
文章目录
1. ImageNet 说明
ImageNet官网:http://image-net.org/
ImageNet 由斯坦福李飞飞教授带领创建,ImageNet 本身有2万多个的类别,超过 1400 万张图片,其中超过 100 万张图片有明确类别标注和物体位置标注。
ImageNet 按照 WordNet 层级结构组织数据,首先介绍一下 WordNet。在 WordNet 中每一个概念(concept)都会由很多个词(word)或者短语(word phrase)来描述,就好比说 “动物 animal” 作为一个 concept,可以包含 “domestic animal 家畜”、“work animal 役畜” 等 work phrase,而 “domestic animal 家畜” 又可以继续细分为 “domestic dog”、“dog” 等。因此将每一个 concept 记作一个 “synonym set 或 synset”(同义词集合)。WordNet 中包含超过 100,000 个 synset,其中 80,000+ 是名词。WordNet 以 Synset 为基本单位来组织单词,可以认为 WordNet 是一个树状结构,从其根结点到叶子结点是一个不断细分的过程,并且每个结点都是一个 Synset。
ImageNet 包含 82,115 个 Synset(均为 WordNet 中的名词),平均在每个 Synset 上都设置了 1,000 张图像。
适用任务:图像分类,目标检测,目标定位、视频目标检测、场景分类
特别解释:ILSVRC (ImageNet Large-Scale Visual Recognition Challenge) 是一个基于 ImageNet 的比赛,每年都会从ImageNet中抽取部分数据作为比赛数据集。ILSVRC 从 2010 年开始举行,每年一次,到 2017 年最后一届结束,因此 “ILSVRC+年份” 也用来特指某一年比赛的数据集(属于ImageNet的子集),基于 ILSVRC 比赛的子数据集也是各种论文中最常用的数据集。
2. ILSVRC2012 说明
很多论文都常用 ILSVRC2012 作为实验数据集,ILSVRC2012 包含1000个类别(ImageNet 的 1000 个 Synset),每个类别大约有1000张图片。其中测试集未公开标注信息,因此常用验证集来进行模型的测试。
ILSVRC2012 的类别编号和类别名称参考:类别名称对应表
ILSVRC2012类别数 (Number of classes)图片数 (Number of images)文件大小 (Size on disk)标注训练集1000类约120万张图片140GB公开验证集1000类5万张图片6GB公开测试集1000类10万张图片~13GB未公开
在官网下载ILSVRC2012时,可以看到训练数据集(Training images)被分为了 (Task1 & 2) 和 (Task 3),其中 (Task 1 & 2) 是用于图像识别任务的。
验证集(Validation images)对应的标注信息在
Development kit (Task 1 & 2)
中,下载压缩包后解压,找到
ILSVRC2012_devkit_t12/data
文件夹,里面的
ILSVRC2012_validation_ground_truth.txt
就是验证集对应的标注label。
3. ImageNet下载方式
ImageNet不可用于商业目的,因此需要认证edu邮箱,直接用学校邮箱认证的话请求会立马通过,如果用其他后缀的普通邮箱需要审核1~5天还不一定能审核通过。用学校邮箱认证之后会收到邮件,从邮件内提供的链接就可以进入数据的
Download
页面,ILSVRC下面按照年份分类,一般最常用的就是ILSVRC 2012,可以根据自己的需要选择年份。进入之后在
Images
条目下就是Train/Val/Test数据。
step1:进入Download页面 - 按需选择ILSVRC年份: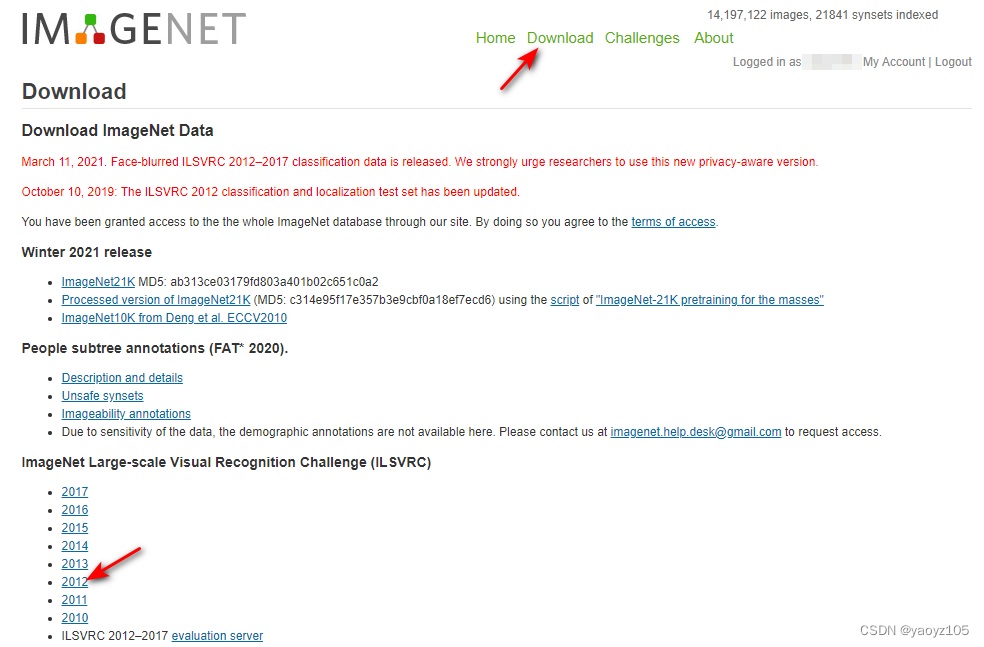
step2:在
Images
部分就是训练/验证/测试数据集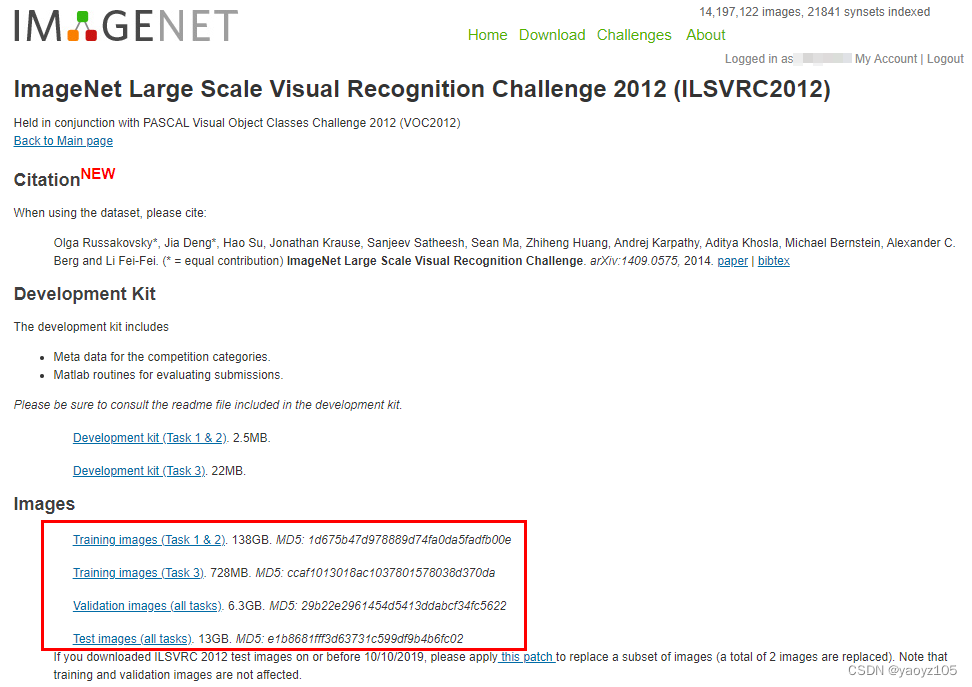
关于下载方式,如果不方便从官网下载,可以选择以下备用方案:
- 方式1:https://hyper.ai/datasets/4889
- 方式2:迅雷种子下载,提取码 x7jn
- 方式3:ImageNet LSVRC 2012 Training Set (Object Detection)
4. ImageNet数据组织与使用
仍以 ILSVRC 2012 为例,在这里能够下载到关于 ILSVRC 2012 的所有数据文件。其中,带有 bbox 标识的用于目标检测任务,包括以下 4 个文件: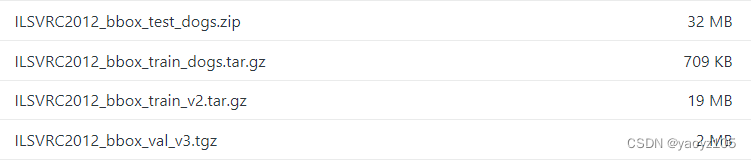
用于图像分类任务的包含以下 4 个文件:其中 train 分为了
train
和
train_t3
,分别对应着
task 1&2
和
task 3
。
devkit 工具包包含以下 2 个文件:
训练集
ILSVRC2012_img_train
下包含两级目录,第一级目录包含 1000 个子文件夹,对应 1000 个类别。每个二级目录包含 1300 张图片,表示每个类别提供了 1300 个样本。每个子文件夹的名称为
n******
,其下对应的图片名称也以文件夹名称为前缀,其后为图片序号。
验证集
ILSVRC2012_img_val
下包含 50K 张图片,可以看到验证集图片名称前缀没有类别信息。要获取验证集标签信息,需要从
ILSVRC2012_devkit_t12/data
中的
ILSVRC2012_validation_ground_truth.txt
得到。
1. 解压 train 和 val 数据,由于 test 数据未提供标签,因此这里不使用。
# 解压trian数据tar -xvf ILSVRC2012_img_train.tar
# 解压val数据mkdir ILSVRC2012_img_val
tar -xvf ILSVRC2012_img_val.tar -C ILSVRC2012_img_val
# 解压devkittar -xzvf ILSVRC2012_devkit_t12.tar.gz
2. 重新组织 val 数据,按照 train 数据的组织方式,对 val 数据进行处理,方便后续训练验证时对数据的加载。
defimagenet_val_process(images_dir, devkit_dir):"""
move val images to correspongding class folders.
"""# load synset, val ground truth and val images list
synset = scipy.io.loadmat(os.path.join(devkit_dir,'data','meta.mat'))
ground_truth =open(os.path.join(devkit_dir,'data','ILSVRC2012_validation_ground_truth.txt'))
lines = ground_truth.readlines()
labels =[int(line[:-1])for line in lines]
root, _, filenames =next(os.walk(images_dir))for filename in filenames:# val image name -> ILSVRC ID -> WIND
val_id =int(filename.split('.')[0].split('_')[-1])
ILSVRC_ID = labels[val_id -1]
WIND = synset['synsets'][ILSVRC_ID -1][0][1][0]print("val_id:%d, ILSVRC_ID:%d, WIND:%s"%(val_id, ILSVRC_ID, WIND))# move val images
output_dir = os.path.join(root, WIND)if os.path.isdir(output_dir):passelse:
os.mkdir(output_dir)
shutil.move(os.path.join(root, filename), os.path.join(output_dir, filename))if __name__ =='__main__':
img_dir ="/data/imagenet/ILSVRC2012_img_val"
dev_dir ="/data/imagenet/ILSVRC2012_devkit_t12"
imagenet_val_process(img_dir, dev_dir)
重新组织后的 val 数据与 train 数据的组织方式相同,按照二级目录的方式,包含 1000 个子文件夹(类别),每个子文件夹下包含 50 张用于验证的图片。
3. ImageNet 数据读取(PyTorch)
一种比较简单的读取方式是,使用 PyTorch 中自带的库
ImageFolder
。ImageFolder 适合读取数据组织结构如下的数据集:
--| root
----| class1
------| img1.png
------| img2.png
------|...
----| class2
------|...
----| class3
------|...
即数据按照两级目录组织,第一级目录是类别,第二级是每个类别对应的所有样本。
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
data_transform = transforms.Compose([
transforms.Resize(299),
transforms.CenterCrop(299),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485,0.456,0.406], std=[0.229,0.224,0.225])])# 使用ImageFolder读取
train_dataset = ImageFolder(root='/data/imagenet/ILSVRC2012_img_train',transform=data_transform)
train_dataset_loader = DataLoader(train_dataset, batch_size=4, shuffle=False, num_workers=4)print(train_dataset.imgs == train_dataset.samples)# Truefor i,(images, labels)inenumerate(train_dataset_loader):print(images.size())print(labels.size())
通过
ImageFolder
读取的结果,可以看到包含以下内容: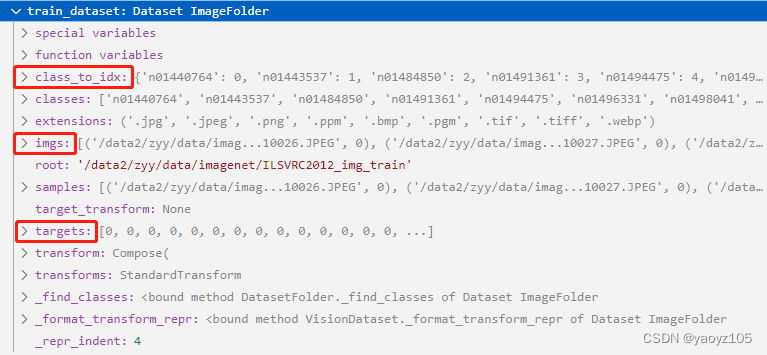
其中:
class:List,包含 1000 个类别名称class_to_idx:Dict,每个类别名称字符串与其对应的类别序号imgs和samples:List,每个 List 元素为 Tuple,为每张图片的路径和其对应的类别序号targets:List,每张图片对应的类别序号
施工中…
版权归原作者 不吃饭就会放大招 所有, 如有侵权,请联系我们删除。