
在文本自动理解的NLP任务中,命名实体识别(NER)是首要的任务。NER模型的作用是识别文本语料库中的命名实体例如人名、组织、位置、语言等。
NER模型可以用来理解一个文本句子/短语的意思。它可以识别文本中可能代表who、what和whom的单词,以及文本数据所指的其他主要实体。
在本文中,将介绍对文本数据执行 NER 的 3 种技术。这些技术将涉及预训练和定制训练的命名实体识别模型。
- 基于 NLTK 的预训练 NER
- 基于 Spacy 的预训练 NER
- 基于 BERT 的自定义 NER
基于NLTK的预训练NER模型:
NLTK包提供了一个经过预先训练的NER模型的实现,它可以用几行Python代码实现NER功能。NLTK包提供了一个参数选项:要么识别所有命名实体,要么将命名实体识别为它们各自的类型,比如人、地点、位置等。
如果binary=True,那么模型只会在单词为命名实体(NE)或非命名实体(NE)时赋值,否则对于binary=False,所有单词都将被赋值一个标签。
entities = []
tags = []
sentence = nltk.sent_tokenize(text)
for sent in sentence:
for chunk in nltk.ne_chunk(nltk.pos_tag(nltk.word_tokenize(sent)), binary=False):
if hasattr(chunk,'label'):
entities.append(' '.join(c[0] for c in chunk))
tags.append(chunk.label())
entities_tags = list(set(zip(entities,tags)))
entities_df = pd.DataFrame(entities_tags)
entities_df.columns = ["Entities","Tags"]
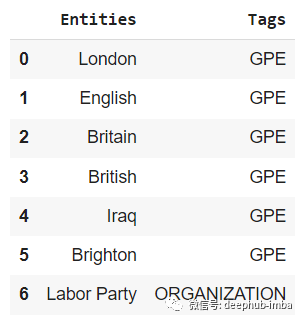
输入示例文本:

结果如下:
基于 Spacy 的预训练 NER
Spacy 包提供预训练的深度学习 NER 模型,可用文本数据的 NER 任务。Spacy 提供了 3 个经过训练的 NER 模型:en_core_web_sm、en_core_web_md、en_core_web_lg。
NER 模型可以使用 python -m spacy download en_core_web_sm 下载并使用 spacy.load(“en_core_web_sm”) 加载。
!python -m spacy download en_core_web_sm
import spacy
from spacy import displacy
nlp = spacy.load("en_core_web_sm")
doc = nlp(text)
entities, labels, position_start, position_end = [], [], [], []
for ent in doc.ents:
entities.append(ent)
labels.append(ent.label_)
position_start.append(ent.start_char)
position_end.append(ent.end_char)
df = pd.DataFrame({'Entities':entities,'Labels':labels,'Position_Start':position_start, 'Position_End':position_end})
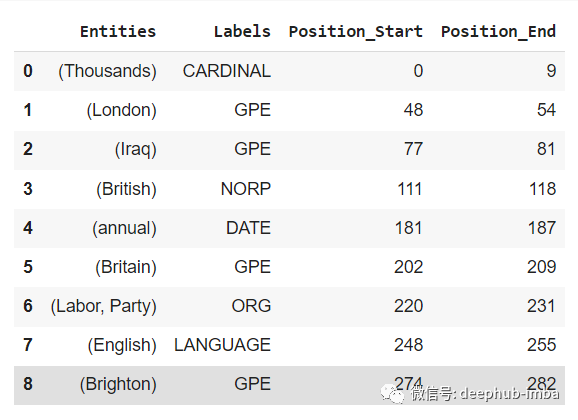
还是上面的文字,结果如下:
基于 BERT 的 NER
使用 NLTK 和 spacy 的 NER 模型的前两个实现是预先训练的,并且这些包提供了 API 以使用 Python 函数执行 NER。
对于某些自定义域,预训练模型可能表现不佳或可能未分配相关标签。这时可以使用transformer训练基于 BERT 的自定义 NER 模型。
# Import necessary packages
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from simpletransformers.ner import NERModel, NERArgs
# Read sample training NER data
data = pd.read_csv("sample_ner_dataset.csv", encoding="latin1")
data = data.fillna(method ="ffill")
# Label Encode
data["Sentence #"] = LabelEncoder().fit_transform(data["Sentence #"] )
data.rename(columns={"Sentence #":"sentence_id","Word":"words","Tag":"labels"}, inplace =True)
data["labels"] = data["labels"].str.upper()
# Train test split
X = data[["sentence_id","words"]]
Y = data["labels"]
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size =0.2)
# Building up train data and test data
train_data = pd.DataFrame({"sentence_id":x_train["sentence_id"],"words":x_train["words"],"labels":y_train})
test_data = pd.DataFrame({"sentence_id":x_test["sentence_id"],"words":x_test["words"],"labels":y_test})
# Initializing NER model configurations
label = data["labels"].unique().tolist()
args = NERArgs()
args.num_train_epochs = 1
args.learning_rate = 1e-4
args.overwrite_output_dir =True
args.train_batch_size = 32
args.eval_batch_size = 32
# Train BERT based NER model
model = NERModel('bert', 'bert-base-cased', labels=label, args=args)
model.train_model(train_data, eval_data=test_data, acc=accuracy_score)
# Evaluate the performance of NER model
result, model_outputs, preds_list = model.eval_model(test_data)
# Perform NER for inference text
inference_text = "What is the new name of Bangalore"
prediction, model_output = model.predict([inference_text])
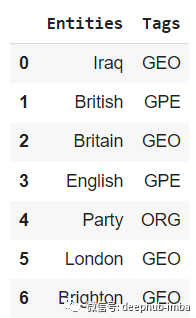
结果如下:
总结
基于 Spacy 的预训练 NER 模型的性能似乎是最好的,其中预测的各种标签非常接近人类的实际理解。Spacy NER 模型只需几行代码即可实现,并且易于使用。
基于 BERT 的自定义训练 NER 模型提供了类似的性能。定制训练的 NER 模型也适用于特定领域的任务。
NER 模型还有其他各种实现,本文未讨论,例如斯坦福 NLP 的预训练的 NER 模型,有兴趣的可以看看。