利用Pytorch实现ResNet网络
ResNet在2015年由微软实验室提出,获得当年ImageNet竞赛中分类任务、目标检测第一名;获得COCO数据集目标检测、图像分割第一名
目标检测算法——YOLOv5/YOLOv7改进之结合PP-LCNet(轻量级CPU网络)
PP-LCNet——轻量级且超强悍的CPU级骨干网络!!PP-LCNet 在同样精度的情况下,速度远超当前所有的骨架网络!它应用在比如目标检测、语义分割等任务算法上,也可以使原本的网络有大幅度的性能提升。
yolov5源码解析(10)--损失计算与anchor
本文章基于yolov5-6.2版本。主要讲解的是yolov5在训练过程中是怎么由推理结果和标签来进行损失计算的。损失函数往往可以作为调优的一个切入点,所以我们首先要了解它。
yolov5篇---官方ultralytics / yolov5代码复现,训练自己的数据集
yolov5篇---官方ultralytics / yolov5代码复现,训练自己的数据集
深度学习:图像去雨网络实现Pytorch (二)一个简单实用的基准模型(PreNet)实现
详细介绍了一种简单实用的去雨模型PreNet在Pytorch框架下的搭建过程,供读者参考学习
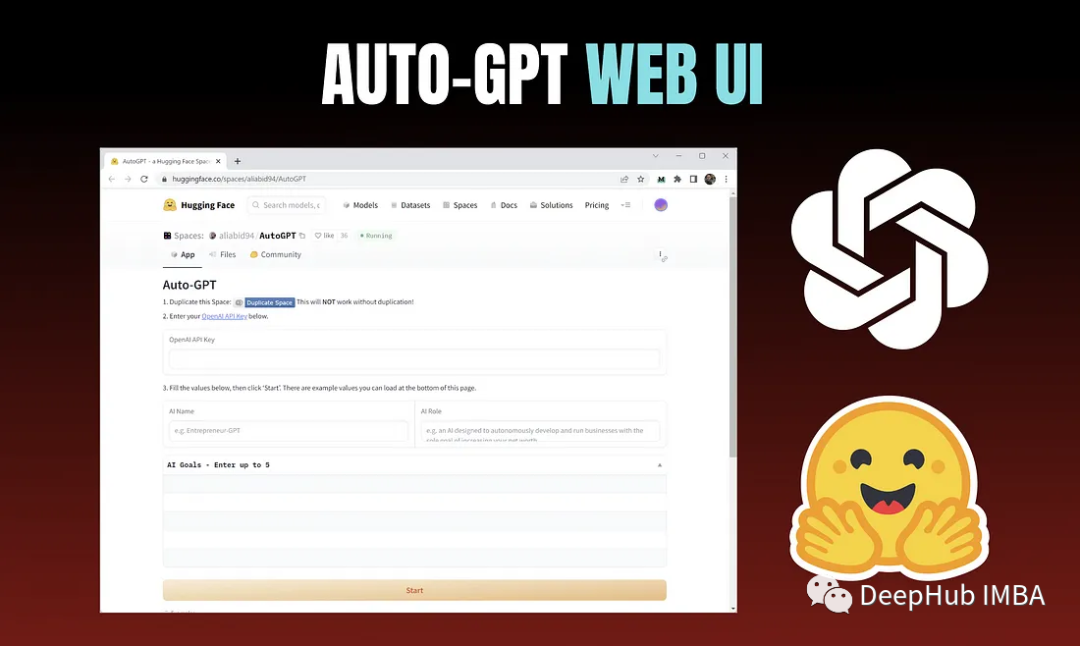
AutoGPT也有Web UI了
现在AutoGPT也有了Web UI,在本文中我们将介绍如何通过Web UI使用AutoGPT。
【v8初体验】利用yolov8训练COCO数据集或自定义数据集
YOLOv8保姆级动手把手攻略
注意力机制(含pytorch代码及各函数详解)
目录注意力机制非参注意力汇聚概述(不需要学习参数)参数化注意力机制概述正式系统学习1.平均汇聚(池化)2.非参数注意力汇聚(池化)3.带参数注意力汇聚注意力机制不随意线索:不需要有想法,一眼就看到的东西随意线索:想看书,所以去找了一本书1.卷积、全连接、池化层都只考虑不随意线索2.注意力机制则显示的
Win11基于WSL2安装CUDA、cuDNN和TensorRT(2023-03-01)
之前我写了一篇博客:[Win11安装WSL2和Nvidia驱动](https://blog.csdn.net/Apple_Coco/article/details/128374634),记录了在WSL2里安装CUDA,当时我选择了第二种安装方式,即用WSL2里的MiniConda去安装的PyTorc
pyton\yolov8安装和基础使用,训练和预测
到这里yolov8就安装好了,我这是cpu的版本,GPU本人也在摸索中,就不献丑了,如果不想在终端验证也可以到ultralytics-main\ultralytics\yolo\v8\detect\predict.py 这个python文件里把图片的路径修改然后运行就好了,图片路径和上面一样的。(这
ros中SLAM的EVO、APE测评——SLAM精度测评(一)
用于处理、评估和比较里程计和SLAM算法的轨迹输出。支持的轨迹格式:“TUM”轨迹文件“KITTI”姿态文件“EuRoC MAV”(.csv groundtruth和TUM轨迹文件)ROS和ROS2 BAG文件,带有几何图形/PoseStamped、几何图形/TransformStamped、几何图
Yolov8训练自己的数据集
用yolov8训练自己的数据集,熟悉yolov8整个流程,便于下一步魔改网络等
RKNN模型部署(3)—— 模型转换与测试
将pth模型转换成rknn模型,然后调用rknn模型进行测试
Pytorch优化器全总结(三)牛顿法、BFGS、L-BFGS 含代码
这篇文章是优化器系列的第三篇,主要介绍牛顿法、BFGS和L-BFGS,其中BFGS是拟牛顿法的一种,而L-BFGS是对BFGS的优化,那么事情还要从牛顿法开始说起。L-BFGS即Limited-memory BFGS。 L-BFGS的基本思想就是通过存储前m次迭代的少量数据来替代前一次的矩阵,从而大
详解Pytorch中的torch.nn.MSELoss函,包括对每个参数的分析!
详解Pytorch中的torch.nn.MSELoss函数,包括对每个参数的分析!
欠拟合的原因以及解决办法(深度学习)
之前这篇文章,我分析了一下深度学习中,模型过拟合的主要原因以及解决办法:过拟合的原因以及解决办法(深度学习)_大黄的博客-CSDN博客这篇文章中写一下深度学习中,模型欠拟合的原因以及一些常见的解决办法。也就是为什么我们设计的神经网络它不收敛?这里还是搬这张图出来,所谓欠拟合(也就是神经网络不收敛),
YOLOv5网络结构,训练策略详解
前面已经讲过了Yolov5模型目标检测和分类模型训练流程,这一篇讲解一下yolov5模型结构,数据增强,以及训练策略。
MAE详解
目录一、介绍二、网络结构1. encoder2. decoder3. LOSS三、实验全文参考:论文阅读笔记:Masked Autoencoders Are Scalable Vision Learners_塔_Tass的博客-CSDN博客masked autoencoders(MAE)是hekai
图像处理中常见的几种插值方法:最近邻插值、双线性插值、双三次插值(附Pytorch测试代码)
在学习可变形卷积时,因为学习到的位移量Δpn可能是小数,因此作者采用双线性插值算法确定卷积操作最终采样的位置。通过插值算法我们可以根据现有已知的数据估计未知位置的数据,并且可以利用这种方法对图像进行缩放、旋转以及几何校正等任务。此处我通过这篇文章学习总结常见的三种插值方法,包括最近邻插值、双线性插值
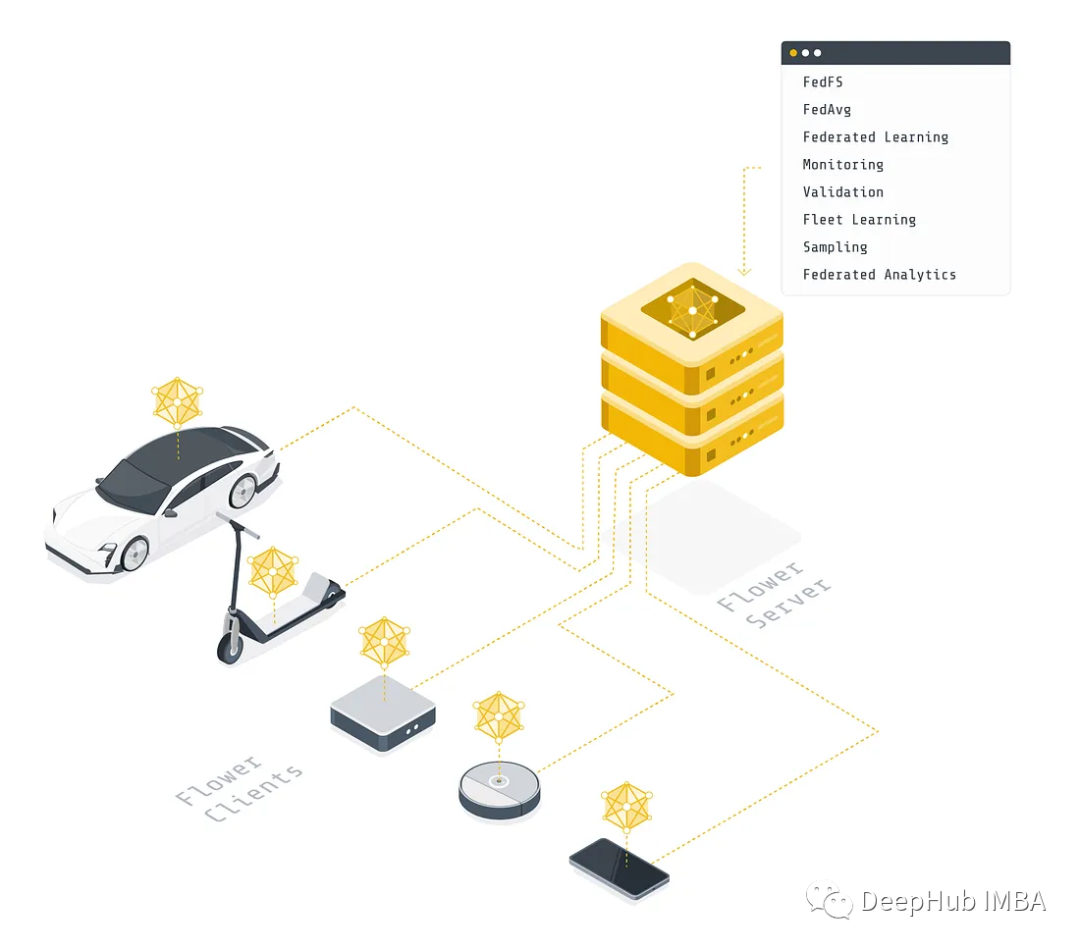
使用PyTorch和Flower 进行联邦学习
本文将介绍如何使用 Flower 构建现有机器学习工作的联邦学习版本。我们将使用 PyTorch 在 CIFAR-10 数据集上训练卷积神经网络,然后将展示如何修改训练代码以联邦的方式运行训练。



