
在本文中,我们将看到深度混合学习如何应用于时间序列数据,以及它是否与图像数据一样有效。
在这篇文章中,我将使用Kaggle的太阳黑子数据。如上所述,数据可以很容易地从GitHub项目TimeSeries-Using-TensorFlow下载。我鼓励大家使用谷歌协作笔记本,因为所需的模块已经安装好了,基础设施也准备好了。现在,让我们开始吧!
下载并加载数据
数据下载使用只需要一个简单的命令-
!wget — no-check-certificate https://raw.githubusercontent.com/adib0073/TimeSeries-Using-TensorFlow/main/Data/Sunspots.csv -O /tmp/sunspots.csv
下载完成后,我们可以使用pandas将数据加载到数据帧中。
# Loading the data as a pandas dataframe
df = pd.read_csv(‘/tmp/sunspots.csv’, index_col=0)
df.head()
我们可以浏览一下数据,如下图所示:
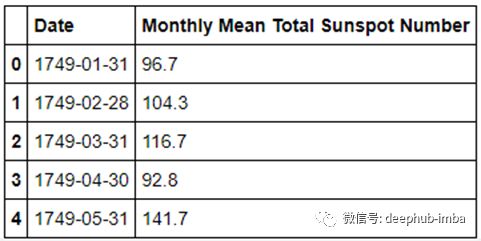
现在,我们应该做广泛的探索性数据分析(EDA)来了解数据的趋势和季节性。但在本例中,为了简单起见,我们将对数据进行目视检查。

准备数据
在这一步中,我们需要对加载的数据进行转换和处理,以便将其作为输入传递给深度混合学习模型,然后我们可以开始训练过程。我们可以把时间序列预测看作是一个有序的机器学习回归问题,把时间序列数据转换成一组特征值和相应的真值或目标值。由于回归是一个监督学习问题,我们需要目标值,目标值中滞后的时间序列数据变成这样的特征值:

我们将采用窗口或缓冲区方法,其中我们必须考虑适当的窗口大小。然后我们将序列或序列数据的窗口从左到右移动。我们将把窗口框右边的值作为目标值或真值。因此,每一次时间步,我们都会移动或移动窗口,以获得新的一行特征值和目标值对。这样我们就形成了训练数据和训练标签。以类似的方式,我们形成了测试和验证数据集,这是机器学习预测模型通常需要的。另外,请记住,对于一个预测模型来说,拥有更宽的观察窗口和更窄的预测窗口可以得到更好的结果。接下来,对于训练测试验证的分割比率,我们必须根据数据的大小计算出来。对于本例,我使用了0.8的分割比率,并且基于数据的季节性,我们将窗口大小设置为60。但是这些变量都是超参数,需要进行一些调整以获得可能的最佳结果。
代码如下:
# Convert the data values to numpy for better and faster processing
time_index = np.array(df['Date'])
data = np.array(df['Monthly Mean Total Sunspot Number'])
# Certain Hyper-parameters to tune
SPLIT_RATIO = 0.8
WINDOW_SIZE = 60
BATCH_SIZE = 32
SHUFFLE_BUFFER = 1000
# Dividing into train-test
split split_index = int(SPLIT_RATIO * data.shape[0])
# Train-Test Split
train_data = data[:split_index]
train_time = time_index[:split_index]
test_data = data[split_index:]
test_time = time_index[split_index:]
接下来,我们将准备一个为我们准备训练和测试数据的数据生成器。
def ts_data_generator(data, window_size, batch_size, shuffle_buffer):
'''
Utility function for time series data generation in batches
'''
ts_data = tf.data.Dataset.from_tensor_slices(data)
ts_data = ts_data.window(window_size + 1, shift=1, drop_remainder=True)
ts_data = ts_data.flat_map(lambda window: window.batch(window_size + 1))
ts_data = ts_data.shuffle(shuffle_buffer).map(lambda window: (window[:-1], window[-1]))
ts_data = ts_data.batch(batch_size).prefetch(1)
return ts_data
# Expanding data into tensors
tensor_train_data = tf.expand_dims(train_data, axis=-1)
tensor_test_data = tf.expand_dims(test_data, axis=-1)
tensor_train_dataset = ts_data_generator(tensor_train_data, WINDOW_SIZE, BATCH_SIZE, SHUFFLE_BUFFER)
tensor_test_dataset = ts_data_generator(tensor_test_data, WINDOW_SIZE, BATCH_SIZE, SHUFFLE_BUFFER)
现在,我们已经准备好将处理后的数据输入到模型中。
建立DHL模型和训练
我们将使用一个简单版本的深度混合学习架构来解决这个问题。如前所述,我们将使用带有后期融合技术的深度学习变体。模型架构是这样的:

这里我们使用一维CNN的组合模型提取初始序列特征,然后结合2个LSTM层进行特征提取部分,最后将其传递到传统DNN全连接层,产生最终输出。
模型架构的代码如下所示:
# DHL Fusion model of 1D CNN and LSTM
model = tf.keras.models.Sequential([
tf.keras.layers.Conv1D(filters=32, kernel_size=5,strides=1, padding="causal",activation="relu",input_shape=[None, 1]),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.LSTM(64, return_sequences=True),
tf.keras.layers.Dense(30, activation="relu"),
tf.keras.layers.Dense(10, activation="relu"),
tf.keras.layers.Dense(1)
])
接下来,我们需要选择其他超参数,如学习速率、优化器和损失函数。为了简单起见,我在这篇文章中不涉及选择这些值的问题。
optimizer = tf.keras.optimizers.SGD(lr=1e-4, momentum=0.9)
model.compile(loss=tf.keras.losses.Huber(),
optimizer=optimizer,
metrics=["mae"])
history = model.fit(tensor_train_dataset, epochs=200, validation_data=tensor_test_dataset)
模型评估
接下来我们将看到如何评估我们的模型。但首先,在训练过程之后,绘制模型损失曲线来看看模型是否真的在学习。
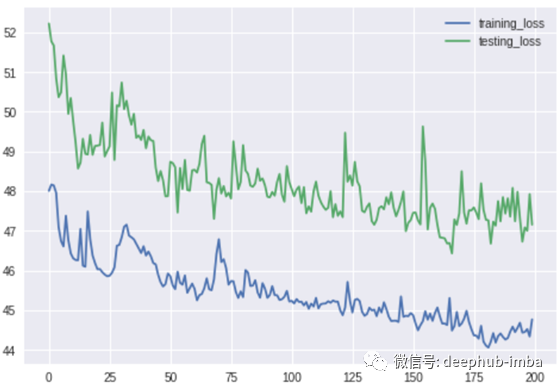
从模型损失曲线,我们确实看到过拟合的明显存在。在本文的最后,我将给出一些如何处理这个问题的提示,以使模型更好,但我们可以看到,随着训练时间的增加,模型损失在减少,这是一个很好的迹象,表明模型正在学习。
现在,对于模型评估,我们需要选择一个度量标准。在以后的一篇文章中,我将包括时间序列数据的各种模型评估指标。但在这种情况下,我们将使用MAE作为度量标准。
def model_forecast(model, data, window_size):
ds = tf.data.Dataset.from_tensor_slices(data)
ds = ds.window(window_size, shift=1, drop_remainder=True)
ds = ds.flat_map(lambda w: w.batch(window_size))
ds = ds.batch(32).prefetch(1)
forecast = model.predict(ds)
return forecastrnn_forecast = model_forecast(model, data[..., np.newaxis], WINDOW_SIZE) rnn_forecast = rnn_forecast[split_index - WINDOW_SIZE:-1, -1, 0]# Overall Error
error = tf.keras.metrics.mean_absolute_error(test_data, rnn_forecast).numpy()
print(error)
我们得到的MAE值大约是40。这还不错,但对这个案子来说有点高了。模型误差更大的原因是我们看到的初始过拟合。
模型结果可视化
作为最后一步,让我们将通过测试数据得到的结果可视化,并检查模型是否接近,以预测良好的结果。
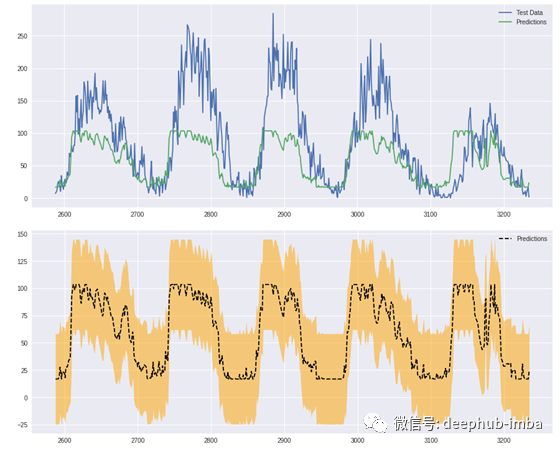
从第一张图可以看出,预测值与实际值的季节变化规律和趋势是相似的,但峰值没有实际值高。同时,由于时间序列预测应该是区间预测而不是单点估计,我们将使用错误率来形成置信区间或置信带。我们可以看到误差带很宽,这意味着模型的置信度不高,可能会有一些预测误差。
可视化的代码如下:
plt.figure(figsize=(15, 6))
plt.plot(list(range(split_index,len(data))), test_data, label = 'Test Data')
plt.plot(list(range(split_index,len(data))), rnn_forecast, label = 'Predictions')
plt.legend()
plt.show() plt.figure(figsize=(15, 6))
# Plotting with Confidence Intervals
plt.plot(list(range(split_index,len(data))), rnn_forecast, label = 'Predictions', color = 'k', linestyle = '--')
plt.fill_between(range(split_index,len(data)), rnn_forecast - error, rnn_forecast + error, alpha = 0.5, color = 'orange')
plt.legend()
plt.show()
我们有一个用于时间序列预测的深度混合学习模型,我们使用TensorFlow来形成模型并实现流。
但如果你想知道如何提高结果,我有以下建议:
- 更改窗口大小(增加或减少)
- 使用更多的训练数据(以解决过拟合问题)
- 使用更多的模型层或隐藏的单元
- 使用不同的损失函数和学习速率
- 我们看到损失曲线不是平滑的。如果批处理规模很小,通常会发生这种情况,所以尝试使用更大的批处理规模。
有时,更简单的模型可能会得到更好的结果。在我使用TensorFlow的深度学习进行后期时间序列预测时,我只使用了一个简单的深度神经网络就得到了更好的结果。现在,不同于图像数据,我们看到,在时间序列数据中,深度混合学习并不比传统的深度学习、机器学习或统计方法好多少。但是,在做了彻底的超参数调优之后,我确信结果会更好!
作者:Aditya Bhattacharya
deephub翻译组