270”的标签。
在这里工作的理论是,随机旋转的图像引入标签,同时保留有用的语义信息。例如,给一只狗一张旋转了90度的图片,人们可以清楚地看出图片已经旋转了,因为狗不会站在墙上!然而,像苍蝇、窗户和绘画这样的东西是可以立在墙上的。图像中的语义信息包含了旋转的线索。该理论是,通过试图预测图像的方向,模型必须了解物体的预期方向,从而隐式学习这些物体的语义特征,然后可能适用于其他任务。

自监督可以采取多种形式,比如图像的修复、着色和超分辨率,视频的帧预测,以及自然语言处理中的单词或序列预测。
Semi-Supervised学习
半监督学习是使用标记数据和未标记数据来训练任务的实践。半监督学习技术通常在两个任务上交替进行训练,首先是应用于有标记数据的标准监督任务,然后是利用无标记数据和某种数据扩充的辅助任务。一个这样的辅助任务可以是预测图像旋转,就像我们之前讨论的那样。在很多情况下,半监督学习本质上就像是将自监督训练和监督训练结合起来。
一个特别值得注意但又有些不同的例子是来自谷歌Research论文的FixMatch。这里的辅助任务实际上和目标任务是一样的:给定一个图像,预测它的类别。然而,我们不能用标记数据来解决这个问题。相反,未标记的输入图像被增强了两次:一次是一个微弱的增强量(例如翻转和移位),第二次是一个强大的增强。然后,该模型预测弱增强图像和强增强图像的标签。对弱增强图像的预测(如果它通过一个置信阈值)作为一个伪“ground truth”标签,我们以此评估强增强图像的标签。这里的目标是鼓励网络变得更加健壮,以极端增强,并鼓励它学习更强大的功能,而无需技术上需要标记数据。
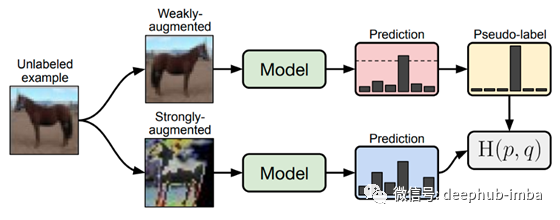
FixMatch。对输入图像(上图)进行弱增广,生成模型预测。如果预测超过了一个给定的阈值,就会分配一个“伪标签”。然后,对同一幅图像进行强增强,生成另一幅预测。FixMatch丢失函数鼓励此预测与之前的“伪标签”之间达成一致。
论文中应用了一种最新的半监督学习技术——一致性正则化。首先对你的数据进行扩充,以保留它的语义内容(例如,“这张猫的图片看起来还像猫吗”。然后,通过明确的监督或惩罚对这些变化的敏感性的损失函数的术语,鼓励你的网络对非语义的增强变得有弹性。通过利用数据增强,实际上可以通过自我监督将任何监督学习任务变成半监督任务。
SESEMI
在这篇文章的其余部分,我们将关注一种叫做SESEMI的特殊技术,一种由Flyreel AI Research发布的半监督训练技术。本文中描述的想法与图像旋转任务非常相似,除了一些关键的区别。首先,他们为水平镜像和垂直镜像添加了两个额外的类。更重要的是,这种方法联合训练被监督和自监督的目标,将自监督的目标作为一种自我监督的正规化形式。因此,损失函数看起来像一个典型的正则化损失函数,除了加权和未加权项都是应用于数据不同子集的标准交叉熵损失。
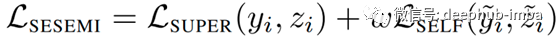
SESEMI损失函数由监督项和自监督项组成,用一个权重项w进行平衡。最左边的项(未加权)是应用于标签子集和softmax预测向量上的损失。最右边的(加权的)项是应用于带有我们的辅助标签及其softmax预测向量的数据的无标签子集的损失。这两项都是标准的交叉熵损失。
这种技术的优雅之处在于它的简单性。与其他需要大量超参数调优的先进的一致性正则化技术不同,SESEMI唯一需要的超参数是两个损失项之间的权重,无论如何,作者建议将其设置为1.0。使用这种技术不需要专门的理论、损失函数或自定义模型层。任何对深度学习技术有初步了解的人都可以成功地应用这种技术。
我提供了一个简单的谷歌Colab笔记本,您可以在其中快速尝试这种技术。在它中,我使用torchvision中方便的预训练的ResNet模型将SESEMI技术应用到CIFAR-10数据集。它唯一的主要依赖项是‘torch’和‘torchvision’。这个Colab笔记本说明了SESEMI技术对非常小的数据集所能产生的差异,而只需要很少的代码修改和几乎不需要额外的超参数调优。

完整代码:https://github.com/FlyreelAI/sesemi
colab:https://colab.research.google.com/drive/1b1sbKo3mb16e_yBgfELMVT_kBAWtYn9f?usp=sharing
作者:Mason McGough
deephub翻译组