
当我在使用深度学习进行图像语义分割并想使用PyTorch在DeepLabv3[1]上运行一些实验时,我找不到任何在线教程。并且torchvision不仅没有提供分割数据集,而且也没有关于DeepLabv3类内部结构的详细解释。然而,我是通过自己的研究进行了现有模型的迁移学习,我想分享这个过程,这样可能会对你们有帮助。
在本文中,我将介绍如何使用预先训练的语义分割DeepLabv3模型,通过使用迁移学习在PyTorch中进行道路裂缝检测。同样的过程也可以应用于调整自定义数据集的网络。
介绍
让我们首先简要介绍图像分割。分割任务的主要目标是输出像素级输出蒙版,其中将属于某些类别的区域分配给相同的不同像素值。如果通过为每个类别分配不同的颜色来对这些细分蒙版进行颜色编码以使其可视化,那么你就会得到一个类似于儿童涂色书中的图像。下面显示了一个示例:

分割在计算机视觉和图像处理领域已经存在很长时间了。其中一些技术是简单的阈值化,基于聚类的方法,例如k均值聚类分割,区域增长方法等。[3]
随着深度学习的最新进展以及卷积神经网络在图像相关任务中比传统方法的成功,这些技术也已应用于图像分割任务。
这些网络架构之一是Google的DeepLabv3。对模型的工作原理进行解释超出了本文的范围。相反,我们将专注于如何对数据集使用经过预训练的DeepLabv3网络。为此,我们将简要讨论转移学习。
迁移学习
当有限的数据可用时,深度学习模型往往会遇到困难。对于大多数实际应用,即使不是不可能,也很难访问大量数据集。标注既繁琐又费时。即使您打算将其外包,您仍然必须花钱。已经做出努力以能够从有限的数据训练模型。这些技术中的一种称为转移学习。
迁移学习涉及使用针对源域和任务进行预训练的网络(希望您可以在其中访问大型数据集),并将其用于您的预期/目标域和任务(与原始任务和域类似) )[4]。下图可以从概念上表示它。
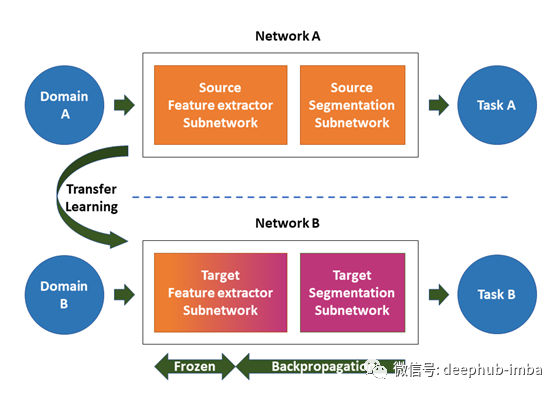
我们根据自己的要求更改目标细分子网络,然后训练部分网络或整个网络。选择的学习率低于正常训练的学习率。这是因为网络已经对源任务具有良好的权重。我们不想太快地改变权重。有时也可以冻结初始层,因为有人认为这些层提取了一般特征,可以潜在地使用而无需任何更改。
接下来,在继续PyTorch相关部分之前,我将讨论本文中使用的数据集。
使用CrackForest数据集进行裂缝检测
在本教程中,我将使用CrackForest [5] [6]数据集通过分段进行道路裂缝检测。它由具有裂缝作为缺陷的城市道路表面图像组成。图像包含混淆区域,例如阴影,溢油和水渍。这些图像是使用普通的iPhone5相机拍摄的。数据集包含118张图像,并具有对应的裂纹像素级别蒙版,所有蒙版的大小均为320×480。额外的混杂因素以及可用于训练的有限数量的样本使CrackForest成为具有挑战性的数据集[7]。

PyTorch的数据集
让我们首先为模型构造一个数据集类,该数据集类将用于获取训练样本。为了进行分割,我们将一个地面真相掩码图像作为标签,而不是一个可以热编码的单值数字标签。蒙版具有可用的像素级注释,如图3所示。因此,用于输入和标签的训练张量将是四维的。对于PyTorch,它们是:batch_size x通道x高x宽。
我们现在将定义细分数据集类。类定义如下。
"""
Author: Manpreet Singh Minhas
Contact: msminhas at uwaterloo ca
"""
from pathlib import Path
from typing import Any, Callable, Optional
import numpy as np
from PIL import Image
from torchvision.datasets.vision import VisionDataset
class SegmentationDataset(VisionDataset):
"""A PyTorch dataset for image segmentation task.
The dataset is compatible with torchvision transforms.
The transforms passed would be applied to both the Images and Masks.
"""
def __init__(self,
root: str,
image_folder: str,
mask_folder: str,
transforms: Optional[Callable] = None,
seed: int = None,
fraction: float = None,
subset: str = None,
image_color_mode: str = "rgb",
mask_color_mode: str = "grayscale") -> None:
"""
Args:
root (str): Root directory path.
image_folder (str): Name of the folder that contains the images in the root directory.
mask_folder (str): Name of the folder that contains the masks in the root directory.
transforms (Optional[Callable], optional): A function/transform that takes in
a sample and returns a transformed version.
E.g, ``transforms.ToTensor`` for images. Defaults to None.
seed (int, optional): Specify a seed for the train and test split for reproducible results. Defaults to None.
fraction (float, optional): A float value from 0 to 1 which specifies the validation split fraction. Defaults to None.
subset (str, optional): 'Train' or 'Test' to select the appropriate set. Defaults to None.
image_color_mode (str, optional): 'rgb' or 'grayscale'. Defaults to 'rgb'.
mask_color_mode (str, optional): 'rgb' or 'grayscale'. Defaults to 'grayscale'.
Raises:
OSError: If image folder doesn't exist in root.
OSError: If mask folder doesn't exist in root.
ValueError: If subset is not either 'Train' or 'Test'
ValueError: If image_color_mode and mask_color_mode are either 'rgb' or 'grayscale'
"""
super().__init__(root, transforms)
image_folder_path = Path(self.root) / image_folder
mask_folder_path = Path(self.root) / mask_folder
if not image_folder_path.exists():
raise OSError(f"{image_folder_path} does not exist.")
if not mask_folder_path.exists():
raise OSError(f"{mask_folder_path} does not exist.")
if image_color_mode not in ["rgb", "grayscale"]:
raise ValueError(
f"{image_color_mode} is an invalid choice. Please enter from rgb grayscale."
)
if mask_color_mode not in ["rgb", "grayscale"]:
raise ValueError(
f"{mask_color_mode} is an invalid choice. Please enter from rgb grayscale."
)
self.image_color_mode = image_color_mode
self.mask_color_mode = mask_color_mode
if not fraction:
self.image_names = sorted(image_folder_path.glob("*"))
self.mask_names = sorted(mask_folder_path.glob("*"))
else:
if subset not in ["Train", "Test"]:
raise (ValueError(
f"{subset} is not a valid input. Acceptable values are Train and Test."
))
self.fraction = fraction
self.image_list = np.array(sorted(image_folder_path.glob("*")))
self.mask_list = np.array(sorted(mask_folder_path.glob("*")))
if seed:
np.random.seed(seed)
indices = np.arange(len(self.image_list))
np.random.shuffle(indices)
self.image_list = self.image_list[indices]
self.mask_list = self.mask_list[indices]
if subset == "Train":
self.image_names = self.image_list[:int(
np.ceil(len(self.image_list) * (1 - self.fraction)))]
self.mask_names = self.mask_list[:int(
np.ceil(len(self.mask_list) * (1 - self.fraction)))]
else:
self.image_names = self.image_list[
int(np.ceil(len(self.image_list) * (1 - self.fraction))):]
self.mask_names = self.mask_list[
int(np.ceil(len(self.mask_list) * (1 - self.fraction))):]
def __len__(self) -> int:
return len(self.image_names)
def __getitem__(self, index: int) -> Any:
image_path = self.image_names[index]
mask_path = self.mask_names[index]
with open(image_path, "rb") as image_file, open(mask_path,
"rb") as mask_file:
image = Image.open(image_file)
if self.image_color_mode == "rgb":
image = image.convert("RGB")
elif self.image_color_mode == "grayscale":
image = image.convert("L")
mask = Image.open(mask_file)
if self.mask_color_mode == "rgb":
mask = mask.convert("RGB")
elif self.mask_color_mode == "grayscale":
mask = mask.convert("L")
sample = {"image": image, "mask": mask}
if self.transforms:
sample["image"] = self.transforms(sample["image"])
sample["mask"] = self.transforms(sample["mask"])
return sample
我们使用torchvision中的VisionDataset类作为Segmentation数据集的基类。以下三种方法需要重载。
init:此方法是数据集对象将初始化的位置。通常,您需要构建图像文件路径和相应的标签,它们是用于分割的遮罩文件路径。然后,在len和getitem方法中使用这些路径。getitem:每当您使用object [index]访问任何元素时,都会调用此方法。因此,我们需要在此处编写图像和蒙版加载逻辑。因此,实质上,您可以使用此方法中的数据集对象从数据集中获得一个训练样本。len:每当使用len(obj)时,都会调用此方法。此方法仅返回目录中训练样本的数量。
为PyTorch创建自定义数据集时,请记住使用PIL库。这使您可以直接使用Torchvision转换,而不必定义自己的转换。
在此类的第一个版本中,我使用OpenCV来加载图像!该库不仅非常繁重,而且与Torchvision转换不兼容。我必须编写自己的自定义转换并自己处理尺寸更改。
我添加了其他功能,使您可以将数据集保留在一个目录中,而不是将Train和Val拆分到单独的文件夹中,因为我使用的许多数据集都不采用这种格式,并且我不想重组我的数据集 文件夹结构每次。
现在我们已经定义了数据集类,下一步是从此创建一个PyTorch数据加载器。数据加载器使您可以使用多线程处理来创建一批数据样本和标签。这使得数据加载过程更加快捷和高效。为此,可以使用torch.utils.data下可用的DataLoader类。创建过程本身很简单。通过将数据集对象传递给它来创建一个DataLoader对象。支持的参数如下所示。
DataLoader(dataset, batch_size=1, shuffle=False, sampler=None,
batch_sampler=None, num_workers=0, collate_fn=None,
pin_memory=False, drop_last=False, timeout=0,
worker_init_fn=None, *, prefetch_factor=2,
persistent_workers=False)
下面解释了几个有用的参数:
数据集(Dataset):要从中加载数据的数据集。
batch_size(整数,可选):每个批次要加载多少样本(默认值:1)
shuffle(布尔型,可选):设置为True可使数据在每个时期都重新随机播放。(默认值:False)
num_workers(int,可选):要用于数据加载的子进程数。0表示将在主进程中加载数据。(默认值:0)提示:您可以将此值设置为等于系统处理器中的内核数,以作为最佳值。设置较高的值可能会导致性能下降。
此外,我编写了两个帮助程序函数,这些函数可以根据您的数据目录结构为您提供数据加载器,并且可以在datahandler.py文件中使用它们。
get_dataloader_sep_folder:从两个单独的Train和Test文件夹中创建Train和Test数据加载器。目录结构应如下所示。
data_dir
--Train
------Image
---------Image1
---------ImageN
------Mask
---------Mask1
---------MaskN
--Train
------Image
---------Image1
---------ImageN
------Mask
---------Mask1
---------MaskN
get_dataloader_single_folder:从单个文件夹创建。结构应如下
--data_dir
------Image
---------Image1
---------ImageN
------Mask
---------Mask1
---------MaskN
接下来,我们讨论本教程的关键所在,即如何根据我们的数据需求加载预训练的模型并更改分割头。
DeepLabv3模型
Torchvision有可用的预训练模型,我们将使用其中一种模型。我编写了以下函数,该函数为您提供了具有自定义数量的输出通道的模型。如果您有多个班级,则可以更改此值。
""" DeepLabv3 Model download and change the head for your prediction"""
from torchvision.models.segmentation.deeplabv3 import DeepLabHead
from torchvision import models
def createDeepLabv3(outputchannels=1):
"""DeepLabv3 class with custom head
Args:
outputchannels (int, optional): The number of output channels
in your dataset masks. Defaults to 1.
Returns:
model: Returns the DeepLabv3 model with the ResNet101 backbone.
"""
model = models.segmentation.deeplabv3_resnet101(pretrained=True,
progress=True)
model.classifier = DeepLabHead(2048, outputchannels)
# Set the model in training mode
model.train()
return model
首先,我们使用models.segmentation.deeplabv3_resnet101方法获得预训练模型,该方法将预训练模型下载到我们的系统缓存中。注意resnet101是从此特定方法获得的deeplabv3模型的基础模型。这决定了传递到分类器的特征向量的长度。
第二步是修改分割头即分类器的主要步骤。该分类器是网络的一部分,负责创建最终的细分输出。通过用具有新数量的输出通道的新DeepLabHead替换模型的分类器模块来完成更改。resnet101主干的特征向量大小为2048。如果您决定使用另一个主干,请相应地更改此值。
最后,我们将模型设置为训练模式。此步骤是可选的,因为您也可以在训练逻辑中执行此操作。
下一步是训练模型。
我定义了以下训练模型的train_model函数。它将训练和验证损失以及指标(如果指定)值保存到CSV日志文件中,以便于访问。训练代码代码如下。后面有充分的文档来解释发生了什么。
def train_model(model, criterion, dataloaders, optimizer, metrics, bpath,
num_epochs):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_loss = 1e10
# Use gpu if available
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
# Initialize the log file for training and testing loss and metrics
fieldnames = ['epoch', 'Train_loss', 'Test_loss'] + \
[f'Train_{m}' for m in metrics.keys()] + \
[f'Test_{m}' for m in metrics.keys()]
with open(os.path.join(bpath, 'log.csv'), 'w', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for epoch in range(1, num_epochs + 1):
print('Epoch {}/{}'.format(epoch, num_epochs))
print('-' * 10)
# Each epoch has a training and validation phase
# Initialize batch summary
batchsummary = {a: [0] for a in fieldnames}
for phase in ['Train', 'Test']:
if phase == 'Train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
# Iterate over data.
for sample in tqdm(iter(dataloaders[phase])):
inputs = sample['image'].to(device)
masks = sample['mask'].to(device)
# zero the parameter gradients
optimizer.zero_grad()
# track history if only in train
with torch.set_grad_enabled(phase == 'Train'):
outputs = model(inputs)
loss = criterion(outputs['out'], masks)
y_pred = outputs['out'].data.cpu().numpy().ravel()
y_true = masks.data.cpu().numpy().ravel()
for name, metric in metrics.items():
if name == 'f1_score':
# Use a classification threshold of 0.1
batchsummary[f'{phase}_{name}'].append(
metric(y_true > 0, y_pred > 0.1))
else:
batchsummary[f'{phase}_{name}'].append(
metric(y_true.astype('uint8'), y_pred))
# backward + optimize only if in training phase
if phase == 'Train':
loss.backward()
optimizer.step()
batchsummary['epoch'] = epoch
epoch_loss = loss
batchsummary[f'{phase}_loss'] = epoch_loss.item()
print('{} Loss: {:.4f}'.format(phase, loss))
for field in fieldnames[3:]:
batchsummary[field] = np.mean(batchsummary[field])
print(batchsummary)
with open(os.path.join(bpath, 'log.csv'), 'a', newline='') as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writerow(batchsummary)
# deep copy the model
if phase == 'Test' and loss < best_loss:
best_loss = loss
best_model_wts = copy.deepcopy(model.state_dict())
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
print('Lowest Loss: {:4f}'.format(best_loss))
# load best model weights
model.load_state_dict(best_model_wts)
return model
确保将模型以及输入和标签发送到同一设备(可以是cpu或cuda)。
在进行正向和反向传播以及参数更新之前,请记住使用optimizer.zero_grad()清除梯度。
训练时,使用mode.train()将模型设置为训练模式
进行推断时,请使用mode.eval()将模型设置为评估模式。这一点非常重要,因为这可以确保调整网络参数,以解决影响网络权重的批处理规范,丢失等技术。
最佳模型取决于最低的损失值。您也可以根据评估指标选择最佳模型。但是您必须稍微修改一下代码。
我已使用均方误差(MSE)损失函数完成此任务。我使用MSE的原因是它是一个简单的函数,可以提供更好的结果,并且可以为计算梯度提供更好的表面。在我们的案例中,损失是在像素级别上计算的,定义如下:
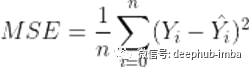
为了评估模型的定量性能,选择了两个评估指标。第一个指标是受试者工作特征曲线(ROC)和曲线下面积(AUC)测量[8]。AUC或ROC是任何二元分类器(在这种情况下为二元分割掩码)的程度或可分离性的可靠度量。它提供了所有可能的分类阈值下模型性能的汇总度量。优秀的模型具有接近于AUROC的值,这意味着分类器实际上与特定阈值的选择无关。用于评估的第二个指标是F1分数。它定义为精度(P)和召回率(R)的谐波平均值,由以下方程式给出。
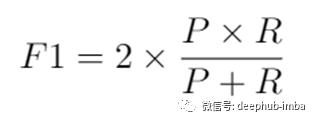
F1分数在1时达到最高值,在0时达到最差值。对于分类任务,这是一个可靠的选择,因为它同时考虑了误报。
结果
最佳模型的测试AUROC值为0.842。这是一个很高的分数,也反映在阈值操作之后获得的分段输出中。

下图显示了训练期间的损失和评估指标。
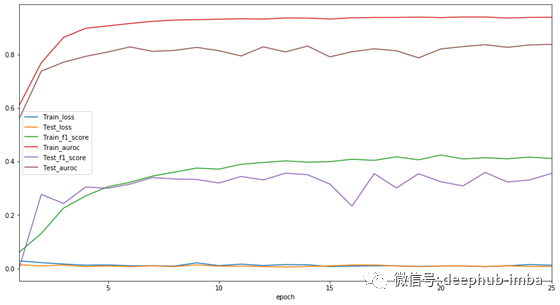
我们可以观察到,在整个训练过程中,损失值逐渐减小。AUROC和F1评分随着训练的进行而提高。然而,我们看到无论是训练还是验证,F1的得分值都始终较低。事实上,这些都是糟糕的表现。产生这样结果的原因是我在计算这个度量时使用了0.1的阈值。这不是基于数据集选择的。F1分数值可以根据阈值的不同而变化。然而,AUROC是一个考虑了所有可能的阈值的健壮度量。因此,当您有一个二元分类任务时,使用AUROC度量是明智的。尽管模型在数据集上表现良好,从分割输出图像中可以看出,与地面真实值相比,掩模被过度放大了。也许因为模型比需要的更深,我们正在观察这种行为。如果你对此现象有任何评论,请发表评论,我想知道你的想法。
总结
我们学习了如何使用PyTorch中的DeepLabv3对我们的自定义数据集进行语义分割任务的迁移学习。
首先,我们了解了图像分割和迁移学习。
接下来,我们了解了如何创建用于分割的数据集类来训练模型。
接下来是如何根据我们的数据集改变DeepLabv3模型的分割头的最重要的一步。
在CrackForest数据集上对该方法进行了道路裂缝检测测试。在仅仅经历了25个时代之后,它的AUROC评分就达到了0.842。
代码可以在https://github.com/msminhas93/DeepLabv3FineTuning上找到。
感谢你阅读这篇文章。希望你能从这篇文章中学到一些新的东西。
引用
[1] Rethinking Atrous Convolution for Semantic Image Segmentation, arXiv:1706.05587, Available: https://arxiv.org/abs/1706.05587
[2] Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation, arXiv:1802.02611, Available: https://arxiv.org/abs/1802.02611
[3] https://scikit-image.org/docs/dev/user_guide/tutorial_segmentation.html
[4] Anomaly Detection in Images, arXiv:1905.13147, Available: https://arxiv.org/abs/1905.13147
[5] Yong Shi, Limeng Cui, Zhiquan Qi, Fan Meng, and Zhensong Chen. Automatic road crack detection using randomstructured forests.IEEE Transactions on Intelligent Transportation Systems, 17(12):3434–3445, 2016.
[6] https://github.com/cuilimeng/CrackForest-dataset
[7] AnoNet: Weakly Supervised Anomaly Detection in Textured Surfaces, arXiv:1911.10608, Available: https://arxiv.org/abs/1911.10608
[8] Charles X. Ling, Jin Huang, and Harry Zhang. Auc: A statistically consistent and more discriminating measurethan accuracy. InProceedings of the 18th International Joint Conference on Artificial Intelligence, IJCAI’03,pages 519–524, San Francisco, CA, USA, 2003. Morgan Kaufmann Publishers Inc.
作者:Manpreet Singh Minhas
deephub翻译组