人工智能机器学习算法分类全解析
机器学习算法可以从多个角度进行分类,常见的分类方式包括基于学习方式、基于任务类型以及基于模型结构等。以下将分别从这几个方面展开详细介绍。
Cube Studio: 腾讯音乐开源的一站式云原生机器学习平台
Cube Studio作为腾讯音乐开源的一站式云原生机器学习平台,展现了强大的全流程AI开发能力。从数据处理、模型开发、训练到部署,Cube Studio为AI开发者提供了一个高效、灵活且功能丰富的开发环境。其云原生架构、丰富的功能模块以及对大模型的支持,使其成为当前AI开发领域的一个重要工具。随着
spark 3.4.4 机器学习基于逻辑回归算法及管道流实现鸢尾花分类预测案例
Pipeline将标签索引化、文本特征提取(词向量转换)以及逻辑回归模型训练这几个步骤有序地组合起来,实现了一个简单的文本分类任务流程,体现了Pipeline在整合机器学习流程方面的便利性和实用性。Spark 3.4.4
深入理解命名实体识别(NER)
命名实体识别(NER,Named Entity Recognition)是自然语言处理(NLP)中的一项重要技术,用于从文本中识别出特定类型的实体,并将这些实体分类到预定义的类别中。实体通常包括人名、地名、组织名、日期、时间、数量、货币等。例如,在句子“Barack Obama was born i
【AI知识点】置信区间(Confidence Interval)
置信区间(Confidence Interval, CI) 是统计学中用于估计总体参数的范围。它给出了一个区间,并且这个区间包含总体参数的概率等于某个指定的置信水平(通常是 90%、95% 或 99%)。与点估计不同,置信区间通过区间估计给出了参数的可能范围,从而提供了更可靠的信息。
【机器学习】机器学习与成像技术:开启智能视觉的新篇章
在科技日新月异的今天,机器学习与成像技术的融合正引领着一场前所未有的智能视觉革命。随着大数据的蓬勃发展和计算能力的显著提升,机器学习不再仅仅是学术界的研究热点,它正逐步渗透到我们生活的每一个角落,特别是在成像技术领域展现出了巨大的潜力和价值。
Ollama+Open WebUI+AUTOMATIC1111实现LLM+SD生成图片
本篇我们主要介绍如何在open webui中调用automatic1111的api来。
【SARL】单智能体强化学习(Single-Agent Reinforcement Learning)《纲要》
强化学习(Reinforcement Learning,简称 RL)是一种让机器“通过尝试和错误学习”的方法。它模拟了人类和动物通过经验积累来学会做决策的过程,目的是让机器或智能体能够在复杂的环境中选择最优的行为,从而获得最大的奖励。我们在这里介绍了单智能体强化学习的相关算法。
【海洋生态环境】十大数据集合集,速看!
MARIDA (Marine Debris Archive) 是第一个基于多光谱 Sentinel-2 (S2) 卫星数据的数据集,它将海洋碎片与共存的各种海洋特征区分开来,包括马尾藻大型藻类、船舶、天然有机材料、波浪、尾流、泡沫、不同的水类型(即清澈、浑浊的水、富含沉积物的水、浅水)和云。带注释的
机器学习ID3构造决策树
决策树是一种。
聚类分析算法——层次聚类 详解
层次聚类(Hierarchical Clustering)是一种无监督的机器学习方法,通过递归地对数据进行合并(或拆分),构建一个类似树的聚类结构,称为“树状图”(Dendrogram)。该算法通常用于探索数据的层次结构。根据聚类方向的不同,层次聚类可以分为“自底向上”(凝聚式聚类)和“自顶向下”(
【机器学习】决策树与随机森林:模型对比与应用案例分析
决策树是一种树状结构的模型,用于解决分类和回归问题。模型通过递归地将数据集分割成更小的子集,最终到达叶子节点,每个叶子节点表示一个预测结果。决策树的每个节点代表对某个特征的测试,每个分支代表测试结果,而每个叶子节点则表示最终的预测类别或值。随机森林是一种集成学习方法,通过构建多个决策树并结合它们的预
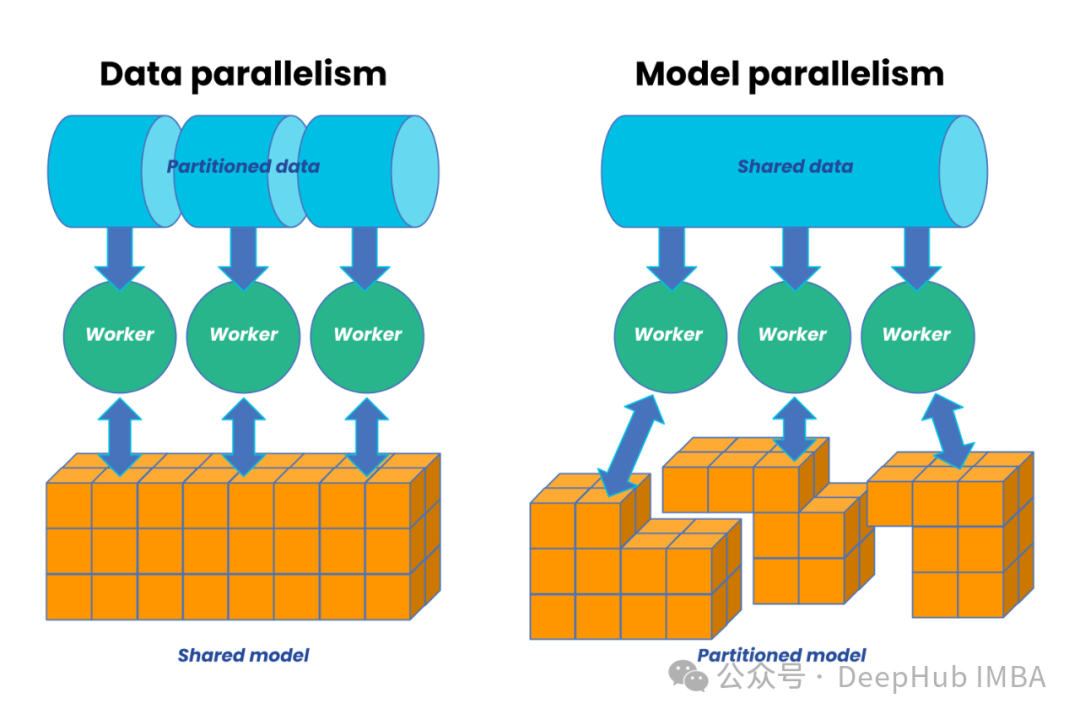
分布式机器学习系统:设计原理、优化策略与实践经验
分布式机器学习系统仍在快速发展。随着新型硬件的出现和算法的进步,我们预期会看到更多创新的优化技术。
机器学习之特征提取
自编码器就像是一个神奇的魔术师,它能将复杂的数据压缩成简洁的低维表示,同时还能从这个压缩后的表示中重构出原始数据。想象一下,把一堆杂乱无章的东西塞进一个小盒子里,然后还能再把它们完好无损地取出来,这就是自编码器的魅力所在。
【人工智能】Transformers之Pipeline(二十七):蒙版生成(mask-generation)
本文对transformers之pipeline的蒙版生成(mask-generation)从概述、技术原理、pipeline参数、pipeline实战、模型排名等方面进行介绍,读者可以基于pipeline使用文中的2行代码极简的使用多模态中的蒙版生成(mask-generation)模型。
【pyspark学习从入门到精通20】机器学习库_3
在这一部分,我们将使用前一章中的数据集的一部分来介绍 PySpark ML 的概念。在这一部分,我们将再次尝试预测婴儿的生存几率。
可解释人工智能(XAI)领域的全面概述
本文提供一份关于 XAI 的全面综述,涵盖常见的术语和定义、XAI 的需求、XAI 的受益者、XAI 方法分类以及 XAI 方法在不同应用领域的应用。
AI前景分析展望——GPTo1 SoraAI
人工智能(AI)领域的飞速发展已不仅仅局限于学术研究,它已渗透到各个行业,影响着从生产制造到创意产业的方方面面。在这场技术革新的浪潮中,一些领先的AI模型,像Sora和OpenAI的O1,凭借其强大的处理能力和创新的技术架构,成为了当前最为关注的焦点。本文将对这两款模型进行深入剖析,探讨它们在技术架
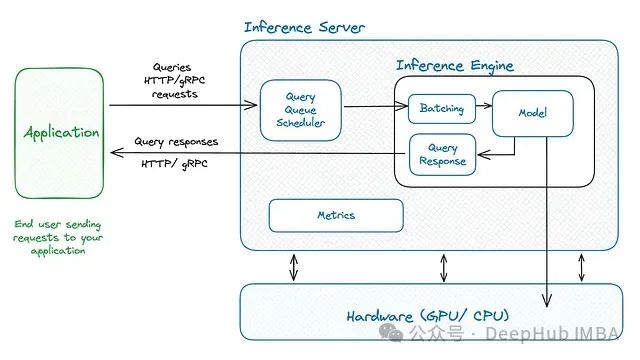
从本地部署到企业级服务:十种主流LLM推理框架的技术介绍与对比
本文将深入探讨十种主流LLM服务引擎和工具,系统分析它们在不同应用场景下的技术特点和优势。
手搓人工智能-最优化算法(1)最速梯度下降法,及推导过程
对于复杂函数来说,直接求解矢量方程得到优化函数的极值点往往非常困难。在这种情况下,可以考虑采用迭代的方法从某个初始值开始,逐渐逼近极值点,即——梯度法



