人工智能导论期末复习重点
绪论人工智能诞生于1956,达特茅斯会议,与空间技术和原子能技术统称为20世纪三大科学技术成就,智能是知识和智力的总和,知识是一切智能行为的基础,智力是获取知识并应用知识求解问题的能力。麦卡锡----人工智能之父。1969年成立国际人工智能会议。1970年创立人工智能杂志,1957年提出感知机模型智
有手就行的移动平均法、指数平滑法的Excel操作,用来时间序列预测
有手就行的移动平均法、平滑指数在Excel中的操作,可以用来简单的时间序列预测。
stata回归?固定效应模型(组内变换OR LSDV最小二乘法)
通过在命令中加入选项“robust”可以获得White稳健标准误,可以解决异方差的问题。在命令中加入选项“cluster”可以获得Rogers标准误或聚类稳健的标准误,可以同时解决异方差和自相关两大问题。使用命令xtscc可以同时解决三大问题,提供Driscoll-Kraay标准误。
盘点5种最频繁使用的检测异常值的方法(附Python代码)
在统计学中,异常值是指不属于某一特定群体的数据点。它是一个与其他数值大不相同的异常观测值,与良好构成的数据组相背离。例如,你可以清楚地看到这个列表里的异常值:[20, 24, 22, 19, 29, 18, 4300, 30, 18].当观测值仅仅是一堆数字并且是一维时,很容易识别出异常值。但是,当
基于大数据的农产品价格信息监测分析系统
本项目利用网络爬虫技术从某蔬菜网采集所有农产品的价格数据,包括北京、上海、安徽、湖北等全国所有省和直辖市的农产品价格数据,解析后存储到数据库中。 建立农产品价格数据仓库,以web交互形式对外提供检索服务,并利用 echarts 实现农产品的可视化分析。...
网络结构数据分析:揭示复杂系统背后的规律
网络结构数据分析是指通过对复杂系统中的各种节点(例如人、公司、物品等)之间的关系进行建模和分析,来揭示这些节点之间的联系、交互和影响规律的一种数据分析方法。网络结构数据分析主要涉及到以下几个方面:1.节点的度和中心性:度指的是节点与其他节点直接相连的数量,而中心性则是指节点在整个网络中的重要程度,例
毕业设计 基于大数据的社交平台数据爬虫舆情分析可视化系统
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是🚩基于大数据的社交平台数据爬虫舆情分析可视化
数据分析Power BI案例:产品与客户销售数据分析
本节课我们以产品与销售数据表.xlsx文件作为数据源,实现一个简单的Power BI项目打开Power BI Desktop,从登录界面或文件选项选择“获取数据”,选择从“Excel”导入,点击连接,找到产品与销售数据表.xlsx文件并打开。选中两个sheet表,然后点击加载数据。ctrl+s保存为
【数据挖掘实战】——航空公司客户价值分析(K-Means聚类案例)
在企业的客户关系管理中,对客户分类,区分不同价值的客户。针对不同价值的客户提供个性化服务方案,采取不同营销策略,将有限营销资源集中于高价值客户,实现企业利润最大化目标。在竞争激烈的航空市场里,很多航空公司都推出了优惠的营销方式来吸引更多的客户。在此种环境下,如何将公司有限的资源充分利用,提示企业竞争
什么是用户增长? (超详细)
增长思维
奇异值分解(SVD)和np.linalg.svd()函数用法
奇异值分解是一种十分重要但又难以理解的矩阵处理技术,在机器学习中是最重要的分解没有之一的存在。那么,奇异值分解到底是在干什么呢?
数据挖掘(2.2)--数据预处理
描述数据的中心趋势、数据发散、数据清洗
一文速学-GBDT模型算法原理以及实现+Python项目实战
上篇文章内容已经将Adaboost模型算法原理以及实现详细讲述实践了一遍,但是只是将了Adaboost模型分类功能,还有回归模型没有展示,下一篇我将展示如何使用Adaboost模型进行回归算法训练。首先还是先回到梯度提升决策树GBDT算法模型上面来,GBDT模型衍生的模型在其他论文研究以及数学建模比
【数据挖掘实战】——应用系统负载分析与容量预测(ARIMA模型)
系统负载分析的传统方法:通过监控采集到的性能数据以及所发出的告警事件,人为进行判断系统的负载情况。实际业务中,监控系统会每天定时对磁盘的信息进行收集,但是磁盘容量属性一般情况下都是一个定值(不考虑中途扩容的情况),因此磁盘原始数据中会存在磁盘容量的重复数据。在不考虑人为因素的影响时,存储空间随时间变
数据挖掘(2.3)--数据预处理
三、数据集成和转换1.数据集成2.数据冗余性2.1 皮尔森相关系数2.2卡方检验3.数据转换
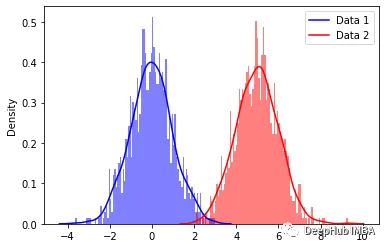
高斯混合模型 GMM 的详细解释
高斯混合模型(后面本文中将使用他的缩写 GMM)听起来很复杂,其实他的工作原理和 KMeans 非常相似,你甚至可以认为它是 KMeans 的概率版本。 这种概率特征使 GMM 可以应用于 KMeans 无法解决的许多复杂问题。
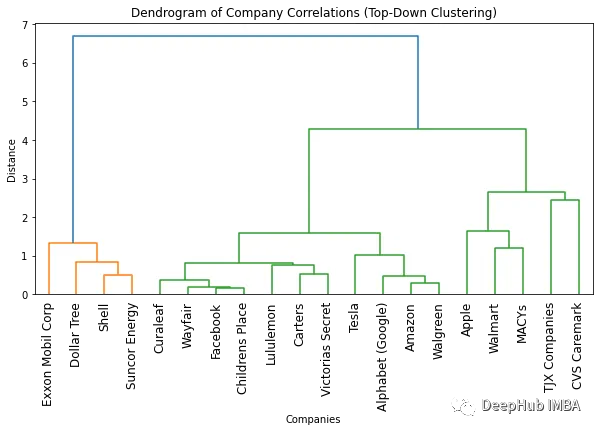
使用树状图可视化聚类
这篇文章中,我们介绍如何使用树状图(Dendrograms)对我们的聚类结果进行可视化。
10种基于MATLAB的方程组求解方法
直接发和迭代法,都有一定的适用范围,对应复杂的方程组,往往没法收敛,启发式算法,比如粒子群,可以自适应的对方程组的解进行求解,对复杂的方程组的求解精度一般更高,代码通用性更强,PSO是由Kennedy和Eberhart共同提出,最初用于模拟社会行为,作为鸟群或鱼群中有机体运动的形式化表示。
时间序列模型-ARIMA
主要介绍了ARIMA模型的基本概念和建模流程。



