
为什么要使用贝叶斯A / B测试代替传统方法
A / B测试是当今技术,市场营销和研究中最有用的统计技术之一。它的价值在于A / B测试可让您确定因果关系,而大多数分析仅揭示相关性(即古老的格言“相关性而非因果关系”)。尽管A / B测试功能强大且流行程度很高,但绝大多数A/B测试都遵循一种基于频率主义统计学派的t测试的单一方法。本文将介绍A/B测试的另一种方法。这种替代方法使用了贝叶斯统计学派,本文将演示这种方法如何比传统的、频繁的方法返回更直观的结果。
传统的、频繁主义的方法使用假设作为A/B测试的框架。零假设通常是现状,例如A的平均值等于B的平均值,和备择假设测试是否有差异,如均值大意味着的信心置信度,例如5%,选择和实验可以得出两个结论
- 我们拒绝原假设并接受具有95%置信度的替代假设,例如A的平均值大于B的平均值,或者
- 我们不会以95%的置信度拒绝零假设,即我们无法对A和B的均数差异做出任何结论。
这种语言不是我们在业务中倾向于使用的语言,对于不太熟悉A / B测试的人来说可能很难理解。特别是第二个结论并没有提供太多的见解;花时间和金钱进行测试后,您只能得出结论:那就是不可能得出任何结论。
贝叶斯方法侧重于概率。如果检验上述相同的例子,零假设是A的均值等于B的均值,贝叶斯方法计算的是估计的均值差以及一个比另一个大的概率——而不仅仅是均值差是否为0。在我看来,贝叶斯方法优于频率主义方法,因为它能以特定的概率有效地接受和拒绝零假设。这种方法可以提出更有用的建议。两个示例结论(类似于上面频率主义结论)是:
- 均值A大于均值B的概率是99%这个例子拒绝了原假设
- 也就是说A有65%的概率大于B这个例子没有拒绝原假设
这种语言提供了一种结论有多可能的感觉,以便决策者有权选择他们自己的风险容忍度,它避免了零假设不能被拒绝和没有得出结论的情况。
更为有用的是它计算出均值之间的估计差。总之,这意味着来自贝叶斯测试的可能结论是“平均值A估计比平均值B大0.8个单位,并且平均值A大于平均值B的可能性为83%”。另外,贝叶斯方法还可以比较A和B的方差,并可以管理异常离群值。
贝叶斯方法的缺点是,支撑它的数学可能更具挑战性。很好的理解贝叶斯统计和马尔可夫链蒙特卡罗抽样是有帮助的,但不是完全关键。
以下各节详细介绍了如何使用贝叶斯方法进行A / B测试和R中的代码示例的示例。
A/B测试数据概述
为了演示贝叶斯方法,我将使用我在2020年初进行的一系列调查中的数据。调查包括13个问题,涉及受访者对抗击冠状病毒措施的意见(4个问题)、受访者对政府应对冠状病毒的认可(3个问题)和一般家庭活动问题(5个问题)3个主题。完整的问题列表包含在这里。在这个例子中,我们将关注有数字答案的问题,比如“你每天花多少小时和你的家人或室友在一起?”
调查被设计成包括6个相似但截然不同的调查版本。进行这些略有不同的调查的目的是为了A/B测试它们之间的差异是否会导致统计上不同的结果。每个调查之间的区别要么是问题的顺序,要么是问题的措辞方式是积极的或消极的。一个肯定词和否定词的例子是:
- 正面:你认为政府建议的社交距离在今天之后还能持续多久?
- 否定:你认为政府规定的社交距离在今天之后还会持续多久?
下表显示了不同调查版本的摘要。总共记录了291份调查答复,每个调查版本有45-47份答复。这意味着调查1的结果可以与调查3和调查5进行比较,因为顺序不同,而与调查2的措辞不同。

贝叶斯分析
下面的分析主要基于Kruschke 2012年的研究论文《贝叶斯估计取代t检验》和R包“BEST”。代码可以在我的Github上找到。
与任何贝叶斯估计一样,这种贝叶斯技术利用一组先验,这些先验通过数据中的证据更新来返回一组后验分布。下面的分析使用了t分布和根据Kruschke - 2012的马尔可夫链蒙特卡罗算法,以及对后验分布影响有限的不承诺先验。不承诺先验对后验分布的影响很小,这对本研究很有用,因为没有基线或先验信念,本研究可以轻松比较。这种方法对于管理异常值也很有效,并且只需要针对一个错误的数据点进行调整。
如果前一段有点复杂,不要担心。您仍然可以执行下面的步骤,得到一个易于解释的输出。要了解更多信息,请阅读Kruschke的论文。
步骤1:载入包和读取数据
第一步是安装所需的软件包。我们将使用使用JAGS包的BEST包。在运行BEST之前,请先下载JAGS。下一步安装BEST。完成所有步骤后,加载软件包。
还加载数据并进行分析。我们使用的是Survey_data_v2.csv,在代码中也有包含
#Load the library used for Bayesian style t Test
library(rjags)
source("BEST.R")
library(plotly)
#Load Data
DataFile="survey_data_v2.csv"
df=read.csv(DataFile, header=T)
#Numerical questions for analysis
NQ1="How.many.hours.a.day.do.you.typically.spend.on.your.job."
NQ2="How.many.hours.a.day.do.you.typically.spend.preparing.meals."
NQ3="How.many.hours.a.week.do.you.spend.on.housework..outside.of.cooking.meals."
NQ4="How.many.hours.a.day.do.you.spend.on.electronics.for.leisure."
NQ5="How.many.hours.a.day.are.you.spending.with.your.family.members.or.roommates."
NQ6="How.many.months.will.it.take.for.the.economy.to.recover."
#Manage for outliers in Question 6 (based on survey instructions)
mask=df[NQ6] >60
df[mask,NQ6] =60
步骤2:创建用于贝叶斯分析的函数
接下来,我们要创建一个函数,该函数将允许我们选择要比较的调查版本和要比较的调查问题。该函数运行马尔可夫链蒙特卡洛采样方法,该方法构造了我们测试的后验分布,即一个均值大于另一个均值的概率以及均值的估计差。
#Create function to run Bayesian Analysis
Bayes_ABTest=function(Survey_Number_A, Survey_Number_B, question){
#Filtering between survey responses
mask_A=df['Survey'] ==Survey_Number_A
mask_B=df['Survey'] ==Survey_Number_B
#Create data vectors
A=df[mask_A,question]
B=df[mask_B,question]
# Run the Bayesian analysis:
mcmcChain=BESTmcmc( A , B )
# Plot the results of the Bayesian analysis:
postInfo=BESTplot( A , B , mcmcChain , pairsPlot=TRUE )
# Show detailed summary info on console:
show( postInfo )
}
步骤3:运行test
最后,选择两组数据进行比较。在本例中,我们将使用调查版本1和2,并比较问题2。改变函数变量以测试不同的调查和问题。
#Run Analysis
Survey_A=1
Survey_B=2
Question=NQ2
Bayes_ABTest(Survey_A, Survey_B, Question)
第四步:解释输出
运行上述代码后,弹出窗口将显示如下输出。主要是100,000个可信的参数值组合的直方图,可以代表后验分布。
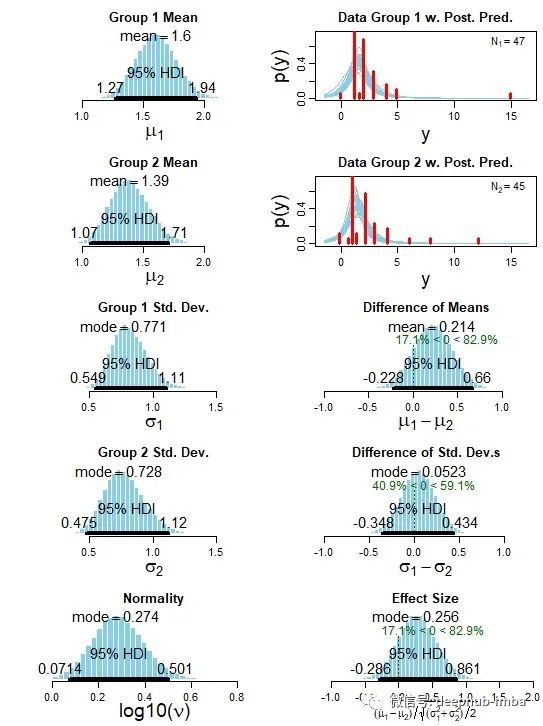
A/B测试最重要的输出是显示均值差异的右中分布。在我们的例子中,它表明平均值A比平均值B大0.214个单位,平均值A比平均值B大的概率为82.9%。这个结果是A/B检验的主要结论。注意,传统的t检验只会返回在95%置信水平下不能拒绝零假设的结果。
另一个输出显示了解释数据的其他有用信息。右上方两个以y为轴的图显示了测试数据的实际分布情况。其他数字显示后验分布。左边的5个直方图显示了与前面的5个直方图相对应的单个后验。右下角的图表显示了A组和B组之间的比较。
总结要点
与传统的频繁访问方法相比,贝叶斯A / B测试方法具有三个主要优点:
- 一组更直观的结果,例如 平均值A大于平均值B的机会为82.9%。
- 包括A和B之间差异的大小,例如 平均值A估计比平均值B大0.214个单位。
- 不受不拒绝原假设的结果的约束。
这些好处结合在一起,提供了更有用,更直观的建议,使决策者可以更好地了解测试结果并选择自己的风险等级。
引用
[1] Kruschke, John K. “Bayesian Estimation Supersedes the t Test.” Journal of Experimental Psychology . Vol. 142, no. 3, 2012, pg. 573–603, accessed 03 January 2021, https://cran.r-project.org/web/packages/BEST/vignettes/BEST.pdf
[2] Gallo, Amy 2017. A Refresher on A/B Testing , Harvard Business Review, accessed 03 January 2021, https://hbr.org/2017/06/a-refresher-on-ab-testing
[3] Hussain, Noor Zainab and Sangameswaran, S. 2018, Global advertising expenditure to grow 4.5 percent in 2018: Zenith , Reuters, accessed 03 January 2021, https://www.reuters.com/article/us-advertising-forecast/global-advertising-expenditure-to-grow-4–5-percent-in-2018-zenith-idUSKCN1M30XT
[4] Lavorini, Vincenzo, Bayesian A/B Testing with Python: the easy guide, Towards Data Science, accessed 03 January 2021,https://towardsdatascience.com/bayesian-a-b-testing-with-python-the-easy-guide-d638f89e0b8a
[5] Mazareanu, E. 2019, Market research in U.S. — Statistics & Facts , Statista, accessed 03 January 2021, https://www.statista.com/topics/4974/market-research-in-us/.
[6] NSS 2016. Bayesian Statistics explained to Beginners in Simple English , Analytics Vidhya, accessed 03 January 2021, https://www.analyticsvidhya.com/blog/2016/06/bayesian-statistics-beginners-simple-english/
作者:Robbie Geoghegan
本文代码地址:https://github.com/RobbieGeoghegan/bayesian_abtesting
deephub翻译组