
2672篇主要论文,63场研讨会,7场受邀演讲,包括语言模型、脑启发研究、扩散模型、图神经网络……NeurIPS包含了世界级的AI研究见解,本文将对NeurIPS 2022做一个全面的总结。

第36届Neural Information Processing Systems Conference(NeurIPS)已经收官一个月了,我们这里整理了他的2672篇论文,163篇Datasets & Benchmark跟踪论文,以及63个研讨会的700多篇研讨会论文,希望这对你有帮助。
我们将内容分为10个关键主题领域,以及它们所包含的内容的简要描述,并选择了5篇我们推荐的论文,这对了解整个行业的发展都有所帮助。
1. Language Models and Prompting
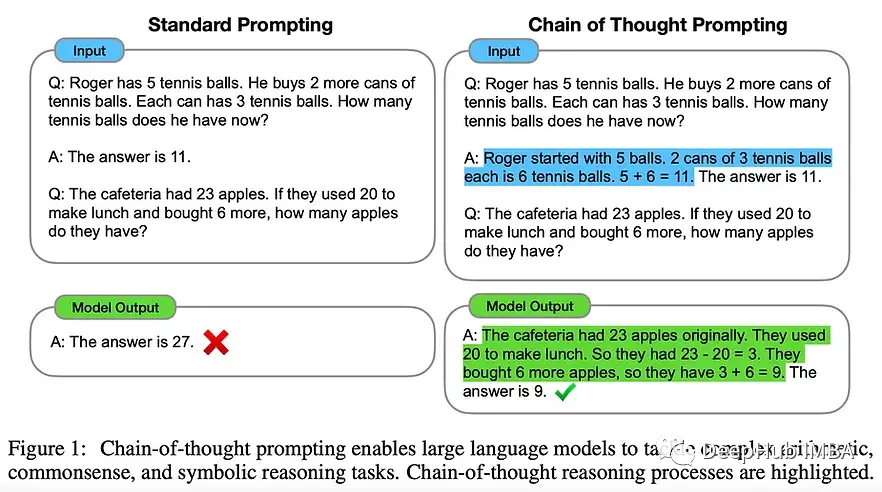
语言模型是人工智能中最受欢迎的研究领域——尤其是自2020年引入GPT-3以来——该领域在会议上得到了大量关注。有来自谷歌、DeepMind、OpenAI、Meta、Stanford等大型计算公司的许多重磅论文。
有很多关于“simple prompting”技术的工作,比如思维链技术(或技巧?),这些技术可以从简单的预训练自回归lm中挤出更多的性能。多模态今年也受到了关注,DeepMind的Flamingo(视觉+语言)是其中最受欢迎的,谷歌的Minerva展示了在使用正确的数据进行预训练时,LMs在数学方面可以有多好,而InstructGPT展示了如何使用人类反馈和强化学习来微调大型LMs。
1、 Chain of Thought Prompting Elicits Reasoning in Large Language Models
💡简单地提示lm输出推理步骤,而不是直接的答案,极大地提高了性能。其后续作品包括STaR等。
2、 Flamingo: a Visual Language Model for Few-Shot Learning
💡DeepMind介绍了一个“简单的”单一模型,经过视觉+语言的预训练,可在各种多模态任务的最先进水平
3、 Solving Quantitative Reasoning Problems with Language Models (Minerva)
💡在数学数据上训练的大型LM可以在定量推理任务上实现强大的性能,包括在MATH数据集上的最先进的性能。
4、 Data Distributional Properties Drive Emergent In-Context Learning in Transformers
💡大规模的预训练在哪些方面推动语境学习?训练数据的分布需要突发性和大量的罕见情况。
5、Training language models to follow instructions with human feedback (InstructGPT)
💡OpenAI使用强化学习从人类在循环(RLHF)微调GPT-3使用从人类标签收集的数据。由此产生的模型称为InstructGPT,在一系列NLP任务上优于GPT-3。
2. Diffusion Models
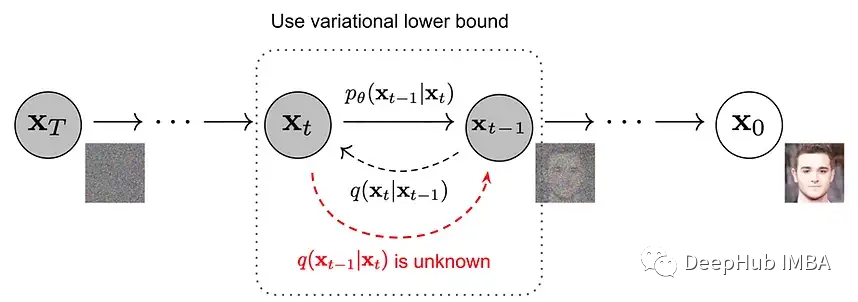
如果有什么东西值得在2022年获得最酷的称号,那一定是文本到图像生成模型,其中大多数由扩散模型驱动:OpenAI的DALL·e2,谷歌的Imagen,或Stable diffusion。
它们流行还不到2年!-建模技术现在已经超越了2D静态图像生成的领域,并被应用于3D场景合成,视频生成,和分子对接等。正如我们在2017年的Transformers 中所看到的,一个研究想法成为主流所需的时间正在缩短。
1、 Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding (Imagen)
💡Imagen,一个使用扩散模型的文本到图像合成的简单方法。
2、 Object Scene Representation Transformer (OSRT)
💡一个高效的3d模型建模
3、 Denoising Diffusion Restoration Models (DDRM)
💡使用预训练的去噪扩散概率模型(ddpm)进行超分辨率、去模糊、修补和着色,无需特定问题的监督训练。
4、 Flexible Diffusion Modeling of Long Videos
💡应用到视频域的ddpm。捕获帧之间的长期依赖关系,他们提出了一种架构,可以灵活地限制视频帧的任何子集。
5、EGSDE: Unpaired Image-to-Image Translation via Energy-Guided Stochastic Differential Equations
💡能量引导随机微分方程(EGSDE),使用在源和目标域上预训练的能量函数来指导预训练的SDE的推理过程,以实现真实和的图像到图像(I2I)。
3. Self-Supervised Learning
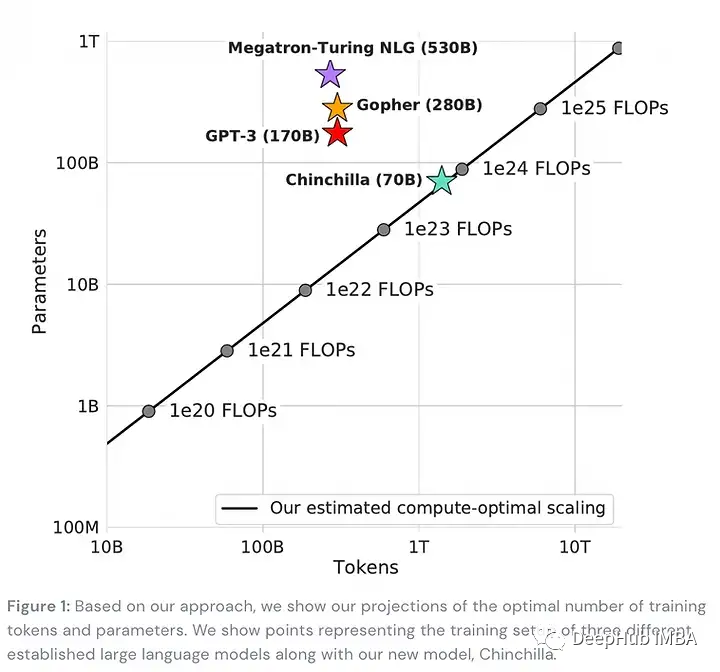
自监督学习(SSL)已经成为现代ML的一个重要组成部分,它现在已经以这样或那样的方式融入到大多数研究中。在深度学习中,NLP在2018年首次以BERT引领潮流,计算机视觉后来以SimCLR等成功的技术加入了SSL。
2022年SSL中最亮眼的应该是DeepMind的Chinchilla:一项关于语言模型的预训练预算应该花多少在模型参数上,以及在更大的训练语料库上花多少钱的研究(发现大多数大型LM都太大或训练不足),最后得到了一个模型Chinchilla,包含了70B参数的LM,并且通过更长训练时间而优于其较它的对手。
最后,我们也不能错过用于信息检索的全新(部分)SSL技术,例如可微分搜索索引。
虽然SSL现在是如此普遍,但它经常被降级为一个不太引人注意的注释。所有这些研究都证明,在这一领域还有许多有待发现的新见解。
1、 An empirical analysis of compute-optimal large language model training (Chinchilla)
💡最好在更多的令牌上训练一个更小的语言模型。DeepMind用他们的70B参数的Chinchilla模型展示了这一点,其性能优于更大的模型,如Gopher (280B)、GPT-3 (175B)或Megatron-Turing NLG (530B)。
2、 VideoMAE: Masked Autoencoders are Data-Efficient Learners for Self-Supervised Video Pre-Training
💡在视频上做了精致的预训练视频表示。它包含了3个要点:高遮蔽比是最好的,技术即使在小数据集上也能很好地工作,当涉及到自监督视频抑制时,质量>数量。
3、 Quality Not Quantity: On the Interaction between Dataset Design and Robustness of CLIP
💡系统地研究了CLIP预训练数据源之间的相互作用,混合多个数据源并不一定会产生更好的模型。
4、 A Data-Augmentation Is Worth A Thousand Samples: Analytical Moments And Sampling-Free Training
💡数据增强(DA)及其如何影响模型参数的分析研究。例如,给定损失,普通的DAs需要数万个样本才能正确估计损失,并使模型训练收敛。
5、Transformer Memory as a Differentiable Search Index
💡 单个 Transformer 被训练为在给定查询提示的情况下直接输出文档标识符自回归。后续工作也在 NeurIPS 上展示,例如用于文档检索的神经语料库索引器。
4. Graph Neural Networks
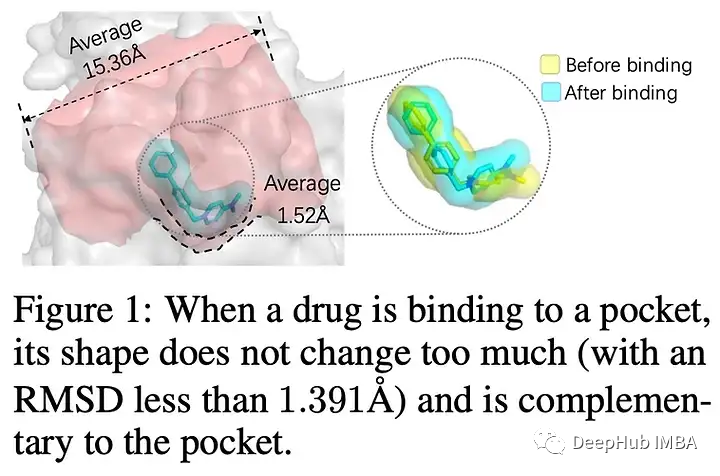
等方差、3D分子生成、偏微分方程……图神经网络(gnn)已经存在了一段时间,虽然它们还没有像Transformers 或扩散模型那样的流行,但在过去几年里它们在稳步增长,并扩展到药物设计、微分方程求解或推理等应用领域。
在某种程度上,gnn是对nn的一种新的抽象,可以从第一原则中解放思想,即如何将任意问题投射到正确的架构中,通过利用对称性和不变性来摆脱维数的诅咒。这是找到正确的表示来计算求解偏微分方程或预测有机分子的形状以更有效地设计新药的关键。
1、 Zero-Shot 3D Drug Design by Sketching and Generating (DESERT)
💡一种由预训练技术驱动的零样本药物设计方法。现有的基于深度学习的药物设计方法往往依赖于稀缺的实验数据或缓慢的对接模拟。DESERT将设计过程分为草图和生成阶段,在保持高精度的同时加快生成速度。
2、 Torsional Diffusion for Molecular Conformer Generation
💡Torsional Diffusion 比以前基于扩散的方法快几个数量级。
3、 MAgNet: Mesh Agnostic Neural PDE Solver
💡一种新颖的网格架构,预测PDE域的任何空间连续点的PDE解决方案,并且可以在不同的网格和分辨率上推广。
4、 MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields
💡消息传递神经网络(MPNNs)是一种模拟原子间电位的强大方法,但效率很低。MACE以高度并行的方式引入高阶消息传递,在各种基准测试中实现SOTA。
5、Few-shot Relational Reasoning via Connection Subgraph Pretraining (CSR)
💡CSR可以通过知识图上的自我监督预训练,直接对少样本任务进行预测。
5. Reinforcement Learning

让代理更高效地学习是RL研究人员仍在努力解决的一个关键问题,而今年的NeurIPS包含了许多关于如何实现这一目标的建议。例如,大规模使用离线学习和模仿学习来克服最初低效的探索阶段,改进信用分配技术以更好地获得稀疏的奖励环境,或使用预训练的语言模型来引导具有人类先验的政策。其他兴趣点通常围绕着稳健性和再现性,这与具有挑战性的开放式设置中的效率密切相关。
最后,RL也看到了在芯片设计等领域的成功应用,有相当多关于该主题的论文。
1、 Using natural language and program abstractions to instill human inductive biases in machines
💡元学习代理可以通过与语言描述和程序归纳的表示进行联合训练来学习人类归纳偏见。
2、 MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
💡利用大型预训练模型自动标记视频动作,创建大规模数据集用于离线学习,仅使用来自Minecraft的视频数据。
3、 MaskPlace: Fast Chip Placement via Reinforced Visual Representation Learning
💡学习在硅芯片设计上分配组件的RL代理比人类更好。
4、 Spending Thinking Time Wisely: Accelerating MCTS with Virtual Expansions
💡MCTS通过在更困难的状态上分配更高的计算预算来提高效率。
5、Trajectory balance: Improved credit assignment in GFlowNets
💡GFlowNets 解决了信用分配问题(轨迹中的哪个动作对最终奖励最负责?),可以获得更快的收敛和更好地拟合到目标分布。
6. Brain-Inspired
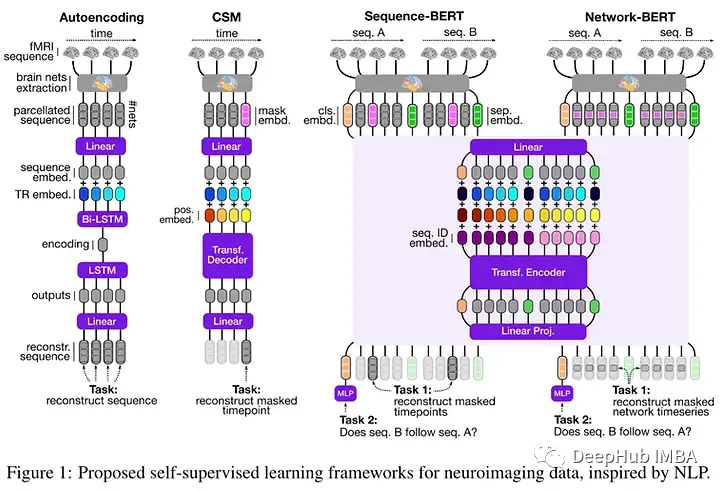
NeurIPS也是神经科学相关文献的发源地;我们的大脑是OG神经信息处理系统,它激发了许多现代人工神经网络。
这一多样化的领域涉及到从脑成像技术(如功能磁共振成像)中学习的大量内容,可以替代我们对神经元、spike Neural Networks等的了解!
1、 Learning on Arbitrary Graph Topologies via Predictive Coding
💡Backprop不允许在具有循环或向后连接的网络上进行训练,这被假设为类脑计算的必要条件。论文展示了预测编码(PC),一种在皮层中进行信息处理的理论,如何用于对任意图拓扑进行推理和学习。
2、 Theoretically Provable Spiking Neural Networks
💡具有自连接的spike神经网络的逼近能力和计算效率的理论研究。
3、 Self-Supervised Learning of Brain Dynamics from Broad Neuroimaging Data
💡新颖的神经成像数据自监督学习技术,灵感来自自然语言处理中的学习框架,使用迄今为止用于预训练的最广泛的神经成像数据集之一。
4、 On the Stability and Scalability of Node Perturbation Learning
💡节点扰动对过度参数化是可扩展的,但在模型不匹配的情况下是不稳定的。
5、An Analytical Theory of Curriculum Learning in Teacher-Student Networks
7. Out-of-Domain Generalization
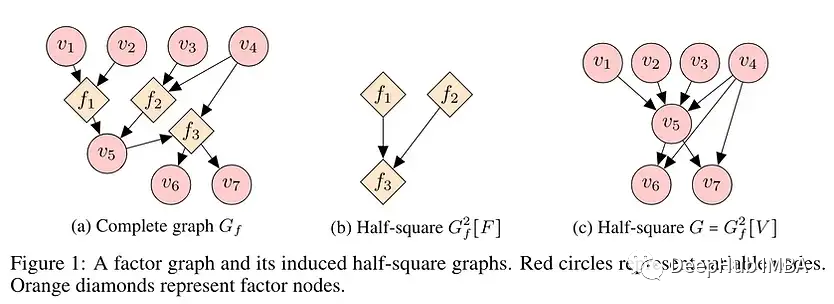
域外泛化与因果关系密切相关,是学术界研究的热点。虽然独立的OOD研究还没有完全成为主流,但在机器学习基准测试中,有一个不可否认的广泛趋势,即越来越关心在具有挑战性的条件下(如零/少样本或大量数据分布变化)的健壮泛化,因为静态域内评估已经以破纪录的速度一个接一个地被破解。
与大多数早期阶段一样,该领域仍然缺乏标准化,这就是为什么我们强调了关于该主题的几篇论文(2,3)。此外还介绍了一种简单的集成技术,用于领域泛化(1),表格嵌入(4),以及用于因果发现的规模稀疏连接因子图(5),这代表了我们之前强调过的研究方向的进展:使用稀疏性+通信瓶颈将模型约束为捕获其健壮的因果结构的世界学习模型。
1、 Ensemble of Averages: Improving Model Selection and Boosting Performance in Domain Generalization
💡在训练和集成期间使用模型参数的简单移动平均的简单无参数策略在领域泛化基准上实现了SOTA,并且可以使用Bias-Variance权衡来解释。
2、 Assaying Out-Of-Distribution Generalization in Transfer Learning
💡分布外泛化的大规模实证研究。
3、 Is a Modular Architecture Enough?
💡用于研究广泛的混合专家的模块化系统的度量标准。这样的系统会出现崩溃和专门化的问题,可能需要额外的归纳偏差来克服这种次优性。
4、 On Embeddings for Numerical Features in Tabular Deep Learning
💡用向量代替标量值表示数值特征可以显著提高DL模型处理表格数据的能力。
5、Large-Scale Differentiable Causal Discovery of Factor Graphs
💡使用因子图进行大规模因果发现学习。
8. Learning Theory
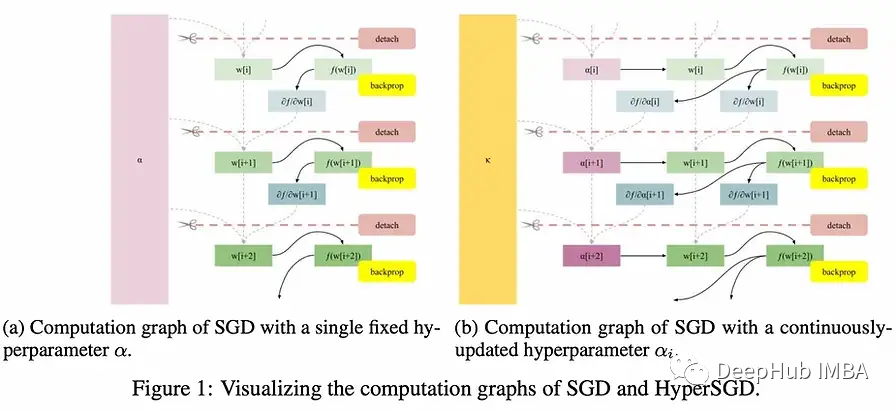
我们中的许多人都觉得繁重的数学东西令人讨厌。但是NeurIPS还是有很多东西可以学习。
大批量已被证明是通过对比学习成功学习表征的必要条件。这在直觉上是有道理的,但有没有更有根据的统计解释呢?(1)或者当我们盲目地对不够平滑的函数使用autodiff时,我们能得到什么保证呢?(3)或者在哪些条件下,在分布外情况下表现良好是可能的?(2).如果你对这些问题感兴趣,请查看下面的论文。
1、 Why do We Need Large Batch sizes in Contrastive Learning? A Gradient-Bias Perspective
💡一种贝叶斯数据增强方法,用于在对比学习中消除梯度偏差的负样本。
2、 Is Out-of-Distribution Detection Learnable?
💡通过可能近似正确(PAC)学习理论的视角,研究了OOD检测的泛化:分类样本是否属于训练分布。他们发现在某些条件下这是不可能的,并证明了关于它的形式定理,但这些条件在现实世界的问题中大多不需要考虑。
3、 Automatic differentiation of nonsmooth iterative algorithms
💡当你对不够平滑的函数应用autodiff时会发生什么?基本上还好。它们都收敛于经典导数。
4、 Efficient and Modular Implicit Differentiation
💡Autodiff,但以隐式形式(即当您无法将f(x)隔离在等号的左侧时)。
5、Gradient Descent: The Ultimate Optimizer
💡使用梯度下降不仅可以调优超参数,还可以调优超超参数,这项工作展示了如何通过对反向传播进行简单而优雅的修改来自动计算超梯度。
9. Adversarial Robustness, Federated Learning, Compression
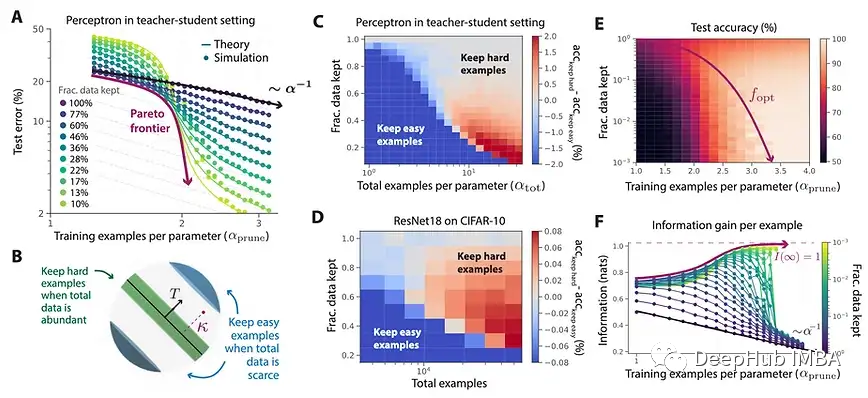
ML中的对抗鲁棒性已经是一个很长时间的事情了,今年也没有什么不同(3,5)。这是可以理解的,因为当涉及到在安全关键应用(如自动驾驶)中使用模型时,这是一个非常重要的问题。
联邦学习,有时与差分隐私结合是另一个多产的研究领域,仍然需要在主流的现实世界应用中找到它的用途(2)。压缩,剪枝和其他速度/效率增强技术(4)已经在现实世界中广泛使用。
1、 Beyond neural scaling laws: beating power law scaling via data pruning
💡在理论和实践中,关于数据集大小的幂律误差缩放可以通过智能数据修剪来改善。
2、 Self-Aware Personalized Federated Learning
💡提出了一种新的自适应用于个性化的联邦学习算法。
3、 Increasing Confidence in Adversarial Robustness Evaluations
💡这项测试,使研究人员能够发现有缺陷的对抗性稳健性评估。通过这个测试产生了令人信服的证据,证明所使用的攻击具有足够的能力来评估模型的鲁棒性。
4、 On-Device Training Under 256KB Memory
💡用于在小型物联网设备上进行设备上训练的框架,即使在有限的256KB内存也可以。
5、Pre-trained Adversarial Perturbations
💡一种使用预训练模型生成对抗样本的新算法,该算法可以欺骗相应的微调模型,从而揭示微调预训练模型执行下游任务的安全问题。
10. Datasets & Benchmarks

最后但并非最不重要的是ML的中的基础。随着进步的步伐不断加快,现代数据集的饱和速度也比大多数人预测的要快。和去年一样,NeurIPS为数据集和基准论文设立了一个特殊的渠道。
许多提议的基准测试都非常有趣和有用,所以下面的列表肯定会遗漏其中的一些,我们这里只介绍我们觉得感兴趣的。
1、 LAION-5B: An open large-scale dataset for training next generation image-text models
💡一个开放的,公开的5.8B图像-文本对数据集,通过重现训练不同规模的最先进的CLIP模型的结果来验证它。
2、 DC-BENCH: Dataset Condensation Benchmark
💡Dataset condensed旨在学习一个微小的数据集,该数据集捕获原始数据集中编码的丰富信息。
3、 NeoRL: A Near Real-World Benchmark for Offline Reinforcement Learning
💡近真实世界离线RL基准(NeoRL),重点是在真实世界应用程序中部署离线RL的完整管道,旨在弥合离线评估和在线部署性能之间的性能差距。
4、 A Unified Evaluation of Textual Backdoor Learning: Frameworks and Benchmarks
💡在训练阶段注入后门可能是对手控制语言模型等NLP系统的强大方法。这项工作提供了一个开源工具包OpenBackdoor,可以严格评估模型对这类攻击的脆弱性。
5、PEER: A Comprehensive and Multi-Task Benchmark for Protein Sequence Understanding
💡一个全面的多任务蛋白质序列理解基准,它研究单任务和多任务学习。
以上就是我们对 NeurIPS 的完整总结,希望对你有所帮助。
作者:Sergi Castella i Sapé zeta-alpha