
随着深度学习的多项进步,复杂的网络(例如大型transformer 网络,更广更深的Resnet等)已经发展起来,从而需要了更大的内存空间。经常,在训练这些网络时,深度学习从业人员需要使用多个GPU来有效地训练它们。在本文中,我将向您介绍如何使用PyTorch在GPU集群上设置分布式神经网络训练。
通常,分布式训练会在有一下两种情况。
- 在GPU之间拆分模型:如果模型太大而无法容纳在单个GPU的内存中,则需要在不同GPU之间拆分模型的各个部分。
- 跨GPU进行批量拆分数据。当mini-batch太大而无法容纳在单个GPU的内存中时,您需要将mini-batch拆分到不同的GPU上。
跨GPU的模型拆分
跨GPU拆分模型非常简单,不需要太多代码更改。在设置网络本身时,可以将模型的某些部分移至特定的GPU。之后,在通过网络转发数据时,数据也需要移动到相应的GPU。下面是执行相同操作的PyTorch代码段。
from torch import nn
class Network(nn.Module):
def __init__(self, split_gpus=False):
super().__init__()
self.module1 = ...
self.module2 = ...
self.split_gpus = split_gpus
if split_gpus: #considering only two gpus
self.module1.cuda(0)
self.module2.cuda(1)
def forward(self, x):
if self.split_gpus:
x = x.cuda(0)
x = self.module1(x)
if self.split_gpus:
x = x.cuda(1)
x = self.module2(x)
return x
跨GPU的数据拆分
有3种在GPU之间拆分批处理的方法。
- 积累梯度
- 使用nn.DataParallel
- 使用nn.DistributedDataParallel
积累梯度
在GPU之间拆分批次的最简单方法是累积梯度。假设我们要训练的批处理大小为256,但是一个GPU内存只能容纳32个批处理大小。我们可以执行8(= 256/32)个梯度下降迭代而无需执行优化步骤,并继续通过loss.backward()步骤添加计算出的梯度。一旦我们累积了256个数据点的梯度,就执行优化步骤,即调用optimizer.step()。以下是用于实现累积渐变的PyTorch代码段。
TARGET_BATCH_SIZE, BATCH_FIT_IN_MEMORY = 256, 32
accumulation_steps = int(TARGET_BATCH_SIZE / BATCH_FIT_IN_MEMORY)
network.zero_grad() # Reset gradients tensors
for i, (imgs, labels) in enumerate(dataloader):
preds = network(imgs) # Forward pass
loss = loss_function(preds, labels) # Compute loss function
loss = loss / accumulation_steps # Normalize our loss (if averaged)
loss.backward() # Backward pass
if (i+1) % accumulation_steps == 0: # Wait for several backward steps
optim.step() # Perform an optimizer step
network.zero_grad() # Reset gradients tensors
优点:不需要多个GPU即可进行大批量训练。即使使用单个GPU,此方法也可以进行大批量训练。
缺点:比在多个GPU上并行训练要花费更多的时间。
使用nn.DataParallel
如果您可以访问多个GPU,则将不同的批处理拆分分配给不同的GPU,在不同的GPU上进行梯度计算,然后累积梯度以执行梯度下降是很有意义的。
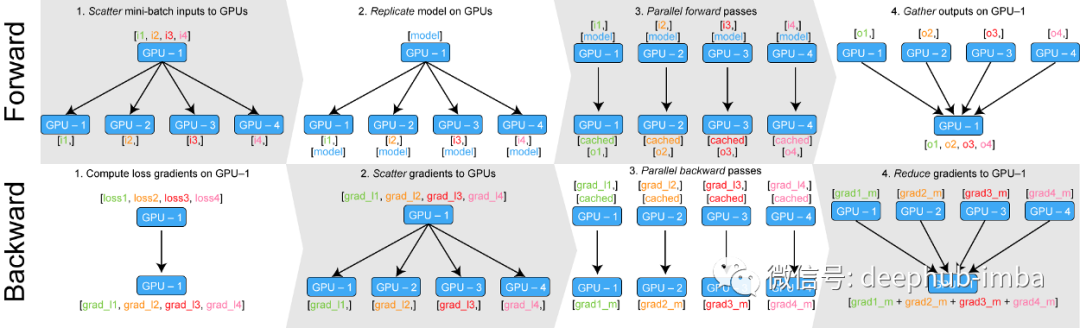
多GPU下的forward和backward
基本上,给定的输入通过在批处理维度中分块在GPU之间进行分配。在前向传递中,模型在每个设备上复制,每个副本处理批次的一部分。在向后传递过程中,将每个副本的梯度求和以生成最终的梯度,并将其应用于主gpu(上图中的GPU-1)以更新模型权重。在下一次迭代中,主GPU上的更新模型将再次复制到每个GPU设备上。
在PyTorch中,只需要一行就可以使用nn.DataParallel进行分布式训练。该模型只需要包装在nn.DataParallel中。
model = torch.nn.DataParallel(model)
...
...
loss = ...
loss.backward()
优点:并行化多个GPU上的NN训练,因此与累积梯度相比,它减少了训练时间。因为代码更改很少,所以适合快速原型制作。
缺点:nn.DataParallel使用单进程多线程方法在不同的GPU上训练相同的模型。它将主进程保留在一个GPU上,并在其他GPU上运行不同的线程。由于python中的线程存在GIL(全局解释器锁定)问题,因此这限制了完全并行的分布式训练设置。
使用DistributedDataParallel
与nn.DataParallel不同,DistributedDataParallel在GPU上生成单独的进程进行多重处理,并利用GPU之间通信实现的完全并行性。但是,设置DistributedDataParallel管道比nn.DataParallel更复杂,需要执行以下步骤(但不一定按此顺序)。
将模型包装在torch.nn.Parallel.DistributedDataParallel中。
设置数据加载器以使用distributedSampler在所有GPU之间高效地分配样本。Pytorch为此提供了torch.utils.data.Distributed.DistributedSampler。设置分布式后端以管理GPU的同步。torch.distributed.init_process_group(backend ='nccl')。
pytorch提供了用于分布式通讯后端(nccl,gloo,mpi,tcp)。根据经验,一般情况下使用nccl可以通过GPU进行分布式训练,而使用gloo可以通过CPU进行分布式训练。在此处了解有关它们的更多信息https://pytorch.org/tutorials/intermediate/dist_tuto.html#advanced-topics
在每个GPU上启动单独的进程。同样使用torch.distributed.launch实用程序功能。假设我们在群集节点上有4个GPU,我们希望在这些GPU上用于设置分布式培训。可以使用以下shell命令来执行此操作。
python -m torch.distributed.launch --nproc_per_node=4
--nnodes=1 --node_rank=0
--master_port=1234 train.py <OTHER TRAINING ARGS>
在设置启动脚本时,我们必须在将运行主进程并用于与其他GPU通信的节点上提供一个空闲端口(在这种情况下为1234)。
以下是涵盖所有步骤的完整PyTorch要点。
import argparse
import torch
from torch.utils.data.distributed import DistributedSampler
from torch.utils.data import DataLoader
#prase the local_rank argument from command line for the current process
parser = argparse.ArgumentParser()
parser.add_argument("--local_rank", default=0, type=int)
args = parser.parse_args()
#setup the distributed backend for managing the distributed training
torch.distributed.init_process_group('nccl')
#Setup the distributed sampler to split the dataset to each GPU.
dist_sampler = DistributedSampler(dataset)
dataloader = DataLoader(dataset, sampler=dist_sampler)
#set the cuda device to a GPU allocated to current process .
device = torch.device('cuda', args.local_rank)
model = model.to(device)
model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[args.local_rank],
output_device=args.local_rank)
#Start training the model normally.
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
preds = model(inputs)
loss = loss_fn(preds, labels)
loss.backward()
optimizer.step()
请注意,上述实用程序调用是针对GPU集群上的单个节点的。此外,如果要使用多节点设置,则必须在选择启动实用程序时选择一个节点作为主节点,并提供master_addr参数,如下所示。假设我们有2个节点,每个节点有4个GPU,第一个IP地址为“ 192.168.1.1”的节点是主节点。我们必须分别在每个节点上启动启动脚本,如下所示。
在第一个节点上运行
python -m torch.distributed.launch --nproc_per_node=4
--nnodes=1 --node_rank=0
--master_addr="192.168.1.1" --master_port=1234 train.py <OTHER TRAINING ARGS>
在第二个节点上,运行
python -m torch.distributed.launch --nproc_per_node=4
--nnodes=1 --node_rank=1
--master_addr="192.168.1.1" --master_port=1234 train.py <OTHER TRAINING ARGS>
其他实用程序功能:
在评估模型或生成日志时,需要从所有GPU收集当前批次统计信息,例如损失,准确率等,并将它们在一台机器上进行整理以进行日志记录。PyTorch提供了以下方法,用于在所有GPU之间同步变量。
- torch.distributed.gather(input_tensor,collect_list,dst):从所有设备收集指定的input_tensor并将它们放置在collect_list中的dst设备上。
- torch.distributed.all_gather(tensor_list,input_tensor):从所有设备收集指定的input_tensor并将其放置在所有设备上的tensor_list变量中。
- torch.distributed.reduce(input_tensor,dst,reduce_op = ReduceOp.SUM):收集所有设备的input_tensor并使用指定的reduce操作(例如求和,均值等)进行缩减。最终结果放置在dst设备上。
- torch.distributed.all_reduce(input_tensor,reduce_op = ReduceOp.SUM):与reduce操作相同,但最终结果被复制到所有设备。
有关参数和方法的更多详细信息,请阅读torch.distributed软件包。https://pytorch.org/docs/stable/distributed.html
例如,以下代码从所有GPU提取损失值,并将其减少到主设备(cuda:0)。
#In continuation with distributedDataParallel.py abovedef get_reduced_loss(loss, dest_device):
loss_tensor = loss.clone()
torch.distributed.reduce(loss_tensor, dst=dest_device)
return loss_tensorif args.local_rank==0:
loss_tensor = get_reduced_loss(loss.detach(), 0)
print(f'Current batch Loss = {loss_tensor.item()}'
优点:相同的代码设置可用于单个GPU,而无需任何代码更改。单个GPU设置仅需要具有适当设置的启动脚本。
缺点:BatchNorm之类的层在其计算中使用了整个批次统计信息,因此无法仅使用一部分批次在每个GPU上独立进行操作。PyTorch提供SyncBatchNorm作为BatchNorm的替换/包装模块,该模块使用跨GPU划分的整个批次计算批次统计信息。请参阅下面的示例代码以了解SyncBatchNorm的用法。
network = .... #some network with BatchNorm layers in itsync_bn_network = nn.SyncBatchNorm.convert_sync_batchnorm(network)
ddp_network = nn.parallel.DistributedDataParallel(
sync_bn_network,
device_ids=[args.local_rank], output_device=args.local_rank)
总结
- 要在GPU之间拆分模型,请将模型拆分为sub_modules,然后将每个sub_module推送到单独的GPU。
- 要在GPU上拆分批次,请使用累积梯度nn.DataParallel或nn.DistributedDataParallel。
- 为了快速进行原型制作,可以首选nn.DataParallel。
- 为了训练大型模型并利用跨多个GPU的完全并行训练,应使用nn.DistributedDataParallel。
- 在使用nn.DistributedDataParallel时,用nn.SyncBatchNorm替换或包装nn.BatchNorm层。
作者:Nilesh Vijayrania
原文地址:https://nilesh0109.medium.com/distributed-neural-network-training-in-pytorch-5e766e2a9e62
deephub翻译组