
DetectGPT的目的是确定一段文本是否由特定的llm生成,例如GPT-3。为了对段落 x 进行分类,DetectGPT 首先使用通用的预训练模型(例如 T5)对段落 xi 生成较小的扰动。然后DetectGPT将原始样本x的对数概率与每个扰动样本xi进行比较。如果平均对数比高,则样本可能来自源模型。
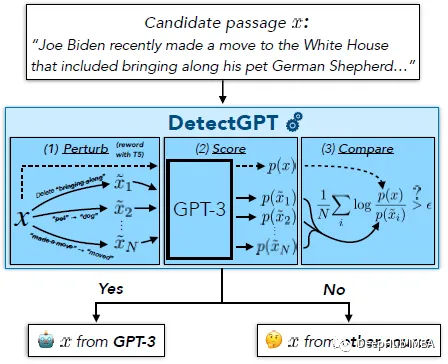
ChatGPT是一个热门话题。人们正在讨论是否可以检测到一篇文章是由大型语言模型(LLM)生成的。DetectGPT定义了一种新的基于曲率的准则,用于判断是否从给定的LLM生成。DetectGPT不需要训练单独的分类器,不需要收集真实或生成的段落的数据集,也不需要显式地为生成的文本加水印。它只使用由感兴趣的模型计算的对数概率和来自另一个通用预训练语言模型(例如T5)的文章随机扰动。
1、DetectGPT:随机排列和假设
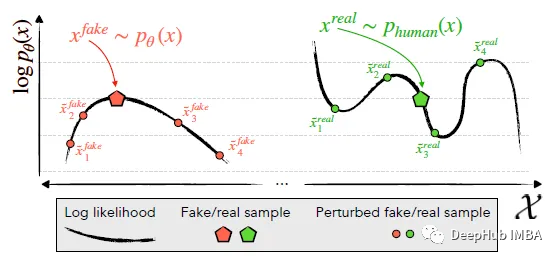
识别并利用了机器生成的通道xpθ(左)位于logp (x)的负曲率区域的趋势,其中附近的样本平均具有较低的模型对数概率。相比之下,人类书写的文本xpreal(.)(右)倾向于不占据具有明显负对数概率曲率的区域。
DetectGPT基于一个假设,即来自源模型pθ的样本通常位于pθ对数概率函数的负曲率区域,这是人类文本不同的。如果我们对一段文本 xpθ 应用小的扰动,产生 ~x,与人类编写的文本相比,机器生成的样本的数量 log pθ(x) - log pθ(x) 应该相对较大。利用这个假设,首先考虑一个扰动函数 q(.|x),它给出了在 ~x 上的分布,x 的略微修改版本具有相似的含义(通常考虑粗略的段落长度文本 x)。例如,q(.|x) 可能是简单地要求人类重写 x 的其中一个句子的结果,同时保留 x 的含义。使用扰动函数的概念,可以定义扰动差异 d (x; pθ, q):
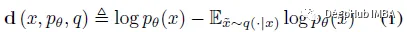
因此,下面的假设 4.1也就是:

如果q(.|x)是来自掩码填充模型(如T5)的样本而不是人类重写,那么假设4.1可以以自动的、可扩展的方式进行经验检验。
2、DetectGPT:自动测试
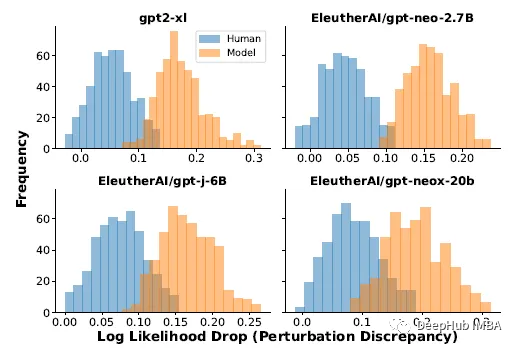
对一篇文章进行改写后,模型生成的文章的对数概率(扰动差异)的平均下降始终高于人工书写的文章
对于真实数据,使用了XSum数据集中的500篇新闻文章。当提示XSum中每篇文章的前30个令牌时,使用四个不同llm的输出。使用T5-3B施加扰动,遮蔽随机采样的2个单词跨度,直到文章中15%的单词被掩盖。上面公式(1)中的期望近似于T5中的100个样本。
上述实验结果表明,人写文章和模型样本的摄动差异分布有显著差异;模型样本往往有较大的扰动差异。根据这些结果,就可以通过简单地阈值扰动差异来检测一段文本是否由模型p生成。
通过用于估计 Ex q(.|x) log p (x) 的观测值的标准偏差对扰动差异进行归一化提供了更好的检测,通常将 AUROC 增加 0.020 左右, 所以在实验中使用了扰动差异的归一化版本。

DetectGPT 的检测过程伪代码
扰动差异可能是有用的,它测量的是什么还无法明确解释,所以作者在下一节中使用曲率进行解释。
3、将微扰差异解释为曲率
扰动差异近似于候选段落附近对数概率函数局部曲率的度量,更具体地说,它与对数概率函数的 Hessian 矩阵的负迹成正比。
这一节内容比较多,这里就不详细解释了,有兴趣的可以看看原论文,大概总结如下:
语义空间中的采样确保所有样本都保持在数据流形附近,因为如果随机添加扰动标记,预计对数概率总是下降。所以可以将目标解释为近似限制在数据流形上的曲率。
4、结果展示
零样本机器生成文本检测

每个实验使用150到500个例子进行评估。机器生成的文本是通过提示真实文本的前30个标记来生成的。使用AUROC)评估性能。
可以看到DetectGPT最大程度地提高了XSum故事的平均检测精度(AUROC提高0.1 )和SQuAD维基百科上下文(AUROC提高0.05 )。
对于15种数据集和模型组合中的14种,DetectGPT提供了最准确的检测性能,AUROC平均提高了0.06。
与有监督检测器的比较
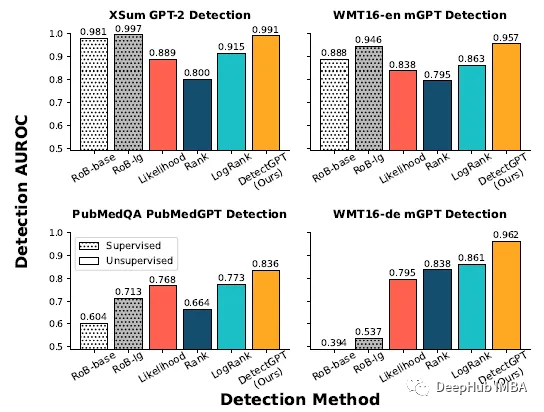
在真实文本和生成文本的大型数据集上训练的有监督的机器生成文本检测模型在分布内(顶部行)文本上的表现与DetectGPT一样好,甚至更好。零样本方法适用于新域(底部一行),如PubMed医学文本和WMT16中的德语新闻数据。
来自每个数据集的200个样本进行评估,监督检测器对英语新闻等分布内数据的检测性能与DetectGPT相似,但在英语科学写作的情况下,其表现明显差于零样本方法,而在德语写作中则完全失败。
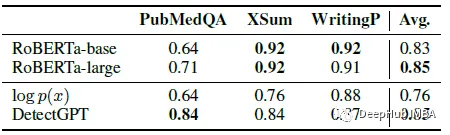
DetectGPT检测GPT-3的平均AUROC与专门为机器生成文本检测训练的监督模型相当。
从PubMedQA、XSum和writingprompt数据集中抽取了150个示例。将两种预训练的基于roberta的检测器模型与DetectGPT和概率阈值基线进行了比较。DetectGPT 可以提供与更强大的监督模型竞争的检测。
机器生成文本检测的变体
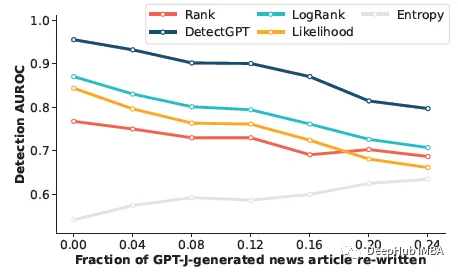
这部分是看检测器是否可以检测到人工编辑的机器生成文本。通过用 T5–3B 中的样本替换文本的 5 个单词跨度来模拟人工修订,直到 r% 的文本被替换。即使模型样本中近四分之一的文本已被替换,DetectGPT 仍能将检测 AUROC 保持在 0.8 以上。DetectGPT 显示了所有修订级别的最强检测性能。
本文作者:Sik-Ho Tsang
论文地址:DetectGPT: Zero-Shot Machine-Generated Text Detection using Probability Curvature,