
前言
自20世纪90年代以来,随着数据库技术应用的普及,数据挖掘( Data Mining )技术已经引起了学术界、产业界的极大关注,其主要原因是当前各个单位已经存储了超大规模,即海量规模的数据,未来能够真正发挥这些数据的实际价值。由于数据分析和管理工作的应用需要,需将这些数据转换成有用的信息和知识,即从传统的数据统计向数据挖掘与分析进行转换。另外,通过数据挖掘技术获取的信息和知识还可以广泛应用于各个行业领域,包括市场开拓与分析、商务管理、生产控制、工程设计和科学探索等方面。(摘自《数据挖掘:方法与应用》徐华)
正文
1.数据挖掘的历史和发展
a.基本描述
数据挖掘(DataMining,DM)又称数据库中的知识发现(Know ledge Discover in Database, KDD)是涉及机器学习、人工智能、数据库理论以及统计学等学科的交叉研究领域。
数据挖掘就是从数据库的大量数据中挖掘出有用的信息,即从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,发现隐含的、规律性的、人们事先未知的,但又是潜在有用的并且最终可理解的信息和知识的非平凡过程。并非所有与数据库相关的操作与分析都属于数据挖掘研究的范畴。
数据挖掘(Data Mining,DM)是知识发现(KDD)最核心的部分。
数据挖掘数学理论基础的发展,与统计学的发展密不可分。
b.典型的知识发现过程
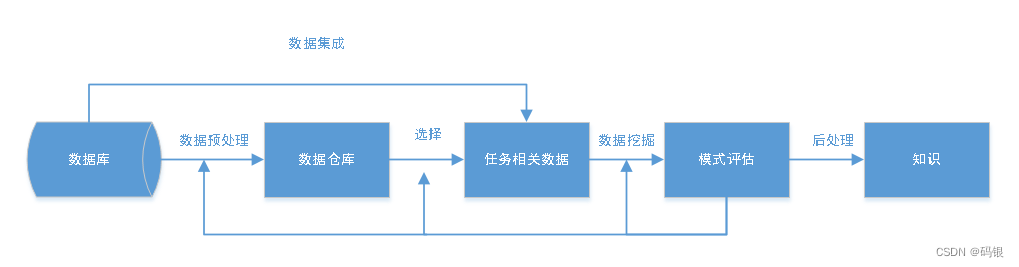
c.典型的数据挖掘系统结构
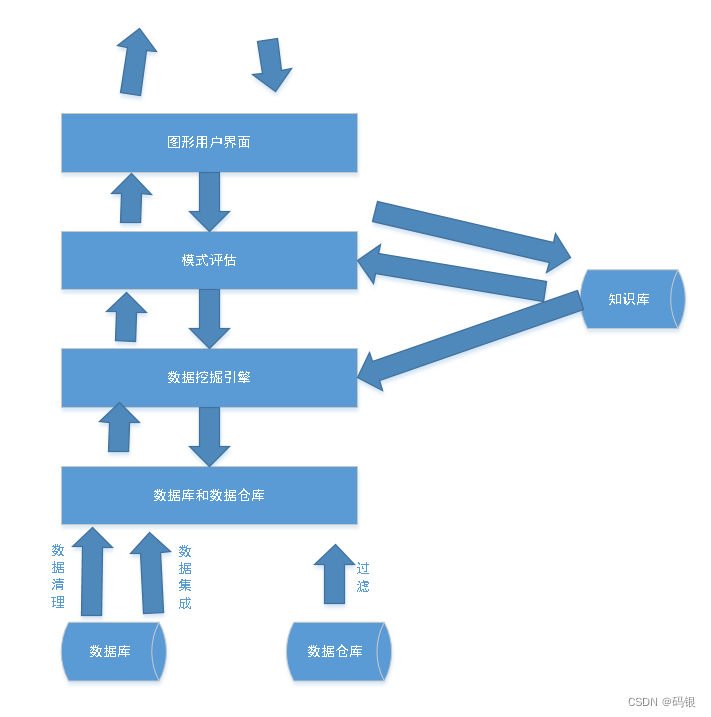
d. 数据挖掘中还存在许多问题有待进一步研究
数据挖掘中还存在许多问题有待进一步研究,包括下列几个研究方向:
①算法效率和可伸缩性
②处理不同类型的数据和数据源
③数据挖掘系统的交互性
④数据挖掘中的信息保护与数据安全
⑤探索新的应用领域
⑥数据挖掘结果的可用性、确定性及可表达性
⑦可视化数据挖掘
3.数据挖掘的研究内容和功能
a.研究内容
数据挖掘所发现的知识最常见的有以下五类:
①广义知识(General ization)
广义知识指类别特征的概括性描述知识,反映同类事物共同性质,
它是对数据的概括、精炼和抽象
②关联知识(Assoc iati on)
关联知识反映一个事件和其他事件之间依赖或关联的知识,又称依
赖(Dependency) 关系
③分类知识(Classif icat ion &Cluster ing)
分类知识用来反映同类事物共同性质的特征型知识和不同事物之间
的差异型特征知识
④预测型知识(Predi ct ion)
预测型知识根据时间序列型数据,由历史的和当前的数据去推测未
来的数据,也可以认为是以时间为关键属性的关联知识
⑤偏差型知识(Devi at ion)
偏差型知识是对差异和极端特例的描述,揭示事物偏离常规的异常
现象,如标准类外的特例,数据聚类外的离群值等
b.数据挖掘的主要功能
1.类/概念描述:特征化和区分
对含有大量数据的数据集合进行描述性的总结并获得简明、准确的描述,这种描述就称为类/概念描述(Class/ConceptDescr iption)。。
这种描述可以通过下述方法得到:
(1)数据特征化
(2)数据区分
(3)数据特征化和比辑
2.关联分析
关联分析(Association Analysis) 就是从给定的数据集中发现频繁出现的项集模式知识,又称为关联规则age(X,“20..29”)^income(X,“20..29K") >buys(X,“PC”)[support = 2%, confidence = 60%]
3.分类和预测
数据挖掘相关的研究工作中常常还力图构建一个模型或者描述函数来刻画或者区分不同的类型与概念,以实现对于未来潜在的预测需求。例如在实际工作中,往往会根据气候的类型来对相关国家进行分类,分为热带国家、温带国家和寒带国家。实际生活中,会根据小汽车的排量对小汽车进行分类。分为小排量汽车、大排量汽车等类型。在实际应用数据挖掘技术解决相关问题的过程中,常常会采用分类技术与方法解决对未知的结果或者未知量化特征的预测。
4.聚类分析
聚类分析(无论是在学习还是在归类预测时)所分析处理的数据均是无(事先确定)类别归属的。
聚类原则:最大化类内的相似性
最小化类间的相似性
5.孤立点分析
大部分数据挖掘方法将孤立点视为噪声或异常而丢弃,但是孤立点可以使用统计试验检测。
6.演变分析
数据演变分析(Evolution Analysis) 就是对随时间变化的数据对象的变化规律和趋势进行建模描述。
4.数据挖掘常用的技术和工具
a.数据挖掘常用的技术
预测技术、聚类分析、进化计算、模糊逻辑、对策树、统计分析、决策与控制理论、并行计算海童存储、关联规则技术、粗糙集技术、灰色系统、人工智能、知识推理、可视化技术
b.数据挖掘的十大经典算法
1.决策树分类器C4.5(分类算法)
2.K-均值算法(聚类算法)
3.支持向量机(分类算法)
4.Apriori算法(频繁模式分析算法)
5.最大期望估计算法(集成弱分类器)
6.PageRank算法(排序算法)
7.AdaBoost算法(集成弱分类器)
8.K最近邻分类算法(分类算法)
9.朴素贝叶斯算法(分类算法)
10.分类与回归树算法(聚类算法)
C4.5 (61 votes)
K-Means (60 votes)
SVM (58 votes)
Apriori (52 votes)
EM (48 votes)
PageRank (46 votes)
AdaBoost (45 votes)
kNN (45 votes)
Naive Bayes (45 votes)
CART (34 votes)
c.数据挖掘的工具
1、基于神经网络的工具
神经网络用于分类、特征挖掘、预测和模式识别。
2、基于规则和决策树的工具
其主要优点是:规则和决策树都是可读的。
3、基于模糊逻辑的工具
该方法应用模糊逻辑进行数据查询、排序等。
4、综合多方法的工具
这类工具一般规模较大,适用于大型数据库(包括并行数据库)
d.传统的数据分析方法与数据挖掘
(1)海量数据
(2)高维数据
(3)高复杂性数据。如下是日常工作中几类典型的搞复杂度数据
①数据流与传感数据。
②时间序列数据、随时间而变化的数据序列。
③结构化数据、图、社会关系网络、多链接关系数据。
④异构数据库、法律数据。
⑤空间数据、时空描述数据、多媒体数据、 Web 数据。
⑥软件程序、科学仿真数据等。
5.数据挖掘应用热点
数据挖掘技术源于商业的直接需求,并在各种领域都有广泛的使用价值。
1.金融领域的应用
2.网络金融交易方面
3.零售业务应用
4.医疗电信领域应用
6.数据挖掘面对的主要问题
a.挖掘方法所面临的问题
(1)在实际使用数据挖掘方法发现知识时,通常会希望所采用的挖掘方法能够实现从不同类型的数据中挖掘不同种类的知识。
(2) 数据挖掘的对象往往是大规模海量数据,挖掘算法的性能也是数据挖掘过程中常常引起关注的重要问题之一。
(3)描述性数据挖掘任务中需要对所分析的频繁模式或者规律进行相应的模式评估
(4)数据挖掘工作服务的对象往往是具有不同专业背景的用户。在挖掘方法中如何融合相关的背景知识使挖掘工作更有针对性,也是挖掘方法研究的一个重要问题。
(5)在挖掘方法的使用过程中,往往被挖掘对象都是带有噪声和不完全的数据。
(6)近年来,随着并行计算技术的成熟和云计算技术平台的构建,未来对于海量数据的挖掘方法往往要求能够具有并行化、分布式和增量性的特点。
(7)挖掘算法要能够主动集成所发现的知识,即实现知识的融合。
b.用户交互性的问题
(1)在用户交互性问题上,需要提出一种面向数据挖掘的查询语言以实现即时数据挖掘。(2)需要针对用户的数据挖掘结果的表示和可视化呈现技术,以一种直观方式呈现挖掘的结果。即开展面向数据挖掘技术的计算可视化方法研究。
(3)用户往往需要在多个抽象层次实现交互式挖掘,即要求整个数据挖掘过程具有可交互性。
c.应用与社会影响
(1)在应用方面。迫切需要开展面向领域的数据挖掘,并实现常人无法感知和不可见的数据挖掘。(2)在数据挖掘的应用过程中还需要加强对于数据安全性、完整性和隐私性的保护。
小结
本章详细分析了数据挖掘中的一-些基本概念,阐述了数据挖掘技术的历史和发展,总结了数
据挖掘的内容和功能,分析了现有数据挖掘技术和工具,同时介绍了数据挖掘的应用热点。作为数据库技术发展的必然结果,数据挖掘技术已经得到了广泛的研究与应用。数据挖掘就是从海量数据中发现有价值的知识。一个典型的知识发现过程包括数据清洗、数据集成、数据选择、数据转换、数据挖掘、模式评估和知识表示。数据挖掘工作可以在不同的数据仓库上展开。数据挖掘可以完成:数据的特征抽取、特征识别、关联分析、分类、聚类、离群点分析和趋势分析等。(摘自《数据挖掘:方法与应用》徐华)

版权归原作者 码银 所有, 如有侵权,请联系我们删除。