成本降低90%,OpenAI正式开放ChαtGΡΤ
今天凌晨,OpenAI官方发布ChatGPT和Whisper的API,开发人员现在可以通过API使用最新的文本生成和语音转文本功能。
《ChatGPT是怎样炼成的》
ChatGPT的训练过程(后来呢,你有在晃神的瞬间想起我吗?)。
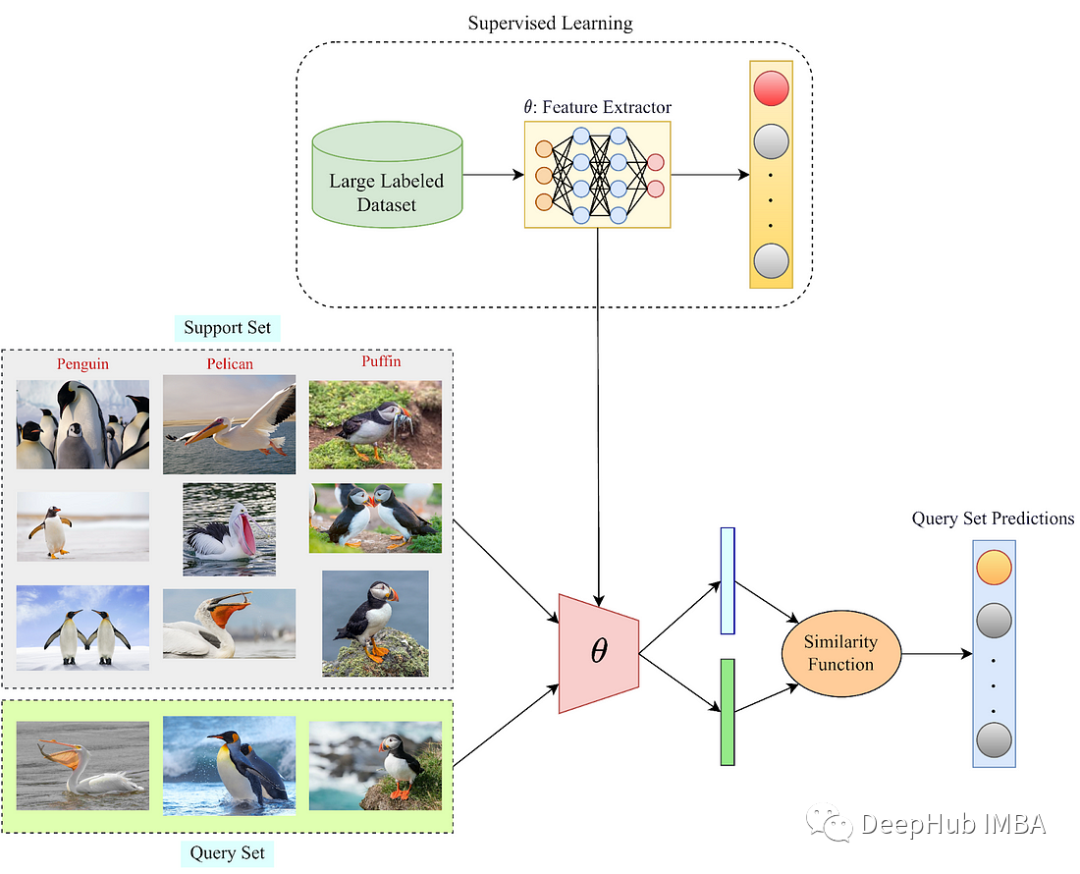
少样本学习综述:技术、算法和模型
少样本学习(FSL)是机器学习的一个子领域,它解决了只用少量标记示例学习新任务的问题。
什么是图神经网络?
GNN 将深度学习的预测能力应用于丰富的数据结构,这些数据结构将对象及其关系描述为图中由线连接的点。

Python中函数参数传递方法*args, **kwargs,还有其他
本文将讨论Python的函数参数。我们将了解*args和**kwargs,/和*的都是什么,

Python图像处理:频域滤波降噪和图像增强
快速傅里叶变换(FFT)是一种将图像从空间域变换到频率域的数学技术,是图像处理中进行频率变换的关键工具,本文将讨论图像从FFT到逆FFT的频率变换所涉及的各个阶段,并结合FFT位移和逆FFT位移的使用。
史上最全学习率调整策略lr_scheduler
学习率是深度学习训练中至关重要的参数,很多时候一个合适的学习率才能发挥出模型的较大潜力。所以学习率调整策略同样至关重要,这篇博客介绍一下Pytorch中常见的学习率调整方法。
机器学习:基于神经网络对用户评论情感分析预测
神经网络模型的思想来源于模仿人类大脑思考的方式。神经元是神经系统最基本的结构和功能单位,分为突起和细胞体两部分。突起作用是接受冲动并传递给细胞体,细胞体整合输入的信息并传出。人类大脑在思考时,神经元会接受外部的刺激,当传入的冲动使神经元的电位超过阈值时,神经元就会从抑制转向兴奋,并将信号向下一个神经
什么是推荐系统?推荐系统类型、用例和应用
当前基于 DL 的推荐系统模型:DLRM、Wide and Deep (W&D)、神经协作过滤 (NCF)、b变分自动编码器 (VAE) 和 BERT(适用于 NLP)构成了 NVIDIA GPU 加速 DL 模型产品组合的一部分,并涵盖推荐系统以外的许多不同领域的各种网络架构和应用程序,包括图像、
机器学习中的数学原理——模型评估与交叉验证
机器学习中的模型评估与交叉验证!这个专栏名为白话机器学习中数学学习笔记,主要是用来分享一下我在 机器学习中的学习笔记及一些感悟,也希望对你的学习有帮助哦!感兴趣的小伙伴欢迎私信或者评论区留言!这一篇就更新一下白话机器学习中的数学——模型评估与交叉验证》!
结合基于规则和机器学习的方法构建强大的混合系统
在本文中,将介绍如何将手动规则和ML结合使得我们的方案变得更好。
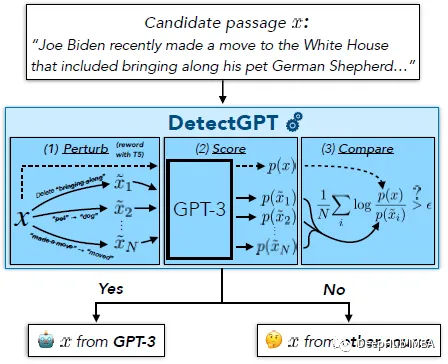
DetectGPT:使用概率曲率的零样本机器生成文本检测
DetectGPT的目的是确定一段文本是否由特定的llm生成,例如GPT-3。
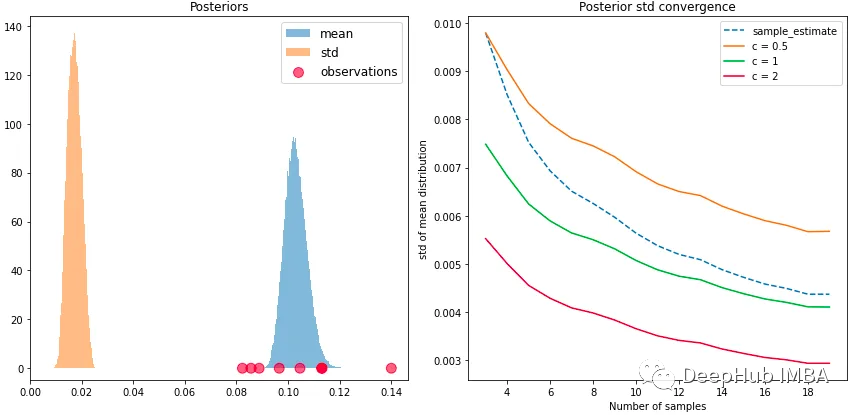
带加权的贝叶斯自举法 Weighted Bayesian Bootstrap
在去年的文章中我们介绍过Bayesian Bootstrap,今天我们来说说Weighted Bayesian Bootstrap
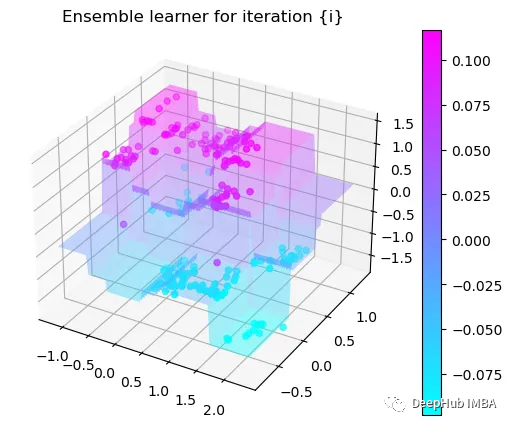
梯度提升算法决策过程的逐步可视化
梯度提升算法是最常用的集成机器学习技术之一,在这篇文章中,我们将从头开始构建一个梯度增强模型并将其可视化。
Attention-LSTM模型的python实现
1.模型结构Attention-LSTM模型分为输入层、LSTM 层、Attention层、全连接层、输出层五层。LSTM 层的作用是实现高层次特征学习;Attention 层的作用是突出关键信息;全连接层的作用是进行局部特征整合,实现最终的预测。 这里解决的问题是:使用Attention-L
XGBoost-XGBoost 中验证相关参数梳理和解释
evals (Optional[Sequence[Tuple[DMatrix, str]]]) - 在训练时用于指标进行评估的验证集列表。用于验证数据的评估指标,根据不同的目标函数,会分配默认评估指标(回归使用 rmse,分类使用 logloss,排序使用 mean average precisio
腾讯自研万亿级NLP大模型,自动生成和衍生广告文案
低成本可落地,混元AI大模型技术再现突破
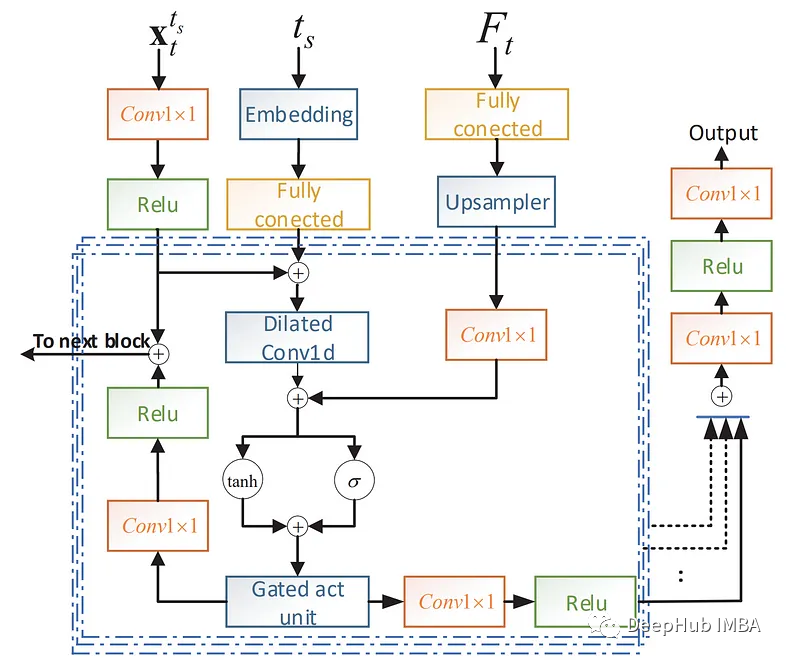
论文推荐:ScoreGrad,基于能量模型的时间序列预测
能量模型(Energy-based model)是一种以自监督方式执行的生成式模型,近年来受到了很多关注。本文将介绍ScoreGrad:基于连续能量生成模型的多变量概率时间序列预测。如果你对时间序列预测感兴趣,推荐继续阅读本文。

XGBoost和LightGBM时间序列预测对比
XGBoost和LightGBM都是目前非常流行的基于决策树的机器学习模型,它们都有着高效的性能表现,但是在某些情况下,它们也有着不同的特点。
GPT的发展历程
GPT,又称自然语言处理(Natural Language Processing, NLP),是一种机器学习模型。它可以模拟人类语言的模式,并将其转换为计算机可读形式,从而可以用来自然地与人交谈、阅读、写作和翻译。自然语言处理旨在理解人类语言的语义,并将其转换为机器可以理解的形式。GPT是一种新型人



