
文章目录
前言
本文讲解使用halcon的语义分割是使用步骤,标注工具不使用halcon提供的标注工具,而是使用各个深度学习框架都使用的labelMe工具,然后使用hde脚本以及python脚本转化为标准的halcon训练及文件
本文涉及数据标注、数据转化、训练、评估、预测几个模块。
一、数据标注
语义分割数据标注主要使用labelImg工具,python安装只需要:pip install labelme 即可,然后在命令提示符输入:labelme即可,如图:
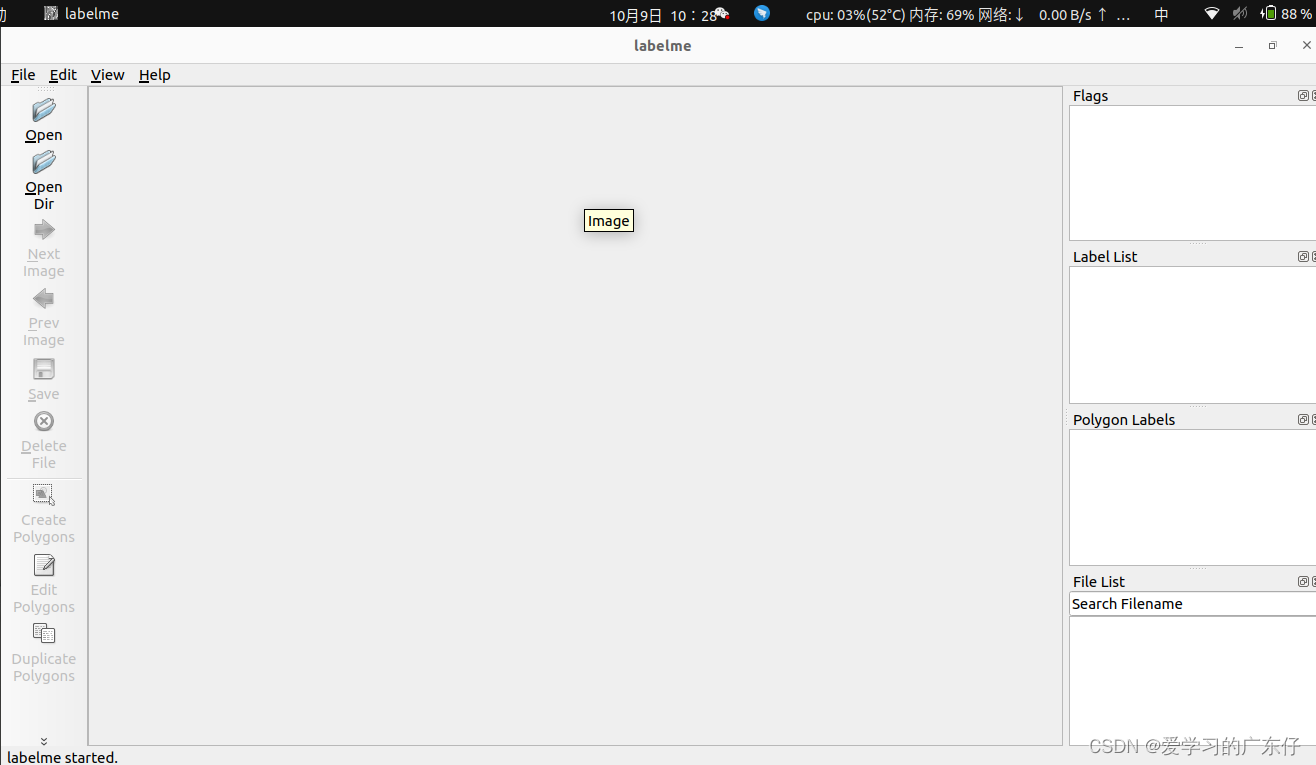
在这里只需要修改“OpenDir“,“OpenDir“主要是存放图片需要标注的路径
选择好路径之后即可开始绘制: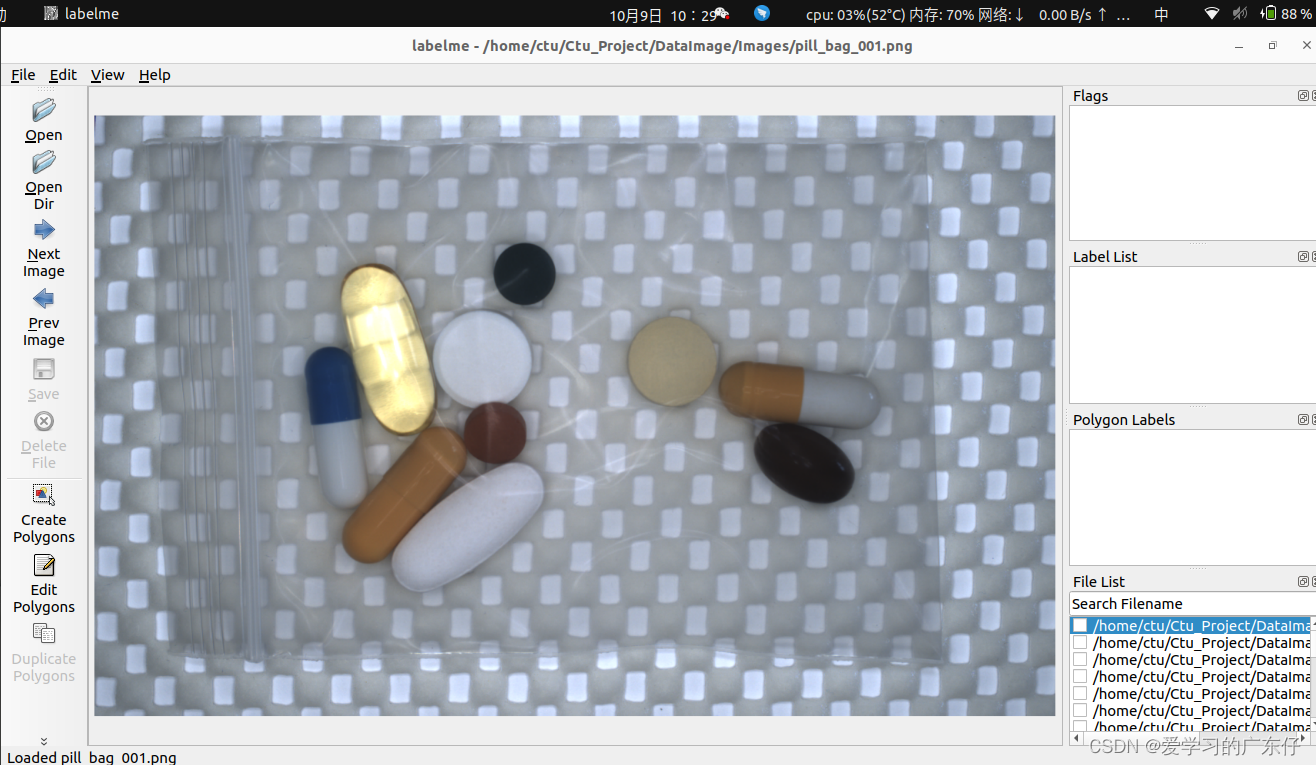
我在平时标注的时候快捷键一般只用到:
createpolygons:(ctrl+N)开始绘制
a:上一张
d:下一张
绘制过程如图: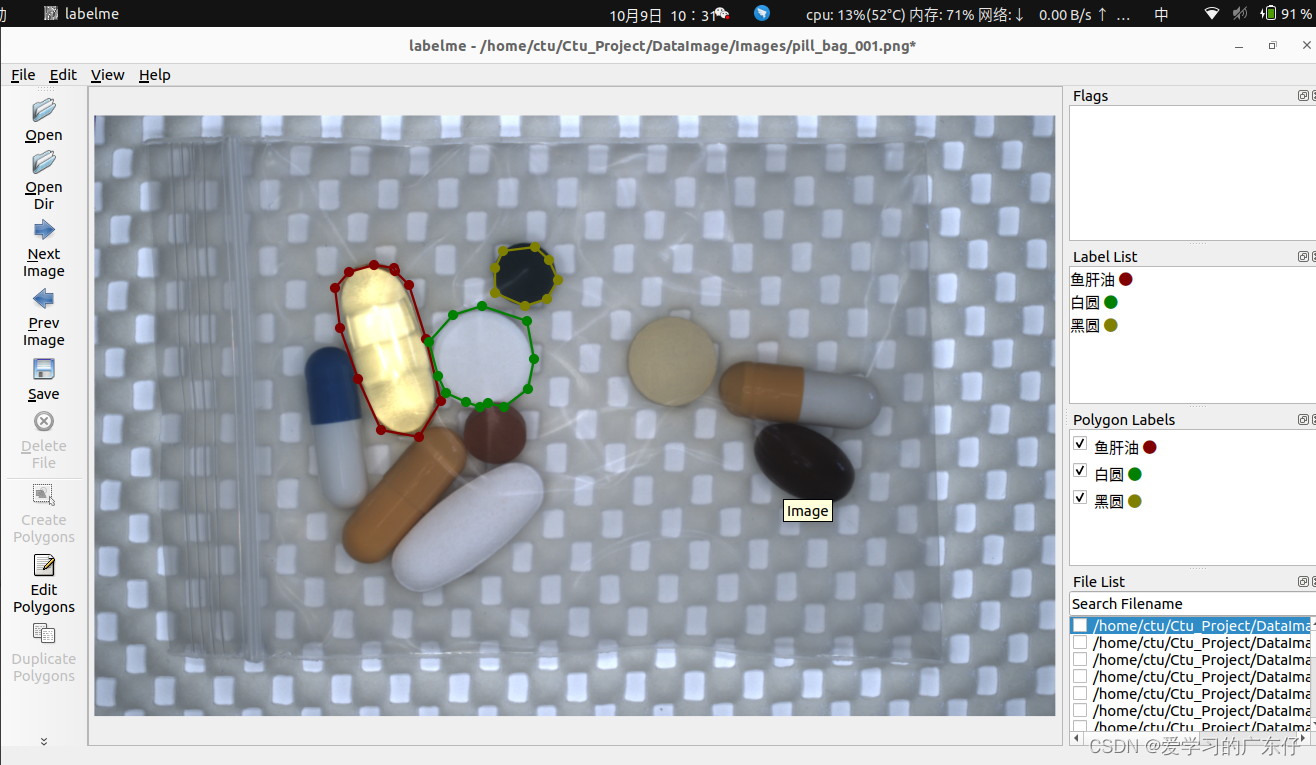
就只需要一次把目标绘制完成即可。
标注完的文件如图:
二、halcon训练预测流程步骤
本模块主要是做数据转换,转化为标准的halcon所需的训练文件
1.Json文件转label图片
本功能主要是解析所有的json文件,然后分别生成对应的label图片,classes.txt的类别文件
1.解析json
读取本地json获取本次标注的所有类别,以及得到各个类别的样本数:
All_label_name =['_background_']
label_name_dict ={}for each_img in ImgFile:if each_img.split('.')[0]+'.json'in JsonFile:
ParseDataList.append([each_img,each_img.split('.')[0]+'.json'])
data = json.load(open(os.path.join(JsonDir,each_img.split('.')[0]+'.json'),encoding='gbk'))for shape insorted(data['shapes'], key=lambda x: x['label']):
label_name = shape['label']if label_name notin All_label_name:
All_label_name.append(label_name)if label_name notin label_name_dict:
label_name_dict[label_name]=0
label_name_dict[label_name]+=1else:
ParseDataList.append([each_img,''])
All_label_name:得到的类别列表
label_name_dict:得到类别样本数字典
2.生成label图片
imageData = data.get('imageData')ifnot imageData:withopen(ImageFile,'rb')as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
label_name_to_value ={'_background_':0}for shape insorted(data['shapes'], key=lambda x: x['label']):
label_name = shape['label']if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]else:
label_value =len(label_name_to_value)
label_name_to_value[label_name]= label_value
img = utils.img_b64_to_arr(imageData)
lbl, _ = utils.shapes_to_label(
img.shape, data['shapes'], label_name_to_value
)
lbl:为图片文件,此脚本最后得到的效果图如图:
label的图像解析为:像素值为0的代表背景,像素值为1的代表类别1,像素值代表2的为类别2,以此类推
2.转化halcon训练所需的hdict
1.定义输入的文件路径以及输出的路径
* 存放图片的文件夹路径
imageDir:='../DataSet/DataImage'* 存放上边python生成的label文件夹路径
LabelDir:='../DataSet/Temp_SegDataSet/Labels'* 存放类别的classes.txt路径
classFile:='../DataSet/Temp_SegDataSet/classes.txt'* 生成的halcon训练所需的hdict
DataList:='../DataSet/Temp_SegDataSet/dataset.hdict'
备注:此处的hdict其实只是存放各种路径便于halcon对模型进行输入图片
2.读取classes.txt文件
open_file (classFile,'input', FileHandle)
repeat
fread_line(FileHandle, oneline, IsEOF)if(IsEOF ==1)break
endif
if(oneline ==' 'or oneline=='\n')continue
endif
tuple_regexp_replace (oneline,'\n','', oneline)
tuple_length (ClassIndex, Length)
ClassIndex[Length]:=Length
if(Length==0)
oneline:='background'
endif
tuple_concat (ClassID, oneline, ClassID)
until (IsEOF)
close_file (FileHandle)
3.设置halcon字典内容
tuple_remove (LabelFiles, Index1, LabelFiles)
tuple_length (ImageDict, Length)
create_dict (tempImgDist)
set_dict_tuple (tempImgDist,'image_id', Length)
set_dict_tuple (tempImgDist,'image_file_name', BaseName_Image +'.'+ Extension_Image)
set_dict_tuple (tempImgDist,'segmentation_file_name', BaseName_Label +'.'+ Extension_Label)
tuple_concat (ImageDict, tempImgDist, ImageDict)
4.hdict效果展示
使用hdevelop工具可以清楚看到hdict的文件内容如图: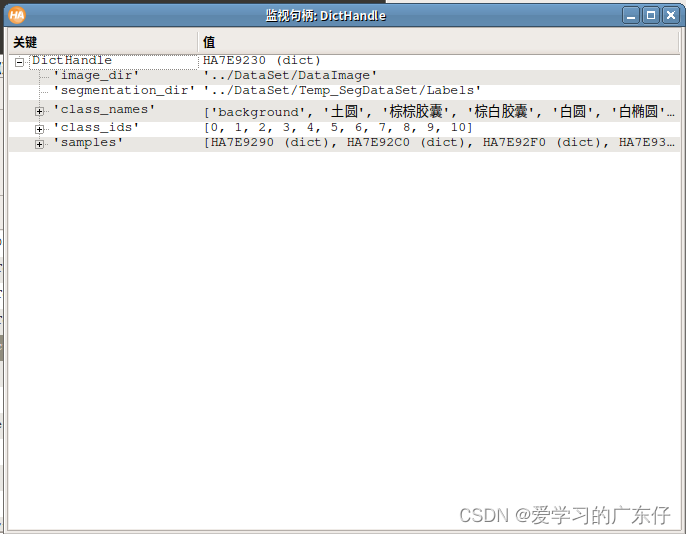
3.halcon脚本-模型训练
1.定义变量
这里主要是输入数据的变量路径
* 模型选择,此处是halcon的自带模型,halcon目前此版本无法自定义模型结构
Base_ModelFile:=['./DL_BaseModel/BaseModel_seg_compact.dat','./DL_BaseModel/BaseModel_seg_enhanced.dat']* 上边使用脚本的生成的hdict文件路径
TrainDataSetDict:='./DataSet/Temp_SegDataSet/dataset.hdict'* 原始图片的文件存放路径
ImageDir:='./DataSet/DataImage'* 上边生成的Label的文件存放路径
LabelDir:='./DataSet/Temp_SegDataSet/Labels'* 训练过程中生成的文件都存放到此文件夹中,后期训练完会自动删除
OutputDir:='./DataSet/Temp_SegDataSet/Output'* 模型最终保存文件
ModelFile:='./best_Seg.dat'
2.模型参数定义
此变量主要是模型训练的参数定义,可自行修改
* halcon提供的模型,这里选择第0个模型
ModelType:=0* 是否使用GPU
UseGpu:=true
* 每次迭代的batch_size,-1代表程序自己判断,以最大的可能去设置,否这可自行设置,
BatchSize :=-1* 学习率
lr :=0.0008* 优化器的参数,可设置0.99
Momentum :=0.9* 训练次数
NumEpochs :=120* 学习率在本次训练中修改的次数
LRChangeNum:=5* 验证集合每经过1次大迭代进行一次验证
EvaluationIntervalEpochs :=1* 随机数种子
SeedRand :=42* 设置模型的输入图像的宽度和高度以及通道数
ImageWidth :=512
ImageHeight :=512
ImageNumChannels :=3* 数据像素值预处理参数
ImageRangeMin :=-127
ImageRangeMax :=128* 归一化
NormalizationType :='true'* 巻积操作前的处理方式
DomainHandling :='full_domain'
3.读取数据集
这里主要是读取数据集然后分割数据集,按85%训练集和15%的验证集划分
read_dict (TrainDataSetDict,[],[], DLDataset)
get_dict_tuple (DLDataset,'class_ids', ClassIDs)
get_dict_tuple (DLDataset,'class_names', ClassNames)
set_dict_tuple (DLDataset,'image_dir', ImageDir)
set_dict_tuple (DLDataset,'segmentation_dir', LabelDir)
split_dl_dataset (DLDataset,85,15,[])
create_dl_preprocess_param ('segmentation', ImageWidth, ImageHeight, ImageNumChannels, ImageRangeMin, ImageRangeMax, NormalizationType, DomainHandling,[],[],[],[], DLPreprocessParam)
4.预现实标注效果
此功能不是必须的
if(ShowExample)
get_dict_tuple (DLDataset,'samples', DatasetSamples)
find_dl_samples (DatasetSamples,'split','train','match', SampleIndices)
tuple_shuffle (SampleIndices, ShuffledIndices)
read_dl_samples (DLDataset, ShuffledIndices[0:9], DLSampleBatchDisplay)
create_dict (WindowHandleDict)for Index :=0 to |DLSampleBatchDisplay|-1 by 1
dev_display_dl_data (DLSampleBatchDisplay[Index],[], DLDataset,['image','segmentation_image_ground_truth'],[], WindowHandleDict)
get_dict_tuple (WindowHandleDict,'segmentation_image_ground_truth', WindowHandleImage)
dev_set_window (WindowHandleImage[1])
Text :='Press Run (F5) to continue'
dev_disp_text (Text,'window',400,40,'black',[],[])
stop ()
endfor
dev_display_dl_data_close_windows (WindowHandleDict)
endif
5.学习率修改
此方式不是必须的,不过有会更好
if(|ChangeLearningRateEpochs|>0)
create_dict (ChangeStrategy)
set_dict_tuple (ChangeStrategy,'model_param','learning_rate')
set_dict_tuple (ChangeStrategy,'initial_value', lr)
set_dict_tuple (ChangeStrategy,'epochs', ChangeLearningRateEpochs)
set_dict_tuple (ChangeStrategy,'values', ChangeLearningRateValues)
GenParamName :=[GenParamName,'change']
GenParamValue :=[GenParamValue,ChangeStrategy]
endif
6.读取模型文件
read_dict (DLDatasetFileName,[],[], DLDataset)
open_file (Base_ModelFile[ModelType],'input_binary', FileHandle)
fread_serialized_item (FileHandle, SerializedItemHandle)
close_file (FileHandle)
deserialize_dl_model (SerializedItemHandle, DLModelHandle)
7.设置模型参数
get_dict_tuple (DLDataset,'preprocess_param', DLPreprocessParam)
get_dict_tuple (DLDataset,'class_ids', ClassIDs)
set_dl_model_param_based_on_preprocessing (DLModelHandle, DLPreprocessParam, ClassIDs)
set_dl_model_param (DLModelHandle,'learning_rate', lr)
set_dl_model_param (DLModelHandle,'momentum', Momentum)if(BatchSize ==-1)
set_dl_model_param_max_gpu_batch_size (DLModelHandle,100)else
set_dl_model_param (DLModelHandle,'batch_size', BatchSize)
endif
if(|WeightPrior|>0)
set_dl_model_param (DLModelHandle,'weight_prior', WeightPrior)
endif
set_dl_model_param (DLModelHandle,'runtime_init','immediately')
8.训练
create_dl_train_param (DLModelHandle, NumEpochs, EvaluationIntervalEpochs, EnableDisplay, SeedRand, GenParamName, GenParamValue, TrainParam)
train_dl_model (DLDataset, DLModelHandle, TrainParam,0.0, TrainResults, TrainInfos, EvaluationInfos)
训练效果图如图: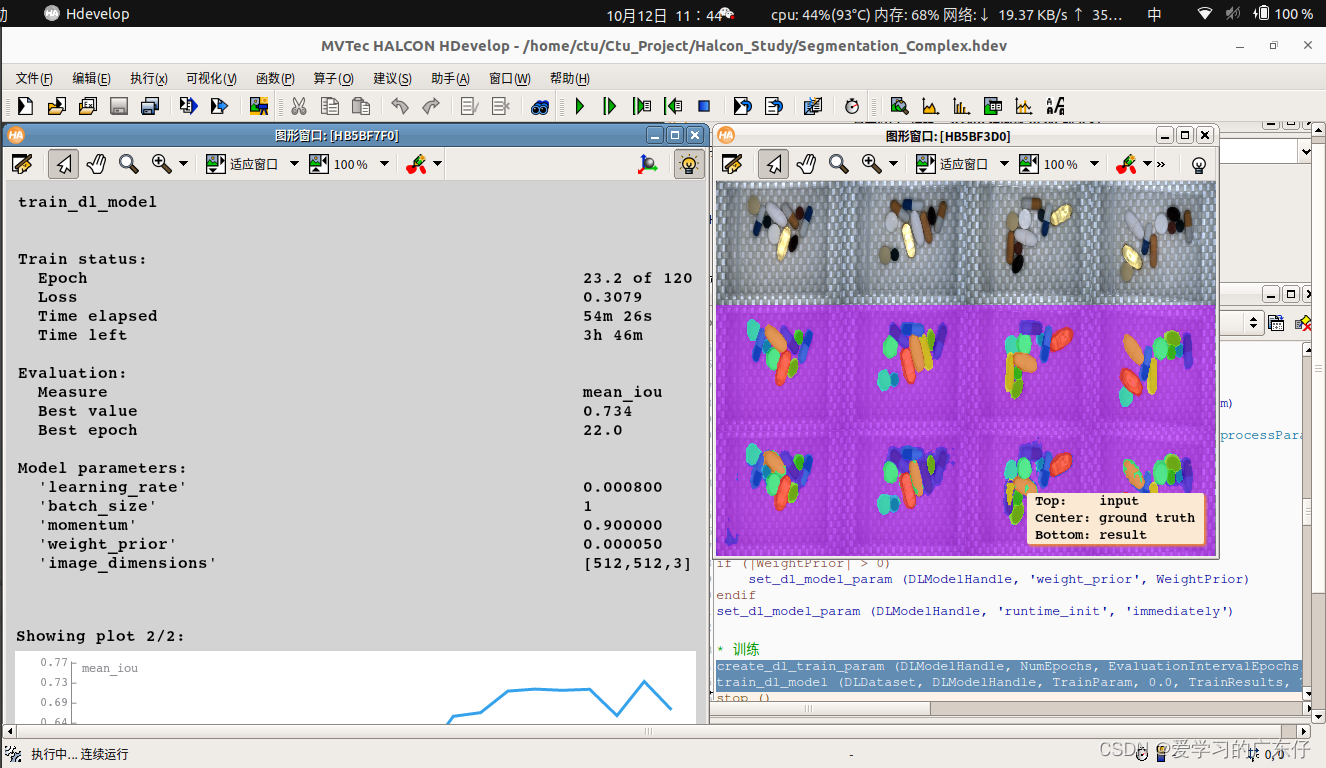
4.halcon脚本-模型评估
1.参数定义
RetrainedModelFileName := DataDirectory +'/best_model.hdl'
DLDatasetFileName := DataDirectory +'/dl_dataset.hdict'* 评估指标
SegmentationMeasures :=['mean_iou','pixel_accuracy','class_pixel_accuracy','pixel_confusion_matrix']
BatchSize :=1
UseGPU := true
* 评估验证集,可视化10张图
NumDisplay :=10
2.模型读取及设置
read_dl_model (RetrainedModelFileName, DLModelHandle)
set_dl_model_param (DLModelHandle,'batch_size', BatchSize)if(not UseGPU)
set_dl_model_param (DLModelHandle,'runtime','cpu')
endif
set_dl_model_param (DLModelHandle,'runtime_init','immediately')
read_dict (DLDatasetFileName,[],[], DLDataset)
create_dict (GenParamEval)
set_dict_tuple (GenParamEval,'measures', SegmentationMeasures)
set_dict_tuple (GenParamEval,'show_progress','true')
3.模型评估及验证
evaluate_dl_model (DLDataset, DLModelHandle,'split','validation', GenParamEval, EvaluationResult, EvalParams)
create_dict (WindowHandleDict)
create_dict (GenParamEvalDisplay)
set_dict_tuple (GenParamEvalDisplay,'display_mode',['measures','absolute_confusion_matrix'])
dev_display_segmentation_evaluation (EvaluationResult, EvalParams, GenParamEvalDisplay, WindowHandleDict)
效果如图: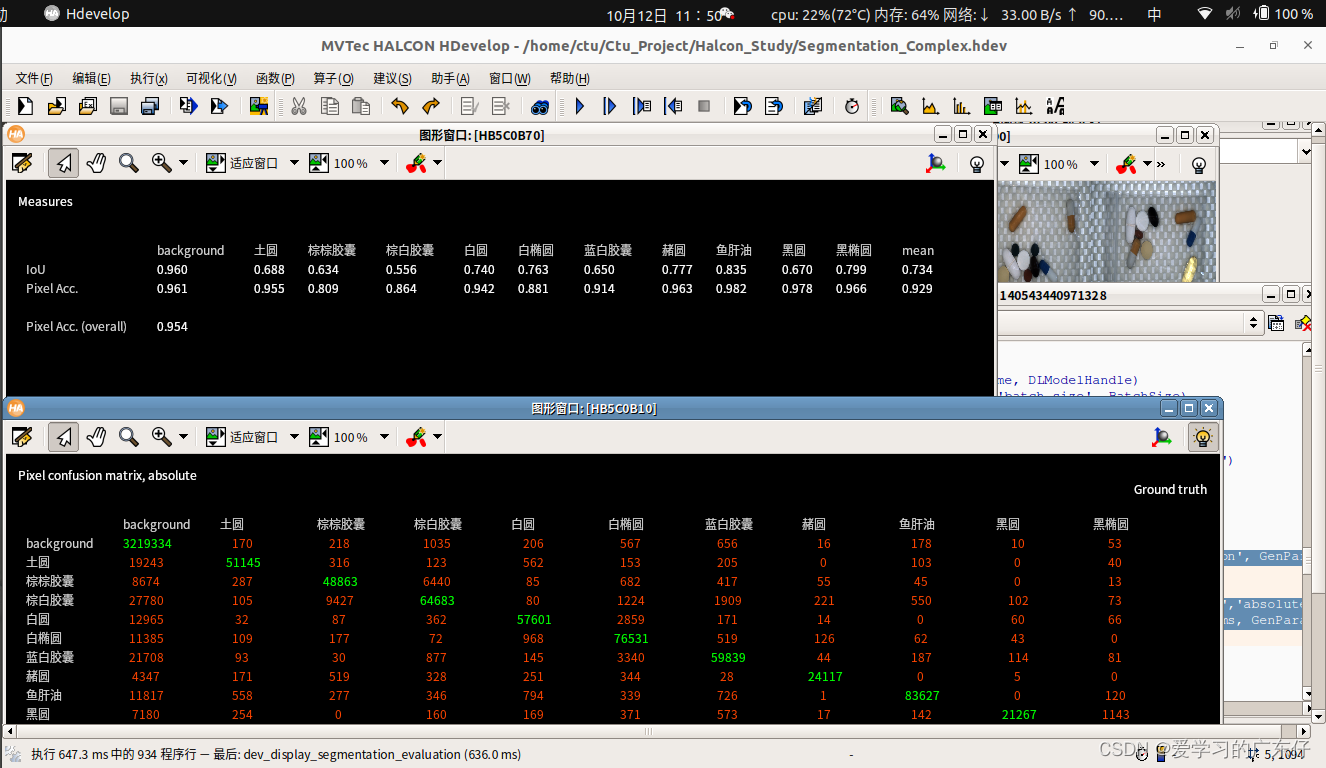
4.模型保存
此处模型保存使用了halcon自带的序列化方式
serialize_dl_model (DLModelHandle, SerializedItemHandle)
open_file (ModelFile,'output_binary', FileHandle)
fwrite_serialized_item (FileHandle, SerializedItemHandle)
close_file (FileHandle)
5.halcon脚本-模型预测
1.参数变量设置
testDir:='./DataSet/DataImage'
ModelFile:='./best_Seg.dat'
ClassTxt:='./DataSet/SegDataSet/classes.txt'
UseGpu:=true
ImageWidth :=512
ImageHeight :=512
ImageNumChannels :=3
2.模型参数设置
open_file (ModelFile,'input_binary', FileHandle)
fread_serialized_item (FileHandle, SerializedItemHandle)
close_file (FileHandle)
deserialize_dl_model (SerializedItemHandle, DLModelHandle)
set_dl_model_param (DLModelHandle,'batch_size', BatchSizeInference)
set_dl_model_param (DLModelHandle,'runtime','cpu')
set_dl_model_param (DLModelHandle,'runtime_init','immediately')
get_dl_model_param (DLModelHandle,'class_ids', ClassIDs)
3.模型预测
read_image (ImageBatch, ImageFiles[Index1])
gen_dl_samples_from_images (ImageBatch, DLSampleBatch)
preprocess_dl_samples (DLSampleBatch, DLPreprocessParam)
apply_dl_model (DLModelHandle, DLSampleBatch,['segmentation_image','segmentation_confidence'], DLResultBatch)
get_dict_object (SegmentationImage, DLResultBatch,'segmentation_image')
threshold (SegmentationImage, ClassRegions, ClassIDs, ClassIDs)
dev_display_dl_data (DLSampleBatch, DLResultBatch, DatasetInfo,'segmentation_image_result', GenParamDisplay, WindowHandleDict)
效果如图:
以往训练模型已删除,重新训练后上传效果图
总结
源码私聊
版权归原作者 爱学习的广东仔 所有, 如有侵权,请联系我们删除。