
通过这篇博客,你将清晰的明白什么是分类的正则化。这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下《 白话机器学习中的数学——分类的正则化》
文章目录
一、分类的正则化
在上一篇问文章中我们介绍了正则化,正则化是减少过拟合的有效手段。之前讨论的是回归的情况,对于分类也可以应用正则化,大家还记得逻辑回归的目标函数吗?也就是对数似然函数: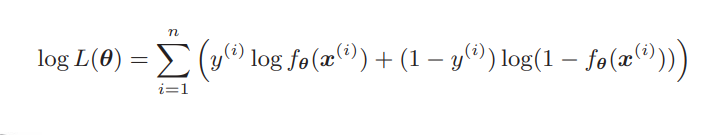
分类也是在这个目标函数中增加正则化项就行了,道理是相同的。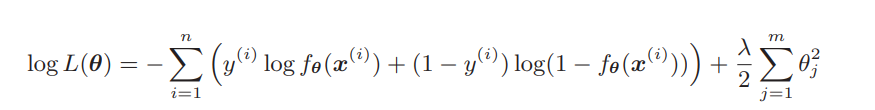
注意一下前面添加了负号,那么对数似然函数本来以最大化为目标。但是,这次我想让它变成和回归的目标函数一样的最小化问题,所以加了负号。这样就可以像处理回归一样处理它,所以只要加上正则化项就可以了。也就是说:反转符号是为了将最大化问题替换为最小化问题!
反转了符号之后,在更新参数时就要像回归一样,与微分的函数的符号反方向移动才行。目标函数的形式变了,参数更新的表达式也会变!不过,只要再把正则化项的部分也微分了就行。
二、包含正则化项的表达式的微分
在上面的的学习中,我们把回归的目标函数分成了 C(θ) 和 R(θ)。这是新的目标函数的形式,我们要对它进行微分。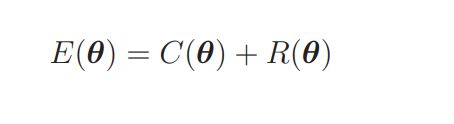
因为是加法,所以对各部分进行偏微分: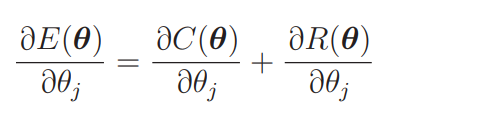
C(θ) 是原来的目标函数,讲解回归的时候我们已经求过它的微分形式了。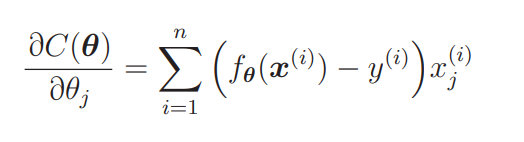
求过就不用再求了,所以接下来只要对正则化项进行微分就行了。正则化项只是参数平方的和,所以它的微分也很好求。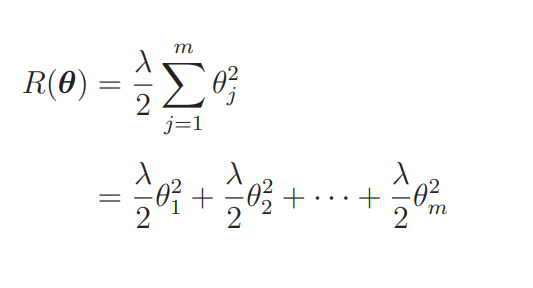
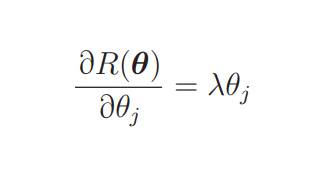
可以看出,在微分时表达式中的 1/2 被抵消,微分后的表达式变简单了。那么最终的微分结果就是这样的: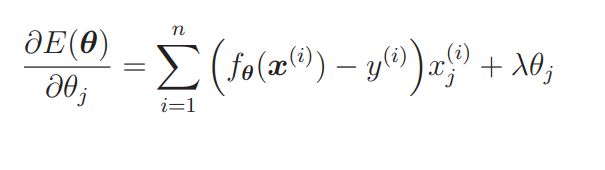
剩下要做的就是把这个微分结果代入到参数更新表达式里去。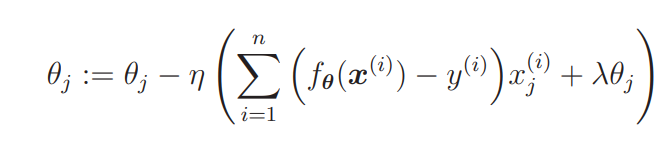
上面就是这加入了正则化项的参数更新表达式,不过,我们之前说过一般不对 θ0 应用正则化。R(θ) 对 θ0 微分的结果为 0,所以 j = 0 时表达式 中的 λθj 就消失了。因此,实际上我们需要像这样区分两种情况。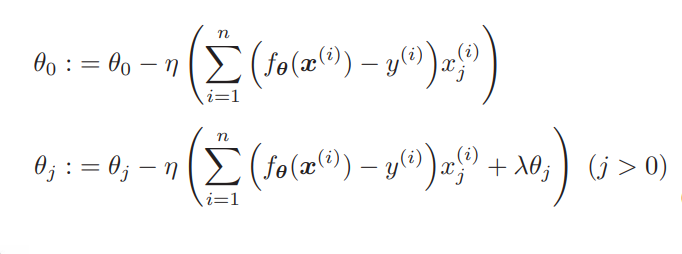
逻辑回归的流程也是一样的。原来的目标函数是 C(θ),正则化项是 R(θ),现在对 E(θ) 进行微分。
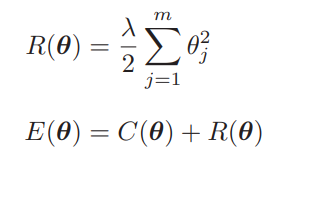
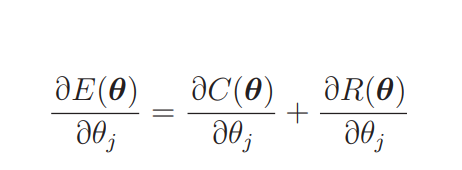
在上面的表达式中我们已经求过逻辑回归原来的目标函数 C(θ) 的微分,不过现在考虑的是最小化问题,所以要注意在前面加上负号。也就是要进行符号的反转。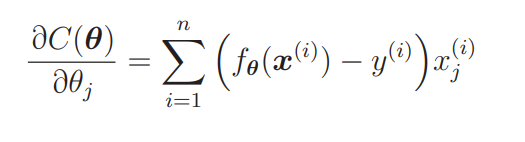
另外,刚才我们已经求过正则化项 R(θ) 的微分了,可以直接使用。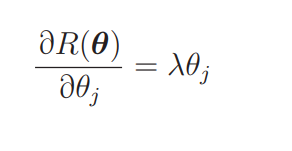
也就是说这次不需要任何新的计算。那么,参数更新表达式应该是这样的——这次我把 θ0 的情况区分出来了。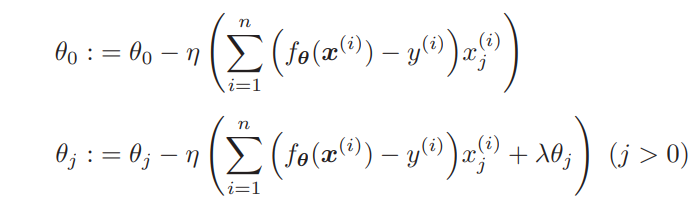
刚才我们介绍的方法其实叫L2正则化。除 L2 正则化方法之外,还有 L1正则化方法。它的正则化项 R 是这样的。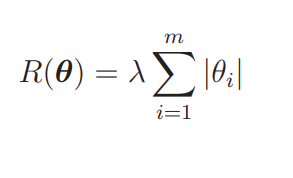
L1 正则化的特征是被判定为不需要的参数会变为 0,从而减少变量个数。而 L2 正则化不会把参数变为 0。刚才我说过二次式变为一次式的例子吧,用 L1 正则化就真的可以实现了。L2 正则化会抑制参数,使变量的影响不会过大,而 L1 会直接去除不要的变量。使用哪个正则化取决于要解决什么问题,不能一概而论。现在只要记住有这样的方法就行,将来一定会有用的。
版权归原作者 爱睡觉的咋 所有, 如有侵权,请联系我们删除。