
介绍
神经机器翻译(NMT)是一种端到端自动翻译学习方法。它的优势在于它直接学习从输入文本到相关输出文本的映射。它已被证明比传统的基于短语的机器翻译更有效,而且后者需要更多的精力来设计模型。另一方面,NMT模型的训练成本很高,尤其是在大规模翻译数据集上。由于使用了大量参数,它们在推理时的速度也明显变慢。其他限制是翻译稀有单词且无法翻译输入句子的所有部分时的鲁棒性。为了克服这些问题,已经有一些解决方案,例如使用注意力机制来复制稀有词[2]。
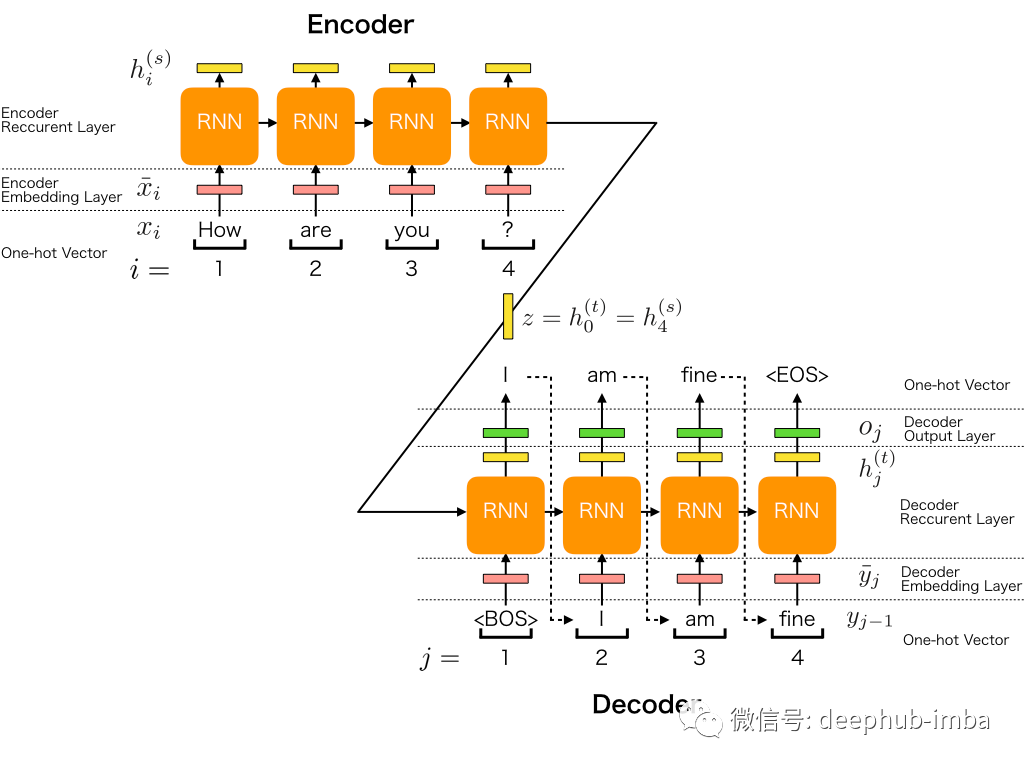
通常,NMT模型遵循通用的序列到序列学习体系结构。它由一个编码器和一个解码器的递归神经网络(RNN)组成(有关如何设置RNN的更简单的示例,请参见[3])。编码器将输入语句转换为向量列表,每个输入一个向量。给定该列表,解码器一次生成一个输出,直到产生特殊的句子结束标记为止。
我们的任务是使用中等大小的示例对语料库,为英语中的输入句子提供葡萄牙语翻译。我们使用Seq2Seq的体系结构来构建我们的NMT模型。对于编码器RNN,我们使用预训练的嵌入,即在英语Google News 200B语料库上训练过的基于令牌的文本嵌入[4]。另一方面,我们训练自己在解码器RNN中的嵌入,其词汇量设置为语料库中唯一葡萄牙语单词的数量。由于模型的架构复杂,我们实现了自定义训练循环来训练我们的模型。
本文使用的数据集包含170,305个英语和葡萄牙语[5]句子对。数据来自Tatoeba,这是一个由示例志愿者组成的大型数据库,这些示例语句由志愿者翻译成多种语言。
预处理
我们首先在葡萄牙语的每个句子中添加两个特殊标记,分别是<start>和<end>标记。它们用于向解码RNN发信号通知句子的开头和结尾。接下来,我们将葡萄牙语句子标记化,并在句子的末尾添加零。
import pandas as pd
import numpy as np
import tensorflow as tf
import tensorflow_hub as hub
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import Layer
import matplotlib.pyplot as pltNUM_EXAMPLES = 100000
data_examples = []
with open('por.txt', 'r', encoding='utf8') as f:
for line in f.readlines():
if len(data_examples) < NUM_EXAMPLES:
data_examples.append(line)
else:
break
df = pd.DataFrame(data_examples, columns=['all'])
df = df['all'].str.split('\t', expand=True)
df.columns = columns=['english', 'portuguese', 'rest']
df = df[['english', 'portuguese']]
df['portuguese'] = df.apply(lambda row: "<start> " + row['portuguese'] + " <end>", axis=1)
tokenizer = tf.keras.preprocessing.text.Tokenizer(filters='')
tokenizer.fit_on_texts(df['portuguese'].to_list())
df['portuguese_tokens'] = df.apply(lambda row:
tokenizer.texts_to_sequences([row['portuguese']])[0], axis=1)
# Print 5 examples from each language
idx = np.random.choice(df.shape[0],5)
for i in idx:
print('English')
print(df['english'][i])
print('\nportuguese')
print(df['portuguese'][i])
print(df['portuguese_tokens'][i])
print('\n----\n')
portuguese_tokens = tf.keras.preprocessing.sequence.pad_sequences(df['portuguese_tokens'].to_list(),
padding='post',
value=0)English
Have you ever taken singing lessons?
portuguese
<start> Você já fez aulas de canto? <end>
[1, 10, 60, 100, 1237, 8, 19950, 2]
----
English
Tom rode his bicycle to the beach last weekend.
portuguese
<start> O Tom foi à praia de bicicleta no último fim de semana. <end>
[1, 5, 3, 34, 61, 1243, 8, 696, 28, 869, 551, 8, 364, 2]
----
English
I have to go to sleep.
portuguese
<start> Tenho que ir dormir. <end>
[1, 45, 4, 70, 616, 2]
----
English
I have already told Tom that Mary isn't here.
portuguese
<start> Eu já disse a Tom que Maria não está aqui. <end>
[1, 7, 60, 50, 9, 3, 4, 106, 6, 13, 88, 2]
----
English
If Tom was hurt, I'd know it.
portuguese
<start> Se Tom estivesse ferido, eu o saberia. <end>
[1, 21, 3, 602, 10016, 7, 5, 16438, 2]
----
预训练嵌入层
对于编码器和解码器RNN,我们都需要定义嵌入层,以将词的索引转换为固定大小的密集向量。对于解码器RNN,我们训练了我们自己的嵌入。对于编码器RNN,我们使用了来自Tensorflow Hub的预训练英语单词嵌入。这是在英语Google新闻200B语料库上经过训练的基于令牌的文本嵌入。它使我们能够遵循转移学习的原理(在[6]中获得扩展的定义,并将转移学习应用程序应用于计算机视觉),利用在非常大的语料库上训练的单词表示形式。在将英语句子输入RNN之前,我们先对其进行了填充。
# Load embedding module from Tensorflow Hub
embedding_layer = hub.KerasLayer("https://tfhub.dev/google/tf2-preview/nnlm-en-dim128/1",
output_shape=[128], input_shape=[], dtype=tf.string)maxlen = 13def split_english(dataset):
dataset = dataset.map(lambda x, y: (tf.strings.split(x, sep=' '), y))
return dataset
def filter_func(x,y):
return (tf.math.less_equal(len(x),maxlen))
def map_maxlen(x, y):
paddings = [[maxlen - tf.shape(x)[0], 0], [0, 0]]
x = tf.pad(x, paddings, 'CONSTANT', constant_values=0)
return (x, y)
def embed_english(dataset):
dataset = dataset.map(lambda x, y: (embedding_layer(x), y))
return datasetenglish_strings = df['english'].to_numpy()
english_string_train, english_string_valid, portuguese_token_train, portuguese_token_valid = train_test_split(english_strings, portuguese_tokens, train_size=0.8)
dataset_train = (embed_english(
split_english(
tf.data.Dataset.from_tensor_slices((english_string_train, portuguese_token_train)))
.filter(filter_func))
.map(map_maxlen)
.batch(16))
dataset_valid = (embed_english(
split_english(
tf.data.Dataset.from_tensor_slices((english_string_valid, portuguese_token_valid)))
.filter(filter_func))
.map(map_maxlen)
.batch(16))
dataset_train.element_spec(TensorSpec(shape=(None, None, 128), dtype=tf.float32, name=None),
TensorSpec(shape=(None, 35), dtype=tf.int32, name=None))# shape of the English data example from the training Dataset
list(dataset_train.take(1).as_numpy_iterator())[0][0].shape(16, 13, 128)# shape of the portuguese data example Tensor from the validation Dataset
list(dataset_valid.take(1).as_numpy_iterator())[0][1].shape(16, 35)
编码器递归神经网络
编码器网络是RNN,其工作是将向量x =(x_1,…,x_T)的序列读取到向量c中,从而:
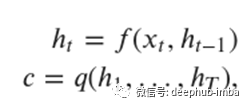
其中h_t是时间t的隐藏状态,c是根据隐藏状态序列生成的向量,f和q是非线性函数。
在定义编码器网络之前,我们引入了一层来学习英语语料库的最终令牌的128维表示(嵌入空间的大小)。因此,RNN的输入维数增加了1。RNN由一个具有1024个单位的长短期内存(LSTM)层组成。填充值在RNN中被屏蔽,因此它们将被忽略。编码器是一个多输出模型:它输出LSTM层的隐藏状态和单元状态。LSTM层的输出未在Seq2Seq体系结构中使用。
class EndTokenLayer(Layer):
def __init__(self, embedding_dim=128, **kwargs):
super(EndTokenLayer, self).__init__(**kwargs)
self.end_token_embedding = tf.Variable(initial_value=tf.random.uniform(shape=(embedding_dim,)), trainable=True)
def call(self, inputs):
end_token = tf.tile(tf.reshape(self.end_token_embedding, shape=(1, 1, self.end_token_embedding.shape[0])), [tf.shape(inputs)[0],1,1])
return tf.keras.layers.concatenate([inputs, end_token], axis=1)end_token_layer = EndTokenLayer()inputs = tf.keras.Input(shape=(maxlen, 128))
x = end_token_layer(inputs)
x = tf.keras.layers.Masking(mask_value=0)(x)
whole_seq_output, final_memory_state, final_carry_state = tf.keras.layers.LSTM(512, return_sequences=True, return_state=True)(x)
outputs = (final_memory_state, final_carry_state)encoder_model = tf.keras.Model(inputs=inputs, outputs=outputs, name="encoder_model")
encoder_model.summary()Model: "encoder_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 13, 128)] 0
_________________________________________________________________
end_token_layer (EndTokenLay (None, 14, 128) 128
_________________________________________________________________
masking (Masking) (None, 14, 128) 0
_________________________________________________________________
lstm (LSTM) [(None, 14, 512), (None, 1312768
=================================================================
Total params: 1,312,896
Trainable params: 1,312,896
Non-trainable params: 0
_________________________________________________________________inputs_eng = list(dataset_train.take(1).as_numpy_iterator())[0][0]memory_state, carry_state = encoder_model(inputs_eng)
注意力机制
我们将使用的注意力机制是由[7]提出的。使用注意力机制的主要区别在于,我们提高了模型的表达能力,尤其是编码器组件。它不再需要将源语句中的所有信息编码为固定长度的向量。上下文向量c_i然后计算为:
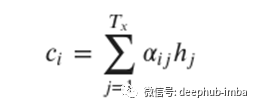
权重α_ij计算为
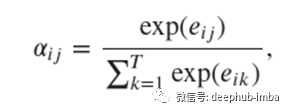
其中e_ij = a(s_i-1,h_j)是位置j周围的输入与位置i处的输出匹配程度的分数。
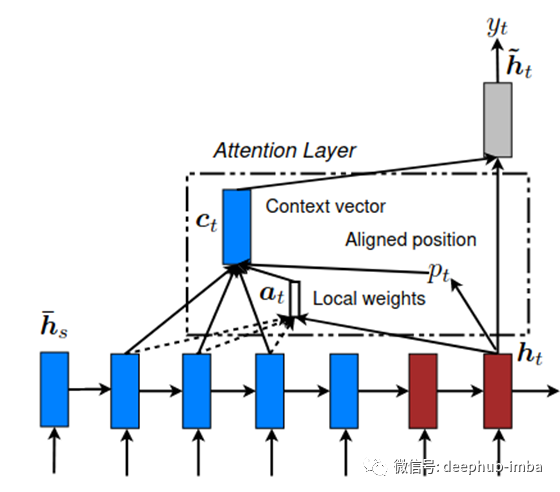
本地注意力模型-该模型首先预测当前目标单词的单个对齐位置p_t。然后将以源位置p_t为中心的窗口用于计算上下文向量c_t,该向量是窗口中源隐藏状态的加权平均值。从窗口中的当前目标状态h_t和那些源状态h_s推断权重a_t。改编自[8]。
class Attention(tf.keras.layers.Layer):
def __init__(self, units):
super(Attention, self).__init__()
self.W1 = tf.keras.layers.Dense(units)
self.W2 = tf.keras.layers.Dense(units)
self.V = tf.keras.layers.Dense(1)
def call(self, hidden_states, cell_states):
hidden_states_with_time = tf.expand_dims(hidden_states, 1)
score = self.V(tf.nn.tanh(
self.W1(hidden_states_with_time) + self.W2(cell_states)))
attention_weights = tf.nn.softmax(score, axis=1)
context_vector = attention_weights * cell_states
context_vector = tf.reduce_sum(context_vector, axis=1)
return context_vector, attention_weights
解码器递归神经网络
给定上下文向量c和所有先前预测的词y_1,…,y_t-1,对解码器进行训练以预测下一个词y_t,从而:
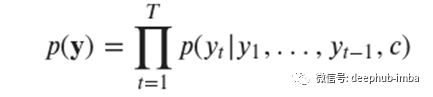
其中y =(y_1,…,y_T)。我们使用RNN,这意味着每个条件概率都被建模为
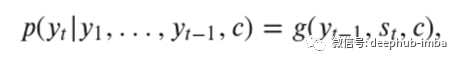
其中g是非线性函数,s_t是RNN的隐藏状态。
对于解码器RNN,我们定义了一个嵌入层,其词汇量设置为唯一的葡萄牙语令牌的数量。LSTM层紧随该嵌入层,其后为1024个单位,而Dense层的单位数等于唯一葡萄牙语标记的数量,并且没有激活功能。请注意,尽管网络相当浅,但是由于我们仅使用一个循环层,所以最终需要训练几乎24M的参数。
import json
word_index = json.loads(tokenizer.get_config()['word_index'])
max_index_value = max(word_index.values())class decoder_RNN(tf.keras.Model):
def __init__(self, **kwargs):
super(decoder_RNN, self).__init__()
self.embed = tf.keras.layers.Embedding(input_dim=max_index_value+1, output_dim=128, mask_zero=True)
self.lstm_1 = tf.keras.layers.LSTM(1024, return_sequences=True, return_state=True)
self.dense_1 = tf.keras.layers.Dense(max_index_value+1)
self.attention = Attention(1024)def call(self, inputs, training=False, hidden_state=None, cell_state=None):
context_vector, attention_weights = self.attention(hidden_state, cell_state)
x = self.embed(inputs)
x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)x, hidden_state, cell_state = self.lstm_1(x)
x = self.dense_1(x)
return xdecoder_model = decoder_RNN()decoder_model(inputs = tf.random.uniform((16, 1)), hidden_state = memory_state, cell_state = carry_state)
decoder_model.summary()Model: "decoder_rnn" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding_1 (Embedding) multiple 1789568 _________________________________________________________________ lstm_3 (LSTM) multiple 6819840 _________________________________________________________________ dense_4 (Dense) multiple 14330525 _________________________________________________________________ attention_1 (Attention) multiple 1051649 ================================================================= Total params: 23,991,582
Trainable params: 23,991,582
Non-trainable params: 0
_________________________________________________________________
训练
为了训练具Seq2Seq的模型,我们需要定义一个自定义训练循环。首先,我们定义了一个函数,该函数将葡萄牙语语料库拆分为馈入解码器模型的输入和输出张量。其次,我们创建了完整模型的前进和后退遍历。我们将英语输入传递给编码器,以获取编码器LSTM的隐藏状态和单元状态。然后将这些隐藏状态和单元状态与葡萄牙语输入一起传递到解码器中。我们定义了损失函数,该函数是在解码器输出和先前拆分的葡萄牙语输出之间计算的,以及相对于编码器和解码器可训练变量的梯度计算。最后,我们针对定义的纪元数运行训练循环。它遍历训练数据集,从葡萄牙语序列创建解码器输入和输出。然后计算梯度并相应地更新模型的参数。
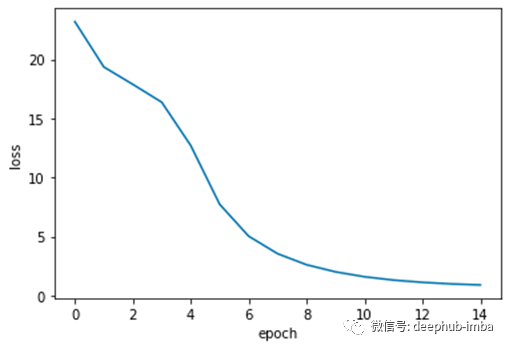
即使使用GPU,该模型的训练速度也很慢。回想一下,我们甚至没有在任何RNN中堆叠层,这会减少我们的损失,但同时使我们的模型更难训练。从下面的图中我们可以看到,训练和验证都随着时间的推移而稳步减少。
def portuguese_input_output(data):
return (tf.cast(data[:,0:-1], tf.float32), tf.cast(data[:,1:], tf.float32))optimizer_obj = tf.keras.optimizers.Adam(learning_rate=0.001)
loss_obj = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)@tf.function
def grad(encoder_model, decoder_model, english_input, portuguese_input, portuguese_output, loss):
with tf.GradientTape() as tape:
loss_value = 0
hidden_state, cell_state = encoder_model(english_input)
dec_input = tf.expand_dims([word_index['<start>']] * 16, 1)# Teacher forcing - feeding the target as the next input
for t in range(1, portuguese_output.shape[1]):
predictions = decoder_model(dec_input, hidden_state = hidden_state, cell_state = cell_state)loss_value += loss(portuguese_output[:, t], predictions)# using teacher forcing
dec_input = tf.expand_dims(portuguese_output[:, t], 1)grads = tape.gradient(loss_value, encoder_model.trainable_variables + decoder_model.trainable_variables)
return loss_value, gradsdef train_model(encoder_model, decoder_model, num_epochs, train_dataset, valid_dataset, optimizer, loss, grad_fn):
inputs = (14,)
train_loss_results = []
train_loss_results_valid = []
for epoch in range(num_epochs):
start = time.time()epoch_loss_avg = tf.keras.metrics.Mean()
for x, y in train_dataset:
dec_inp, dec_out = portuguese_input_output(y)
loss_value, grads = grad_fn(encoder_model, decoder_model, x, dec_inp, dec_out, loss)
optimizer.apply_gradients(zip(grads, encoder_model.trainable_variables + decoder_model.trainable_variables))
epoch_loss_avg(loss_value)train_loss_results.append(epoch_loss_avg.result())
print("Epoch {:03d}: Loss: {:.3f}".format(epoch,
epoch_loss_avg.result()))
print(f'Time taken for 1 epoch {time.time()-start:.2f} sec\n')
return train_loss_resultsnum_epochs=15
train_loss_results = train_model(encoder_model, decoder_model, num_epochs, dataset_train, dataset_valid, optimizer_obj, loss_obj, grad)plt.plot(np.arange(num_epochs), train_loss_results)
plt.ylabel('loss')
plt.xlabel('epoch');
结果
为了测试我们的模型,我们定义了一组英语句子。为了翻译句子,我们首先以与训练和验证集相同的方式对句子进行预处理和嵌入。接下来,我们将嵌入的句子通过编码器RNN传递,以获取隐藏状态和单元状态。从特殊的“ <start>”令牌开始,我们使用了此令牌以及编码器网络的最终隐藏状态和单元状态,以从解码器获得单步预测以及更新的隐藏状态和单元状态。之后,我们使用最新的隐藏状态和单元格状态创建了一个循环,以进行下一步预测并从解码器中更新了隐藏状态和单元格状态。当发出“ <end>”令牌或句子达到定义的最大长度时,循环终止。最后,我们将输出令牌序列解码为葡萄牙语文本。
获得的翻译相当合理。一个有趣且更复杂的示例是输入“您还在家里吗?”。一个问题具有非常清晰的语法规则,其中一些是特定于语言的。返回的翻译“ ainda esta em casa?”表明该模型能够捕获这些特性。
english_test = ['that is not safe .',
'this is my life .',
'are you still at home ?',
'it is very cold here .']english_test_emb = embed_english(split_english(tf.data.Dataset.from_tensor_slices((english_test, portuguese_token_train[:len(english_test),:])))).map(map_maxlen).batch(1)total_output=[]
for x, y in english_test_emb:
hidden_state, cell_state = encoder_model(x)
output_decoder = decoder_model(inputs = np.tile(word_index['<start>'], (1, 1)), hidden_state = hidden_state, cell_state = cell_state)
output=[]
output.append(output_decoder)
for i in range(13):
if tf.math.argmax(output_decoder, axis=2).numpy()[0][0] == 2: # <end> character
break
output_decoder = decoder_model(inputs = tf.math.argmax(output_decoder, axis=2), hidden_state = hidden_state, cell_state = cell_state)
output.append(output_decoder)
total_output.append(output)total_output_trans = []
for j in range(test_size):
output_trans = []
for i in range(len(total_output[j])):
output_trans.append(tf.math.argmax(total_output[j][i], axis=2).numpy()[0][0])
total_output_trans.append(output_trans)output_trans = np.array([np.array(xi) for xi in total_output_trans], dtype=object)portuguese_trans_batch=[]
inv_word_index = {v: k for k, v in word_index.items()}
for i in range(output_trans.shape[0]):
portuguese_trans_batch.append(' '.join(list(np.vectorize(inv_word_index.get)(output_trans[i]))))list(english_test)['that is not safe .',
'this is my life .',
'are you still at home ?',
'it is very cold here .']portuguese_trans_batch['nao e seguro .',
'e a minha vida .',
'ainda esta em casa ?',
'muito frio aqui .']
结论
NMT模型的架构在使用时极具挑战性,并且需要大量定制,例如在其训练过程中。当在非常大的语料库中使用预先训练的嵌入来嵌入英语序列时,我们使用了转移学习的原理。另一方面,我们为葡萄牙语语言开发了自己的嵌入程序,用作解码器网络的输入。编码器和解码器RNN保持尽可能简单,因为该模型的训练计算量很大。
我们生成了从英语文本到葡萄牙语的翻译,而没有提供除英语和葡萄牙语的句子对以外的其他内容来训练我们的模型。该模型理解肯定和否定,以及在建立疑问句类型时的重要语法区别,并且能够解释语法规则,例如主语-从句倒装,通常用英语使用,但不能直接翻译成葡萄牙语。
可以通过增加具有更多循环层的模型深度以及每层中的单元数来扩展此方法。可以调整超参数(例如批大小)以提高准确性。还可以测试范围更广的注意力策略。
最后如果你需要全部的代码,可以在这里找到 https://github.com/luisroque/deep-learning-articles
引用
[1] [Wu et al., 2016] Wu, Y., Schuster, M., Chen, Z., Le, Q. V., Norouzi, M., Macherey, W., Krikun,M., Cao, Y., Gao, Q., Macherey, K., Klingner, J., Shah, A., Johnson, M., Liu, X., ŁukaszKaiser, Gouws, S., Kato, Y., Kudo, T., Kazawa, H., Stevens, K., Kurian, G., Patil, N., Wang,W., Young, C., Smith, J., Riesa, J., Rudnick, A., Vinyals, O., Corrado, G., Hughes, M., and Dean, J. (2016). Google’s neural machine translation system: Bridging the gap between human and machine translation.
[2] [Jean et al., 2015] Jean, S., Cho, K., Memisevic, R., and Bengio, Y. (2015). On using very large target vocabulary for neural machine translation.
[4] https://tfhub.dev/google/tf2-preview/nnlm-en-dim128
[5]https://www.kaggle.com/luisroque/engpor-sentence-pairs
[7] [Bahdanau et al., 2016] Bahdanau, D., Cho, K., and Bengio, Y. (2016). Neural machine translation by jointly learning to align and translate.
[8] [Luong et al., 2015] Luong, M.-T., Pham, H., and Manning, C. D. (2015). Effective approaches to attention-based neural machine translation.
作者:Luís Roque
deephub翻译组