大数据-210 数据挖掘 机器学习理论 - 逻辑回归 scikit-learn 实现 penalty solver
但随着C的逐渐变大,正则化的强度越来越小,模型在训练集和测试集上表现呈现了上升趋势,直到C=0.8左右,训练集上的表现依然走高,但模型在未知数据集上的表现就开始下跌,这时候就是出现了过拟合。正则化参数,LogisticRegression默认带了正则化项,penalty参数可选择的值有1和2,分别对
大数据-212 数据挖掘 机器学习理论 - 无监督学习算法 KMeans 基本原理 簇内误差平方和
大家可以发现,我们的 Intertia 是基于欧几里得距离的计算公式得来的。第六次迭代之后,基本上质心的位置就不会再改变了,生成的簇也变得稳定,此时我们的聚类就完成了,我们可以明显看出,K-Means 按照数据的分布,将数据聚集成了我们规定的 4 类,接下来我们就可以按照我们的业务求或者算法需求,对
大模型-基于大模型的数据标注
法来自于这篇论文:Can Generalist Foundation Models Outcompete Special-Purpose Tuning?
Ubuntu 20.04版本快速安装 Miniconda(宝宝级攻略)
我在学习深度学习时,安装Miniconda时踩过了一些坑,浪费了很多的时间,现在想出一个宝宝级的攻略,希望能够帮助大家节约时间,规避一些毒教程的糟粕。不管是双系统还是虚拟机这个攻略都是完美适配的,请大家放心使用。
【机器学习】标签编码(Label Encoding)、独热编码(One-Hot Encoding)
字符特征转数值特征的两种编码方式
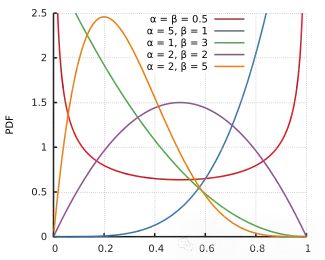
贝叶斯统计中常见先验分布选择方法总结
本文详细介绍了贝叶斯统计中三种常见的先验分布选择方法:经验贝叶斯方法、信息先验和无信息/弱信息先验。
大数据-206 数据挖掘 机器学习理论 - 多元线性回归 回归算法实现 算法评估指标
这里需要注意的是,当使用矩阵分解来求解多元线性回归方程时,必须添加一列全为 1 的列,用于表征线性方程截距W0。其中 m 为数据集样例个数,以及 RMSE 误差的均方根,为 MSE 开平方后所得结果。在回归分析中,SSR 表示聚类中类似的组间平方和概念,译为:Sum of squares of th
人工智能之机器学习
在1956年众多科学家相聚一起共同探讨并展望未来的科技.首次提出"人工智能"这个专业名词,这一年也被称为人工智能元年......
【AI论文精读5】知识图谱与LLM结合的路线图-P2
该论文提出了一个将大型语言模型(LLMs)与知识图谱(KGs)相结合的路线图。这是我对论文第2部分的解读。
【动物识别系统】Python+卷积神经网络算法+人工智能+深度学习+机器学习+计算机课设项目+Django网页界面
动物识别系统。本项目以Python作为主要编程语言,并基于TensorFlow搭建ResNet50卷积神经网络算法模型,通过收集4种常见的动物图像数据集(猫、狗、鸡、马)然后进行模型训练,得到一个识别精度较高的模型文件,然后保存为本地格式的H5格式文件。再基于Django开发Web网页端操作界面,实
CLIP中的logit_scale参数
这行代码定义并初始化了一个可训练的参数,用于在计算图像和文本特征的相似度时进行缩放。通过这种方式,模型可以在训练过程中调整相似度的动态范围,以便更好地学习图像和文本特征之间的匹配关系。
大数据-204 数据挖掘 机器学习理论 - 混淆矩阵 sklearn 决策树算法评价
也就是说,单纯的追求捕捉少数类,就会成本太高,而不顾及少数类,又会无法达成模型的效果。比如银行在判断一个申请信用卡的客户是否会违约行为的时候,如果一个客户被判断为会违约,这个客户的信用卡申请就会驳回,如果为了捕捉会违约的人,大量地将不会违约的客户判断为会违约的客户,就会有许多无辜的客户的申请被驳回。
数据预处理:为 AI 准备 “优质食材” 的重要步骤
AI模型数据处理
大数据-201 数据挖掘 机器学习理论 - 决策树 局部最优 剪枝 分裂 二叉分裂
而训练集、测试集和验证集的划分通常遵照 6:2:2 的比例进行划分,当然也可以根据实际需求适当调整划分比例,但无论如何,测试集和验证集数据量都不宜过多也不宜过少,该二者数据集数据均不参与建模,若占比太多,则会对模型的构建过程造成较大的影响(欠拟合),而若划分数据过少,训练集数据量较大,则又可能造成过
LocalAI离线安装部署
LocalAI是免费的开源 OpenAI 替代品。LocalAI 可作为替代 REST API,与 OpenAI(Elevenlabs、Anthropic……)API 规范兼容,用于本地 AI 推理。它允许您在本地或使用消费级硬件运行 LLM、生成图像、音频(不止于此),支持多种模型系列。不需要 G
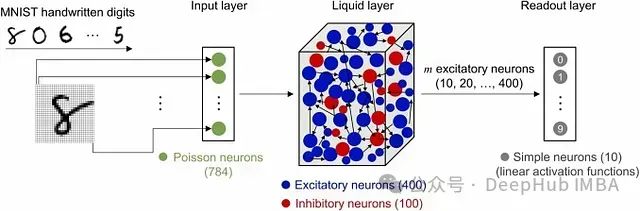
基于Liquid State Machine的时间序列预测:利用储备池计算实现高效建模
**Liquid State Machine (LSM)** 是一种 **脉冲神经网络 (Spiking Neural Network, SNN)** ,在计算神经科学和机器学习领域中得到广泛应用,特别适用于处理 **时变或动态数据**。
大数据-203 数据挖掘 机器学习理论 - 决策树 sklearn 剪枝参数 样本不均匀问题
剪枝参数一定能够提升模型在测试集上的表现吗?调参是没有绝对的答案的,一切都需要看数据的本身。无论如何,剪枝参数的默认值会让树无尽的生长,这些树在某些数据集上可能非常巨大,对内存的消耗也非常巨大。属性是模型训练之后,能够调用查看的模型的各种性质,对决策树来说,最重要的是 feature_importa
大数据-195 数据挖掘 机器学习理论 - 监督学习算法 KNN 近邻 代码实现 Python
当然只对比一个样本是不够的,误差会很大,他们就需要找到离其最近的 K 个样本,并将这些样本称为【近邻】nearest neighbor,对这 K 个近邻,查看它们都属于任何类别(这些类别称为称为【标签】labels)。我们常说的欧拉公式,即“欧氏距离”,回忆一下,一个平面直角坐标系上,如何计算两点之
LLM Continue Pretrain(2024版)
deepseek的开源moe,也做得非常不错,应该是国内开源top了,他们的pretrain团队做得挺棒的 但算法为主的,做pretrain,往往就是洗数据了。尴尬的点是,预训练洗数据,因为数据量大,往往都是搞各种小模型+规则,很难说明你做的事情的技术含量,只能体现你对数据的认知很好。语言类的dom
大数据-202 数据挖掘 机器学习理论 - 决策树 sklearn 绘制决策树 防止过拟合
在每次分支的时候,不使用全部特征,而是随机选取一部分特征,从中选取不纯度相关指标最优的作为分支用的节点。我们之前提过,无论决策树模型如何进化,在分支上的本质都还是追求某个不纯度相关的指标的优化,而正如我们提到的,不纯度是基于节点计算出来的,也就是说,决策树在建树时,是靠优化节点来追求一棵优化的树,但



