
前言
RDD作为分布式计算弹性数据集在PySpark占有十分重要的地位,因此学会如何操作RDD的pyspark的接口函数显得十分重要,
PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼容python其他库,这就给了PySpark极大的使用空间,能够结合大数据集群实现更高效更精确的大数据处理或者预测。如果能够将这些工具都使用的相当熟练的话,那必定是一名优秀的大数据工程师。故2023年这一年的整体学习重心都会集中在这门技术上,当然Pandas以及Numpy的专栏都会更新。我将对PySpark专栏给予极大的厚望,能够实现从Pandas专栏过度到PySpark专栏零跨度学习成本,敬请期待。
此篇文章将主要描述清楚每个RDD的API函数功能用法,了解RDD可用的操作才能最大限度的发挥大数据分布式计算的功能。
一、转换与行动
这里补充一点之前有讲过的知识,RDD的操作函数即将完结也可以更好的对整个函数进行分类。在spark的RDD的操作可以分为两种,一种是转化操作(transformation),另一种是行动操作(action)。在转化操作当中,spark不会为我们计算结果,而是会生成一个新的RDD节点,记录下这个操作。只有在行动操作执行的时候,spark才会从头开始计算整个计算。这就是为什么RDD称为惰性数据集的原因,而转化操作又可以进一步分为针对元素的转化操作以及针对集合的转化操作。
许多转换操作都是针对各个元素的,也就是说,这些转换操作每次只会操作 RDD 中的一个元素,不过并不是所有的转换操作都是这样的。
此类的转化和行动操作根据函数的行为都可以判断出来,这里给出几个常见的转化和行动操作:
转换:
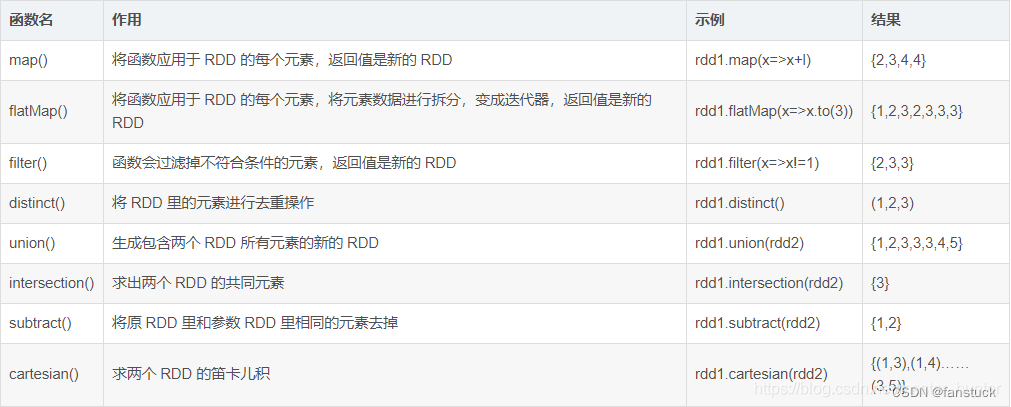
行动:
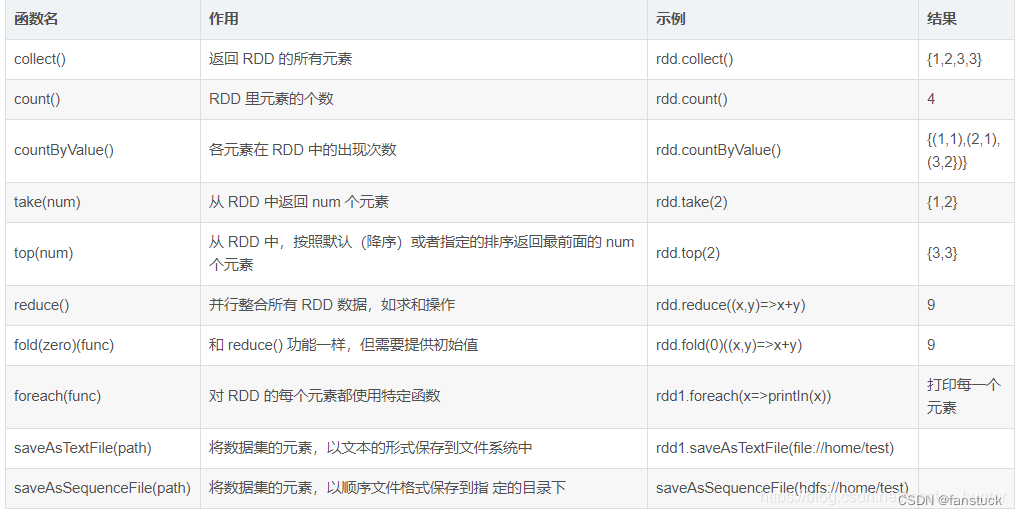
1.foreach(函数遍历操作)
将函数应用于此RDD的所有元素。在日志输出:
def f(x):x=x+1
sc.parallelize([1, 2, 3, 4, 5]).foreach(f)
2.foreachPartition(分区函数遍历操作)
将函数应用于此RDD的每个分区。在日志输出:
def f(iterator):
for x in iterator:
print(x)
sc.parallelize([1, 2, 3, 4, 5]).foreachPartition(f)
3.fullOuterJoin(右外连接)
RDD.fullOuterJoin(other: pyspark.rdd.RDD[Tuple[K, U]],
numPartitions: Optional[int] = None)
→ pyspark.rdd.RDD[Tuple[K, Tuple[Optional[V], Optional[U]]]]
执行右外连接。对于自身中的每个元素(k,v),生成的RDD将包含其他元素中的w的所有对(k,(v,w)),或者如果其他元素中没有元素具有键k,则包含对(k、(v,None))。
类似地,对于other中的每个元素(k,w),生成的RDD将包含自身中的v的所有对(k,(v,w)),或者如果自身中没有元素具有键k,则包含对(k、(None,w)。
哈希将生成的RDD划分为给定数量的分区。
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2), ("c", 8)])
sorted(x.fullOuterJoin(y).collect())
4.getNumPartitions(获取分区数)
RDD.getNumPartitions() → int
返回RDD中的分区数
rdd = sc.parallelize([1, 2, 3, 4], 2)
rdd.getNumPartitions()

5.getCheckpointFile(获取此RDD被检查指向的文件的名称)
RDD.getCheckpointFile() → Optional[str]
获取此RDD被检查指向的文件的名称
如果RDD是本地检查点,则未定义。
6.getResourceProfile
RDD.getResourceProfile() → Optional[pyspark.resource.profile.ResourceProfile]
获取使用此RDD指定的pyspark.resource.ResourceProfile,如果未指定,则获取None。
7.getStorageLevel(获取当前存储级别)
RDD.getStorageLevel() → pyspark.storagelevel.StorageLevel
获取RDD的当前存储级别。
8.groupBy(分组聚合)
RDD.groupBy(f: Callable[[T], K],
numPartitions: Optional[int] = None,
partitionFunc: Callable[[K], int] = <function portable_hash>)
→ pyspark.rdd.RDD[Tuple[K, Iterable[T]]]
返回分组的RDD。
rdd = sc.parallelize([1, 1, 2, 3, 5, 8])
result = rdd.groupBy(lambda x: x % 2).collect()
sorted([(x, sorted(y)) for (x, y) in result])

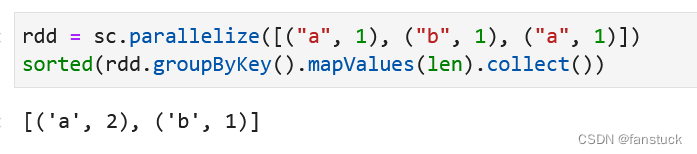
9.groupByKey(通过Key分组)
RDD.groupByKey(numPartitions: Optional[int] = None,
partitionFunc: Callable[[K], int] = <function portable_hash>)
→ pyspark.rdd.RDD[Tuple[K, Iterable[V]]]
将RDD中每个键的值分组为单个序列。使用numPartitions分区对生成的RDD进行哈希分区。
如果正在分组以便对每个键执行聚合(例如求和或平均值),那么使用reduceByKey或aggregateByKey将提供更好的性能。
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
sorted(rdd.groupByKey().mapValues(len).collect())
10.groupWith
RDD.groupWith(other: pyspark.rdd.RDD[Tuple[Any, Any]],
*others: pyspark.rdd.RDD[Tuple[Any, Any]])
→ pyspark.rdd.RDD[Tuple[Any, Tuple[pyspark.resultiterable.ResultIterable[Any], …]]]
共组的别名,但支持多个RDD。
11.intersection(交集)
RDD.intersection(other: pyspark.rdd.RDD[T]) → pyspark.rdd.RDD[T]
返回此RDD与另一个RDD的交集。输出将不包含任何重复的元素。
rdd1 = sc.parallelize([1, 10, 2, 3, 4, 5])
rdd2 = sc.parallelize([1, 6, 2, 3, 7, 8])
rdd1.intersection(rdd2).collect()

12.isEmpty(判断为空)
RDD.isEmpty() → bool
当且仅当RDD完全不包含元素时,返回true。

13.isLocallyCheckpointed(返回此RDD是否标记为本地检查点)
RDD.isLocallyCheckpointed() → bool
返回此RDD是否标记为本地检查点。
14.join(连接)
RDD.join(other: pyspark.rdd.RDD[Tuple[K, U]],
numPartitions: Optional[int] = None)
→ pyspark.rdd.RDD[Tuple[K, Tuple[V, U]]]
返回包含self和other中具有匹配键的所有元素对的RDD。
每对元素都将作为(k,(v1,v2))元组返回,其中(k,v1)在self中,(k,v2)在other中。
跨集群执行哈希连接。
x = sc.parallelize([("a", 1), ("b", 4)])
y = sc.parallelize([("a", 2), ("a", 3)])
sorted(x.join(y).collect())
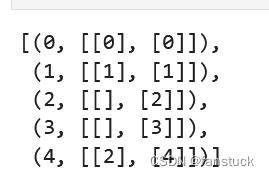
15.keyBy
RDD.keyBy(f: Callable[[T], K]) → pyspark.rdd.RDD[Tuple[K, T]]
通过应用f创建此RDD中元素的元组。

点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。