使用YOLOV5训练自己的数据集(以王者荣耀为例)
使用yolov5训练自己的数据集
YOLOV8——快速训练指南(上手教程、自定义数据训练)
本篇主要用于说明如何使用自己的训练数据,快速在YOLOV8 框架上进行训练。当前(20230116)官方文档和网上的资源主要都是在开源的数据集上进行测试,对于算法“小白”或者“老鸟”如何快速应用到自己的项目中,这个单纯看官方文档显得有点凌乱,因为YOLOV8 不再致力于做一个单纯算法,而是想要做一个
模糊神经网络(FNN)的实现(Python,附源码及数据集)
本文对模糊神经网络(FNN)的理论基础及建模步骤进行介绍,之后使用Python实现基于FNN的数据预测,通俗易懂,适合新手学习,附源码及实验数据集。
Ubuntu20.04配置YOLOV5算法相关环境,并运行融合YOLOV5的ORB-SLAM2开源代码(亲测有效)
安装的软件主要是anaconda,然后anaconda可以帮我们安装python、pytorch这些东西。我的ubuntu版本:ubuntu20.04.5LTS。安装的python类型:python3.8.15,(原来系统自带的python是3.9.12)
Pytorch1.7复现PointNet++点云分割(含Open3D可视化)(文末有一个自己做的书缝识别项目代码)
毕设需要,复现一下PointNet++的对象分类、零件分割和场景分割,找点灵感和思路,做个踩坑记录。
RGB与Depth融合方法总结
RGB与Depth融合方法汇总
基于小波时频图和2D-CNN的滚动轴承故障检测
轴承故障诊断 附python和matlab代码
亲测有效解决torch.cuda.is_available()返回False的问题(分析+多种方案),点进不亏
文章目录解决torch.cuda.is_available()返回False出现返回False的原因问题1:版本不匹配问题2:错下成了cpu版本的(小编正是这种问题)解决方案方案一方案二解决torch.cuda.is_available()返回False出现返回False的原因问题1:版本不匹配电脑
对比学习MoCo损失函数infoNCE理解(附代码)
对比学习MoCo损失函数infoNCE理解
机器学习中的数学——距离定义(八):余弦距离(Cosine Distance)
余弦距离(Cosine Distance)也可以叫余弦相似度。 几何中夹角余弦可用来衡量两个向量方向的差异,机器学习中借用这一概念来衡量样本向量之间的差异。相比距离度量,余弦相似度更加注重两个向量在方向上的差异,而非距离或长度上。nnn维空间中的余弦距离为:cos(x,y)=x⋅y∣x∣⋅∣y∣=
SA的空间注意力和通道注意力
包括空间注意力和通道注意力,目的是选择细粒度的重要像素点,是pixel级。:是 local 注意力,致力于搜索粗糙的潜在判别区域,它们是region级。一般来说对于同一像素点不同通道求均值,再经过一些卷积和上采样的运算得到spitial attention mask,空间特征每层像素点被赋予不同的权
【图像分割】Segment Anything(Meta AI)论文解读
Segment Anything(SA)项目:一个图像分割新的任务、模型和数据集。建立了迄今为止最大的分割数据集,在11M许可和尊重隐私的图像上有超过1亿个mask。该模型的设计和训练是灵活的,因此它可以将zero-shot(零样本)转移到新的图像分布和任务。实验评估了它在许多任务上的能力,发现它的
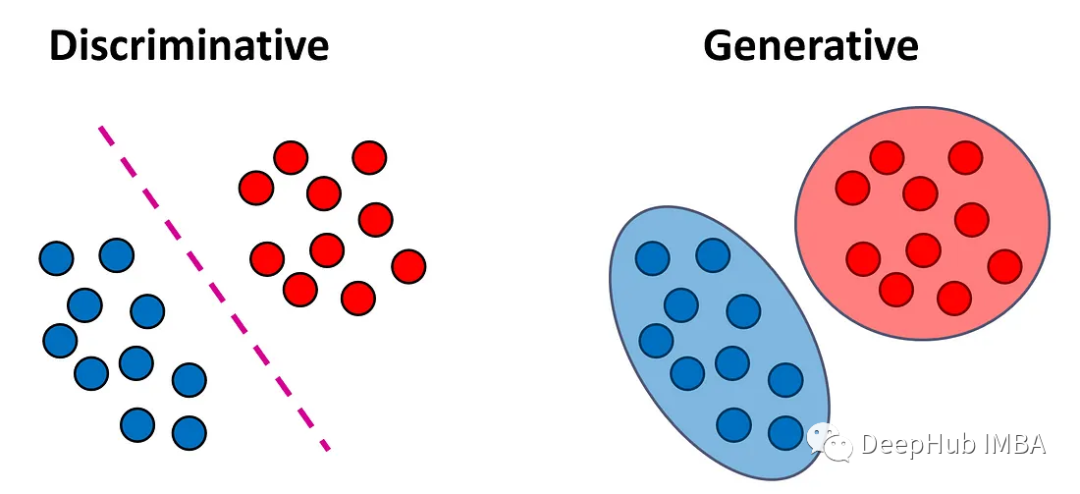
生成式模型与辨别式模型
分类模型可以分为两大类:生成式模型与辨别式模型。本文解释了这两种模型类型之间的区别,并讨论了每种方法的优缺点。
时间序列多步预测经典方法总结
本篇文章将讲解时间序列中的经典问题:多步预测,所谓多步预测就是利用过去的时间数据来预测未来多个状态的时序数据,举个例子就是利用过去30天的数据来预测未来2天的数据。
Gumbel-Softmax完全解析
本文对大部分人来说可能仅仅起到科普的作用,因为Gumbel-Max仅在部分领域会用到,例如GAN、VAE等。笔者是在研究EMNLP上的一篇论文时,看到其中有用Gumbel-Softmax公式解决对一个概率分布进行采样无法求导的问题,故想到对Gumbel-Softmax做一个总结,由此写下本文整个过程
【生成模型】Stable Diffusion原理+代码
Stable diffusion是一个基于(潜在扩散模型,LDMs)的文图生成(text-to-image)模型。具体来说,得益于的计算资源支持和在LAION-5B的一个子集数据支持训练,用于文图生成。通过在一个潜在表示空间中迭代“去噪”数据来生成图像,然后将表示结果解码为完整的图像,让文图生成能够
关系抽取(三)实体关系联合抽取:CasRel
实体关系抽取
深度强化学习(DRL)简介与常见算法(DQN,DDPG,PPO,TRPO,SAC)分类
简单介绍深度强化学习的基本概念,常见算法、流程及其分类(持续更新中),方便大家更好的理解、应用强化学习算法,更好地解决各自领域面临的前沿问题。欢迎大家留言讨论,共同进步。
Informer:比Transformer更有效的长时间序列预测
目录AAAI 2021最佳论文:比Transformer更有效的长时间序列预测BackgroundWhy attentionMethods:the details of InformerSolve_Challenge_1:最基本的一个思路就是降低Attention的计算量,仅计算一些非常重要的或者说
大型语言模型的推理演算
本文详细阐述了大型语言模型推理性能的几个基本原理,不含任何实验数据或复杂的数学公式,旨在加深读者对相关原理的理解。此外,作者还提出了一种极其简单的推理时延模型,该模型与实证结果拟合度高,可更好地预测和解释Transformer模型的推理过程。为了更好地阅读本文,读者需了解一些Transformer模



