
在这篇文章中,我们将特别关注时间序列预测。
我们将使用三个时间序列模型,它们是使用python建立的超级商店数据集(零售行业数据)。我们将使用jupyter notebook 来构建我们的python代码,然后转移到Tableau。
本文旨在演示如何将模型与Tableau的分析扩展集成,并使其无缝使用。
为什么Tableau?因为我喜欢它,而且我不能强调它是多么容易探索你的数据。(译者注:我个人也认为Tableau是最强的可视化工具)
让我们从数据开始:
#importing libraries
import pandas as pd #for reading and processing data
superstore = pd.read_excel('/Users/jevpau1/Downloads/Python Notes-UT/Superstore.xls')
superstore.head(5)

我们只保留date和sales列,以便构建时间序列对象。下面的代码将销售数字按升序排序,并按月汇总数据。
#fetching required columns
data = superstore[[‘Order Date’,’Sales’]]
data = data.sort_values(by = 'Order Date')
#creating a ts object
data['Order Date'] = pd.to_datetime(data['Order Date'])
data.index = data['Order Date']
data = data.resample('M').sum()
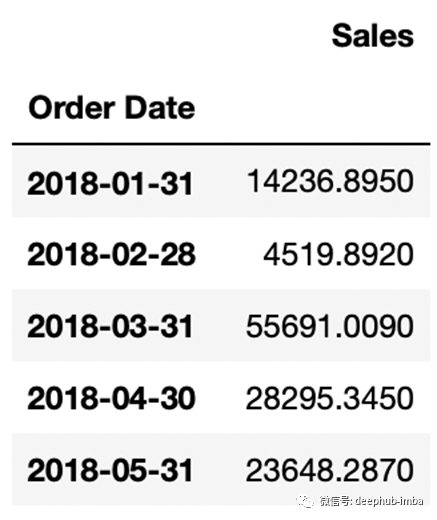
我们准备可视化时间序列:
import matplotlib.pyplot as plt
import seaborn as sns
plt.subplots(figsize = (17,7))
sns.lineplot(x = “Order Date”, y = “Sales”, data = data)
plt.show()
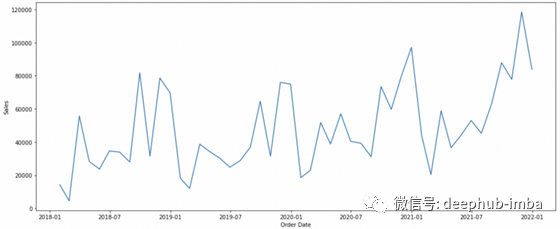
上面是我们的时间序列图。时间序列有三个重要的组成部分:趋势、季节性和误差。根据级数的性质和我们所假设的假设,我们可以将级数看作是一个“加法模型”或一个“乘法模型”。
现在,在切换到Tableau之前,我将分享我为完成模型而编写的代码。
正如本文开头提到的,我们将使用三个模型。这些是Holt线性模型,Holt-Winter模型和ARIMA。前两种方法是指数平滑法,ARIMA代表自回归综合移动平均,这是一种回归方法。
下面是Holt的Linear Method的python代码:
import pandas as pd
import numpy as np
import statsmodels.api as sm
from statsmodels.tsa.api import Holt
import dateutil
import datetime
import warnings
warnings.filterwarnings('ignore')
superstore = pd.read_excel('/Users/jevpau1/Downloads/Python Notes-UT/Superstore.xls')
#fetching required columns
data = superstore[['Order Date','Sales']]
data = data.sort_values(by = 'Order Date')
#creating a ts object
data['Order Date'] = pd.to_datetime(data['Order Date'])
data.index = data['Order Date']
data = data.resample('M').sum()
#use for training entire dataset
data = data[:-(6)]
#create future dataset
step = dateutil.relativedelta.relativedelta(months=1)
start = data.index[len(data)-1] + step
index = pd.date_range(start, periods=6, freq='M')
columns = ['Sales']
df = pd.DataFrame(index=index, columns=columns)
df = df.fillna(0)
#Fit the model
model = Holt(np.asarray(data['Sales'])).fit(smoothing_level = 0.3,smoothing_slope = 0.1)
df['Sales']=model.forecast(6)
df = df.fillna(0)
x = pd.concat([data,df])
x
该模型的训练时间为42个月,最后的6个月用于预测。模型参数可以调整为精度。模型将两者都追加,并将整个系列返回给我们。
我们怎么把它和Tableau联系起来呢?
Tableau有内置的分析扩展,允许与其他平台集成。
在本例中,我们选择TabPy。
您可以在上面描述的弹出窗口中测试Tableau中的连接。
我们还在python环境中导入TabPyClient来创建连接对象。
import tabpy_client
connection = tabpy_client.Client('http://localhost:9004/')
我们将使用这个连接对象将模型部署到我们刚刚启动的TabPy Server上。
让我们看看Holt的Linear方法的修改代码,它可以部署在TabPy上。
Holt线性方法
def holts_linear_method(_arg1,_arg2,_arg3):
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.tsa.api import Holt
import warnings
import dateutil
warnings.filterwarnings('ignore')
data = DataFrame({'Period': _arg1,'Net Sales': _arg2})
data = data.sort_values(by = 'Period')
data['Period'] = pd.to_datetime(data['Period'])
#use for training entire dataset
data.index = pd.to_datetime(data['Period'])
data = data.resample('M').mean()
data = data[:-(_arg3)]
#create future dataset
step = dateutil.relativedelta.relativedelta(months=1)
start = data.index[len(data)-1] + step
index = pd.date_range(start, periods=_arg3, freq='M')
columns = ['Net Sales']
df = pd.DataFrame(index=index, columns=columns)
df = df.fillna(0)
#Fit the model
fit1 = Holt(np.asarray(data['Net Sales'])).fit(smoothing_level = 0.3,smoothing_slope = 0.1)
df['Net Sales']=fit1.forecast(_arg3)
df = df.fillna(0)
x = pd.concat([data, df])
return x['Net Sales'].tolist()
connection.deploy('Holt Linear Method',holts_linear_method,'Returns forecast of revenue', override=True)
我们已经创建了一个返回模型输出的函数。因为我们将从Tableau读取数据,所以我们使用了从Tableau传递值的参数。您将注意到,我们使用连接对象在TabPy中部署模型。类似地,您可以为其他模型创建函数。
Holt-Winter方法
def holt_winters_method(_arg1,_arg2,_arg3):
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from statsmodels.tsa.api import ExponentialSmoothing
import warnings
import dateutil
warnings.filterwarnings('ignore')
data = DataFrame({'Period': _arg1,'Net Sales': _arg2})
data = data.sort_values(by = 'Period')
data['Period'] = pd.to_datetime(data['Period'])
#use for training entire dataset
data.index = pd.to_datetime(data['Period'])
data = data.resample('M').mean()
data = data[:-(_arg3)]
#create future dataset
step = dateutil.relativedelta.relativedelta(months=1)
start = data.index[len(data)-1] + step
index = pd.date_range(start, periods=_arg3, freq='M')
columns = ['Net Sales']
df = pd.DataFrame(index=index, columns=columns)
df = df.fillna(0)
#Fit Model
fit1 = ExponentialSmoothing(np.asarray(data['Net Sales']) ,seasonal_periods=4 ,trend='add', seasonal='add',).fit()
df['Net Sales']=fit1.forecast(_arg3)
df = df.fillna(0)
x = pd.concat([data, df])
return x['Net Sales'].tolist()
connection.deploy('Holt Winters Method',holt_winters_method,'Returns forecast of revenue', override=True)
ARIMA
def sarima_method(_arg1,_arg2,_arg3):
import pandas as pd
from pandas import DataFrame
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import dateutil
import datetime
import warnings
warnings.filterwarnings('ignore')
data = DataFrame({'Period': _arg1,'Net Sales': _arg2})
data = data.sort_values(by = 'Period')
data['Period'] = pd.to_datetime(data['Period'])
#use for training entire dataset
data.index = pd.to_datetime(data['Period'])
data = data.resample('M').mean()
data = data[:-(_arg3)]
#create future dataset
step = dateutil.relativedelta.relativedelta(months=1)
start = data.index[len(data)-1] + step
index = pd.date_range(start, periods=_arg3, freq='M')
columns = ['Net Sales']
df = pd.DataFrame(index=index, columns=columns)
df = df.fillna(0)
#Fit the model
fit1 = sm.tsa.statespace.SARIMAX(data['Net Sales'], order=(1, 1, 1),seasonal_order=(1,1,1,12)).fit()
df['Net Sales']=fit1.forecast(_arg3)
df = df.fillna(0)
x = pd.concat([data, df])
return x['Net Sales'].tolist()
connection.deploy('Seasonal ARIMA Method',sarima_method,'Returns forecast of revenue', override=True)
现在我们已经在TabPy中部署了这些模型,让我们在Tableau中使用它。我们将创建一个如下所示的计算字段:

Tableau使用SCRIPT_REAL、SCRIPT_STR、SCRIPT_BOOL和SCRIPT_INT四个函数分别返回实、字符串、布尔和整数类型。上面的代码告诉Tableau运行' Seasonal ARIMA Method ',该方法部署在TabPy上,有3个参数(日期、销售和月份到预测),并返回' response '到Tableau的计算字段。
类似地,我们为其他两个模型定义计算字段。如果我们想在Tableau中一目了然,它将是这样的:
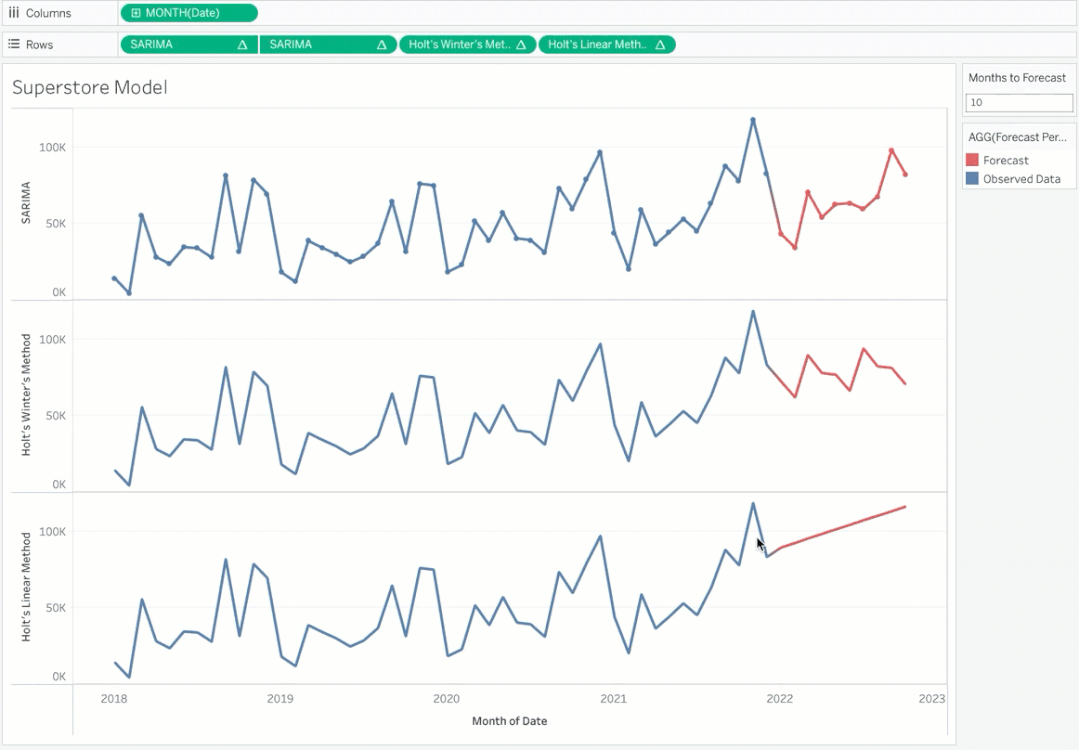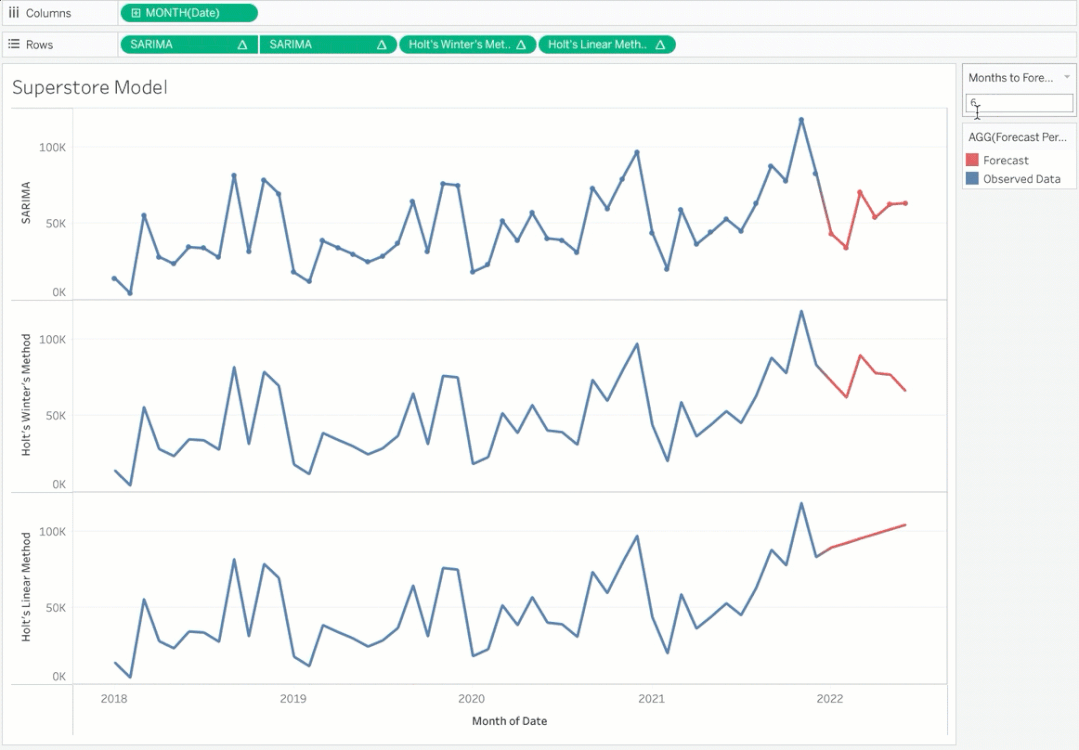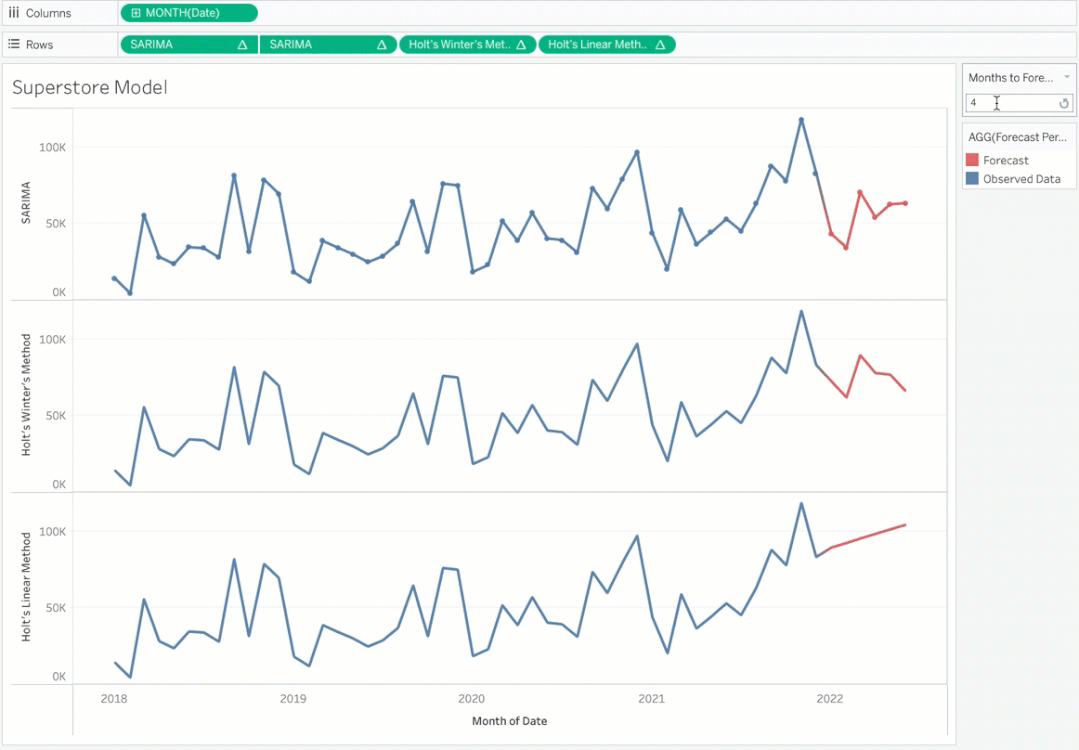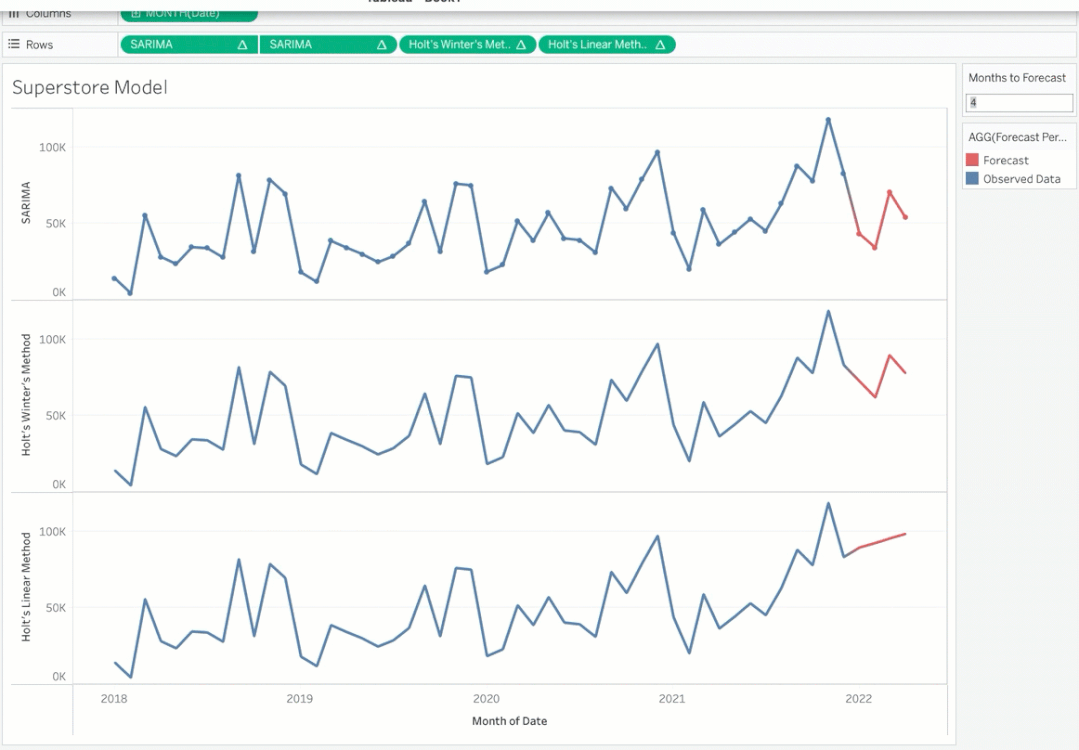
请注意,您可以根据需要动态更改预测周期并查看预测。你想要选择能给你最好精确度的模型。你可以选择在Tableau中创建一个参数来在模型之间切换。
需要注意的一个关键点是,我们需要适应Tableau中的预测周期(在我们的例子中以月为单位),以便为TabPy返回的值腾出空间。这是因为当我们从Tableau传递原始数据集时,它没有这些用于未来日期的空记录。我所做的调整数据如下所示:

在添加需要预测的月份并将其传递给TabPy之后,上面的代码实际上扩展了日期范围。此外,我们选择“显示缺失的值”为我们的日期字段。
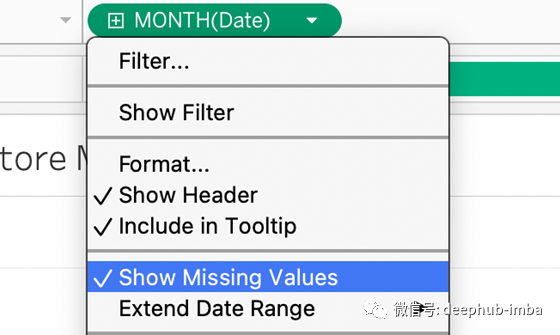
由于我们延长了日期范围,最后的日期和销售数字将被推到新的预测结束日期。然而,我们只对预测感兴趣;我们可以排除这个数据点,或者在筛选框中使用LAST()=FALSE。你可以随意提出相同的想法。
我们在Tableau的视觉发现中有一个很好的综合预测模型。你绝对可以把精度分数和模型参数带到Tableau,让它更酷!
作者:Jerry Paul
原文地址:https://jevpau1.medium.com/tableau-your-time-series-forecast-with-tabpy-5c09c151477f
deephub翻译组