
机器学习算法通常使用例如 kFold等的交叉验证技术来提高模型的准确度。在交叉验证过程中,预测是通过拆分出来的不用于模型训练的测试集进行的。这些预测被称为折外预测(out-of-fold predictions)。折外预测在机器学习中发挥着重要作用,可以提高模型的泛化性能。
在本文中,将介绍机器学习中的折外预测,主要包括以下几个方面:
- 折外预测是对不用于训练模型的数据进行的一种样本外预测。
- 在对看不见的数据进行预测时,折外预测最常用于估计模型的性能。
- 折外预测可用于构建集成模型,称为堆叠泛化或堆叠集成。
什么是折外预测?
使用重采样技术例如 k-fold来评估机器学习算法在数据集上的性能是一种很常见的方法。k-fold 过程包括将训练数据集分成 k 组,然后在使用 k 组样本中的每一个作为测试集,而其余样本用作训练集。
这意味着训练和评估了 k 个不同的模型。这个过程可以总结如下:
1、随机打乱数据集。
2、将数据集分成 k 组。
3、对于每个独特的组:将该组作为一个保留数据用做测试,将剩余的组作为训练数据集,在训练集上拟合模型并在测试集上进行评估,重复k次使得每一组保留数据都进行了测试。
4、最后预测时使用训练出的K个模型进行整合预测。
数据样本中的每个数据都被分配到一个单独的组中,并在整个过程中保持在该组中。这意味着每个样本都有机会在 作为测试集保留至少1次,并作为训练集最多 k-1 次。折外预测是在重采样过程中对每组得保留数据(测试集)所做的那些预测。如果正确执行,训练数据集中的每个数据都会有一个预测。
折外预测的概念与样本外预测(Out-of-Sample )的概念直接相关,因为这两种情况下的预测都是在模型训练期间未使用的样本上进行的,并且都可以估计模型在对新数据进行预测时的性能。折外预测也是一种样本外预测,尽管它使用了k-fold交叉验证来评估模型。
下面我们看看折外预测的两个主要功能
使用折外预测进行模型的评估
折外预测最常见的用途是评估模型的性能。使用诸如错误或准确率之类的评分指标对未用于模型训练的数据进行预测和评估。相当用于使用了新数据(训练时不可见的数据)进行预测和对模型性能的估计,使用不可见的数据可以评估模型的泛化性能,也就是模型是否过拟合了。
对模型在每次训练期间所做的预测进行评分,然后计算这些分数的平均值是最常用的模型评估方法。例如,如果一个分类模型,可以在每组预测上计算分类准确度,然后将性能估计为对每组折外预测估计的平均分数。
下面可以通过一个小的示例展示使用折外预测的模型评估。首先,使用 scikit-learn 的make_blobs() 函数创建一个包含 1,000 个样本、两个类和 100 个输入特征的二元分类问题。
下面的代码准备了一个数据样本并打印了数据集的输入和输出元素的形状。
from sklearn.datasets import make_blobs
# create the inputs and outputs
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# summarize the shape of the arrays
print(X.shape, y.shape)
运行该示例会打印输入数据的形状,显示 1,000 行数据和 100 列或输入特征以及相应的分类标签。
下一步使用 KFold 来对数据进行分组训练 KNeighborsClassifier 模型。
我们将对 KFold 使用 k=10参数,这是合理的默认值,在每组数据上拟合一个模型,并在每组的保留数据上进行测试评估。
评分保存在每个模型评估的列表中,并打印这些分数的平均值和标准差。
# evaluate model by averaging performance across each fold
from numpy import mean
from numpy import std
from sklearn.datasets import make_blobs
from sklearn.model_selection import KFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# create the inputs and outputs
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# k-fold cross validation
scores = list()
kfold = KFold(n_splits=10, shuffle=True)
# enumerate splits
for train_ix, test_ix in kfold.split(X):
# get data
train_X, test_X = X[train_ix], X[test_ix]
train_y, test_y = y[train_ix], y[test_ix]
# fit model
model = KNeighborsClassifier()
model.fit(train_X, train_y)
# evaluate model
yhat = model.predict(test_X)
acc = accuracy_score(test_y, yhat)
# store score
scores.append(acc)
print('> ', acc)
# summarize model performance
mean_s, std_s = mean(scores), std(scores)
print('Mean: %.3f, Standard Deviation: %.3f' % (mean_s, std_s))
注意:结果可能会因算法或评估过程的随机性或数值精度的差异而有所不同。在运行结束时,打印的分数的平均值和标准差如下:
> 0.95
> 0.92
> 0.95
> 0.95
> 0.91
> 0.97
> 0.96
> 0.96
> 0.98
> 0.91
Mean: 0.946, Standard Deviation: 0.023
除对每个模型的预测评估进行平均以外,还可以将每个模型的预测聚合成一个列表,这个列表中包含了每组训练时作为测试集的保留数据的汇总。在所有的模型训练完成后将该列表作为一个整体以获得单个的准确率分数。
使用这种方法是考虑到每个数据在每个测试集中只出现一次。也就是说,训练数据集中的每个样本在交叉验证过程中都有一个预测。所以可以收集所有预测并将它们与目标结果进行比较,并在整个训练结束后计算分数。这样的好处是更能突出模型的泛化性能。
完整的代码如下
# evaluate model by calculating the score across all predictions
from sklearn.datasets import make_blobs
from sklearn.model_selection import KFold
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
# create the inputs and outputs
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# k-fold cross validation
data_y, data_yhat = list(), list()
kfold = KFold(n_splits=10, shuffle=True)
# enumerate splits
for train_ix, test_ix in kfold.split(X):
# get data
train_X, test_X = X[train_ix], X[test_ix]
train_y, test_y = y[train_ix], y[test_ix]
# fit model
model = KNeighborsClassifier()
model.fit(train_X, train_y)
# make predictions
yhat = model.predict(test_X)
# store
data_y.extend(test_y)
data_yhat.extend(yhat)
# evaluate the model
acc = accuracy_score(data_y, data_yhat)
print('Accuracy: %.3f' % (acc))
每个保留数据集的所有预期值和预测值在运行结束时打印出单个准确度得分。
Accuracy: 0.930
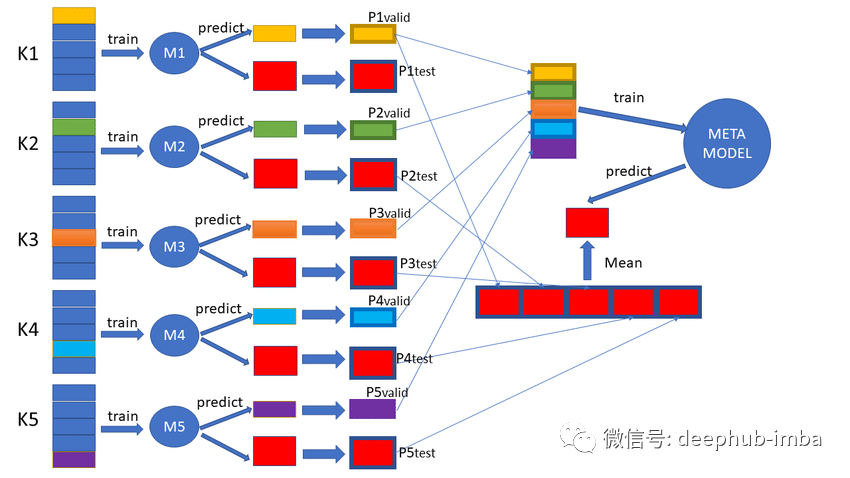
除了对模型评估以外,折外预测的最大作用就是可以进行模型的集成,提高泛化能力。
折外预测进行模型集成
集成学习是一种机器学习的方法,它在同一训练数据上训练多个模型,并将多个模型的预测进行集成以提高整体的性能。这也是在进行机器学习竞赛时最常见方法。
首先,对每个模型都进行进行交叉验证并收集所有的折外预测。需要注意的是每个模型执行数据拆分必须是相同的。这样就可以获得所有的折外预测。这样就获得了Base-Model:在训练数据集上使用 k 折交叉验证评估的模型,并保留所有非折叠预测。
下一步根据其他模型的预测训练一个高阶模型(也被称为Meta-Model)。这个模型的工作是学习如何最好地结合和纠正其他模型使得这些(其他)模型的折外预测能够获得更好的性能。
听起来很绕口,下面还是使用一个简单的二分类问题进行解释,首先训练一个决策树和一个 k 最近邻模型作为Base-Model。每个Base-Model通过 折外预测为训练数据集中的每个样本预测 0 或 1。这些预测与输入数据一起输入到高阶模型(Meta-Model)中。
- Meta-Model输入:Base-Model的输入特征+Base-Model的预测。
- Meta-Model输出:样本的目标(与Base-Models相同)。
为什么要使用折外预测来训练Meta-Model?
在整个训练数据集上训练Base-Model,然后对训练数据集中的每个样本进行预测,并将预测用作Meta-Model的输入,这样其实所有的样本都用Meta-Model训练,预测肯定比正常情况更好(非常容易产生过拟合),并且Meta-Model可能不会对纠正Base-Model预测产生任何的帮助,甚至会使结果变差。
但是使用Base-Model的折外预测来训练Meta-Model,Meta-Model可以是使用Base-Model看不见的数据进行操作,可以获得Base-Model对新数据预测行为的不足并通过训练来纠正Base-Model的问题,这就像使用集成学习时的情况一样:使用的都是训练时不可见的新数据。
通过交叉验证每个Base-Model也都是在整个数据集上进行训练,这些最终的Base-Model和Meta-Model可用于对新数据进行预测。这个过程可以总结如下:
- 对于每个Base-Model,使用交叉验证训练并保存折外预测。
- 使用Base-Model中的折外预测进行Meta-Model的训练。
这一过程称为Stacked Generalization(堆叠泛化)简称堆叠。通常使用线性加权和作为Meta-Model,这个过程有时✌被称为blending。
代码实现
这里可以使用上一节中相同数据详细介绍这个过程。首先将数据拆分为训练和验证数据集。训练数据集将用于拟合Base-Model和Meta-Model,验证数据集将在训练结束时用于评估Meta-Model和Base-Model。
X, X_val, y, y_val = train_test_split(X, y, test_size=0.33)
下一步使用 交叉验证来拟合每折的 DecisionTreeClassifier 和 KNeighborsClassifier 模型并保存折外预测。这些模型将输出概率而不是类别标签,因为需要为Meta-Model提供更有用的输入特征。。
# collect out of sample predictions
data_x, data_y, knn_yhat, cart_yhat = list(), list(), list(), list()
kfold = KFold(n_splits=10, shuffle=True)
for train_ix, test_ix in kfold.split(X):
# get data
train_X, test_X = X[train_ix], X[test_ix]
train_y, test_y = y[train_ix], y[test_ix]
data_x.extend(test_X)
data_y.extend(test_y)
# fit and make predictions with cart
model1 = DecisionTreeClassifier()
model1.fit(train_X, train_y)
yhat1 = model1.predict_proba(test_X)[:, 0]
cart_yhat.extend(yhat1)
# fit and make predictions with cart
model2 = KNeighborsClassifier()
model2.fit(train_X, train_y)
yhat2 = model2.predict_proba(test_X)[:, 0]
knn_yhat.extend(yhat2)
以上的代码为Meta-Model构建了数据集,该数据集由输入数据的 100 个输入特征和来自 kNN 和决策树模型的两个预测概率组成。
下面的 create_meta_dataset() 函数 将折外的数据和预测作为输入,并为Meta-Model构建输入数据集。
def create_meta_dataset(data_x, yhat1, yhat2):
# convert to columns
yhat1 = array(yhat1).reshape((len(yhat1), 1))
yhat2 = array(yhat2).reshape((len(yhat2), 1))
# stack as separate columns
meta_X = hstack((data_x, yhat1, yhat2))
return meta_X
然后调用这个函数来为Meta-Model准备数据。
meta_X = create_meta_dataset(data_x, knn_yhat, cart_yhat)
将每个Base-Model拟合到整个训练数据集上,并使用验证集进行预测。
# fit final submodels
model1 = DecisionTreeClassifier()
model1.fit(X, y)
model2 = KNeighborsClassifier()
model2.fit(X, y)
然后在准备好的数据集上Meta-Model,这里我们使用 LogisticRegression 模型。
# construct meta classifier
meta_model = LogisticRegression(solver='liblinear')
meta_model.fit(meta_X, data_y)
最后,使用Meta-Model对保留数据集进行预测。首先通过Base-Model,输出用于构建Meta-Model的数据集,然后使用Meta-Model进行预测。把所有这些操作封装到stack_prediction() 的函数中。
# make predictions with stacked model
def stack_prediction(model1, model2, meta_model, X):
# make predictions
yhat1 = model1.predict_proba(X)[:, 0]
yhat2 = model2.predict_proba(X)[:, 0]
# create input dataset
meta_X = create_meta_dataset(X, yhat1, yhat2)
# predict
return meta_model.predict(meta_X)
使用最初分割的保留数据集进行Base-Model的验证
# evaluate sub models on hold out dataset
acc1 = accuracy_score(y_val, model1.predict(X_val))
acc2 = accuracy_score(y_val, model2.predict(X_val))
print('Model1 Accuracy: %.3f, Model2 Accuracy: %.3f' % (acc1, acc2))
# evaluate meta model on hold out dataset
yhat = stack_prediction(model1, model2, meta_model, X_val)
acc = accuracy_score(y_val, yhat)
print('Meta Model Accuracy: %.3f' % (acc))
将上面所有的代码合并,完整的代码如下:
# example of a stacked model for binary classification
from numpy import hstack
from numpy import array
from sklearn.datasets import make_blobs
from sklearn.model_selection import KFold
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# create a meta dataset
def create_meta_dataset(data_x, yhat1, yhat2):
# convert to columns
yhat1 = array(yhat1).reshape((len(yhat1), 1))
yhat2 = array(yhat2).reshape((len(yhat2), 1))
# stack as separate columns
meta_X = hstack((data_x, yhat1, yhat2))
return meta_X
# make predictions with stacked model
def stack_prediction(model1, model2, meta_model, X):
# make predictions
yhat1 = model1.predict_proba(X)[:, 0]
yhat2 = model2.predict_proba(X)[:, 0]
# create input dataset
meta_X = create_meta_dataset(X, yhat1, yhat2)
# predict
return meta_model.predict(meta_X)
# create the inputs and outputs
X, y = make_blobs(n_samples=1000, centers=2, n_features=100, cluster_std=20)
# split
X, X_val, y, y_val = train_test_split(X, y, test_size=0.33)
# collect out of sample predictions
data_x, data_y, knn_yhat, cart_yhat = list(), list(), list(), list()
kfold = KFold(n_splits=10, shuffle=True)
for train_ix, test_ix in kfold.split(X):
# get data
train_X, test_X = X[train_ix], X[test_ix]
train_y, test_y = y[train_ix], y[test_ix]
data_x.extend(test_X)
data_y.extend(test_y)
# fit and make predictions with cart
model1 = DecisionTreeClassifier()
model1.fit(train_X, train_y)
yhat1 = model1.predict_proba(test_X)[:, 0]
cart_yhat.extend(yhat1)
# fit and make predictions with cart
model2 = KNeighborsClassifier()
model2.fit(train_X, train_y)
yhat2 = model2.predict_proba(test_X)[:, 0]
knn_yhat.extend(yhat2)
# construct meta dataset
meta_X = create_meta_dataset(data_x, knn_yhat, cart_yhat)
# fit final submodels
model1 = DecisionTreeClassifier()
model1.fit(X, y)
model2 = KNeighborsClassifier()
model2.fit(X, y)
# construct meta classifier
meta_model = LogisticRegression(solver='liblinear')
meta_model.fit(meta_X, data_y)
# evaluate sub models on hold out dataset
acc1 = accuracy_score(y_val, model1.predict(X_val))
acc2 = accuracy_score(y_val, model2.predict(X_val))
print('Model1 Accuracy: %.3f, Model2 Accuracy: %.3f' % (acc1, acc2))
# evaluate meta model on hold out dataset
yhat = stack_prediction(model1, model2, meta_model, X_val)
acc = accuracy_score(y_val, yhat)
print('Meta Model Accuracy: %.3f' % (acc))
上面的完整代码首先打印了决策树和 kNN 模型的准确性,然后打印最终Meta-Model在保留数据集上的性能,可以看到元模型的表现优于两个Base-Model。
Model1 Accuracy: 0.670, Model2 Accuracy: 0.930
Meta-Model Accuracy: 0.955
可以看到虽然模型1的准确率只有67%,但是通过折外预测的集成方法也对最终的结果产生的良好的影响。
总结
- 折外预测是对不用于训练模型的数据进行的一种样本外预测。
- 在对看不见的数据进行预测时,折外预测最常用于估计模型的性能。
- 折外预测还可用于构建集成模型,称为堆叠泛化或堆叠集成。
作者:Jason Brownlee PhD