【机器学习之模型融合】Stacking堆叠法
Stacking堆叠法原理透析与应用

处理缺失值的三个层级的方法总结
缺失值是现实数据集中的常见问题,处理缺失值是数据预处理的关键步骤。本文将展示如何使用三种不同级别的方法处理这些缺失值
Topic 14. 临床预测模型之校准曲线 (Calibration curve)
全网总结最全的校准曲线 Calibration curve
【第十一届泰迪杯数据挖掘挑战赛】A 题:新冠疫情防控数据的分析 思路+代码(持续更新)
【第十一届泰迪杯数据挖掘挑战赛】A 题:新冠疫情防控数据的分析 思路+代码(持续更新)
数据挖掘(1)--基础知识学习
自20世纪90年代以来,随着数据库技术应用的普及,数据挖掘( Data Mining )技术已经引起了学术界、产业界的极大关注,其主要原因是当前各个单位已经存储了超大规模,即海量规模的数据,未来能够真正发挥这些数据的实际价值。由于数据分析和管理工作的应用需要,需将这些数据转换成有用的信息和知识,即从
机器学习期末复习题
机器学习期末复习资料,答案已标注。
聚类算法(下):10个聚类算法的评价指标
上篇文章我们已经介绍了一些常见的聚类算法,下面我们将要介绍评估聚类算法的指标
100天精通Python(数据分析篇)——第48天:数据分析入门知识
数据分析入门知识:1. 为什么要学数据分析?2. 数据分析的概念3. 数据分析涉及哪些能力4. 数据分析的流程5. Python做数据分析学什么?
PySpark数据分析基础:核心数据集RDD原理以及操作一文详解(一)
要进行大数据分析是离不开Spark的,不然怎么说是大数据呢,数据量不达到几个TB也好意思叫大数据(哈...),之前一直使用的Pandas做一些少量数据的分析处理的,发现最近要玩的数据量实在过于巨大了,不得不搬上我们的spark用集群去跑了。但是用Scala总感觉很别扭,主要是已经好久没写scala代
PySpark数据分析基础:核心数据集RDD常用函数操作一文详解(三)
RDD作为分布式计算弹性数据集在PySpark占有十分重要的地位,因此学会如何操作RDD的pyspark的接口函数显得十分重要,PySpark系列的专栏文章目前的话应该只会比Pandas更多不会更少,可以用PySpark实现的功能太多了,基本上Spark能实现的PySpark都能实现,而且能够实现兼
使用Pandas也可以进行数据可视化
在本文中,我们介绍使用 Pandas 进行数据可视化的基础知识,包括创建简单图、自定义图以及使用多个DF进行绘图。
数据仓库基础
数据库中,最大的特点是面向应用进行数据的组织,各个业务系统可能是相互分离的。主题是一个抽象的概念,是较高层次上企业信息系统中的数据综合、归类并进行分析利用的抽象。而基于主题组织的数据则不同,它们被划分为各自独立的领域,每个领域有各自的逻辑内涵但互不交叉,在抽象层次上对数据进行完整、一致和准确的描述。
本科大数据专业能找到大数据开发的工作么
本科大数据专业能不能找到大数据开发的工作取决于你在校期间大数据学科学习的怎么样~目前大二就还有时间去学习,趁着空余时间找个完整的学习路线去学习,争取能够在校招的时候就找到心仪的工作:从传统关系型数据库入手,掌握数据迁移工具、BI数据可视化工具、SQL,对后续学习打下坚实基础。:学习Linux、Had
【湖仓一体化】存OR算之争?SPL 我都要
【湖仓一体化】存or算之争?spl我都要什么是湖仓一体?它和数据仓库、数据湖的关系是什么?为什么要用一体来形容呢

Numpy中数组和矩阵操作的数学函数
Numpy 是一个强大的 Python 计算库。它提供了广泛的数学函数,可以对数组和矩阵执行各种操作。本文中将整理一些基本和常用的数学操作。
R实战 | Nomogram(诺莫图/列线图)及其Calibration校准曲线绘制
R实战|Nomogram(诺莫图/列线图)及其Calibration校准曲线绘制Nomogram,中文常称为诺莫图或者列线图。简单的说是将Logistic回归或Cox回归的结果进行可视化呈...
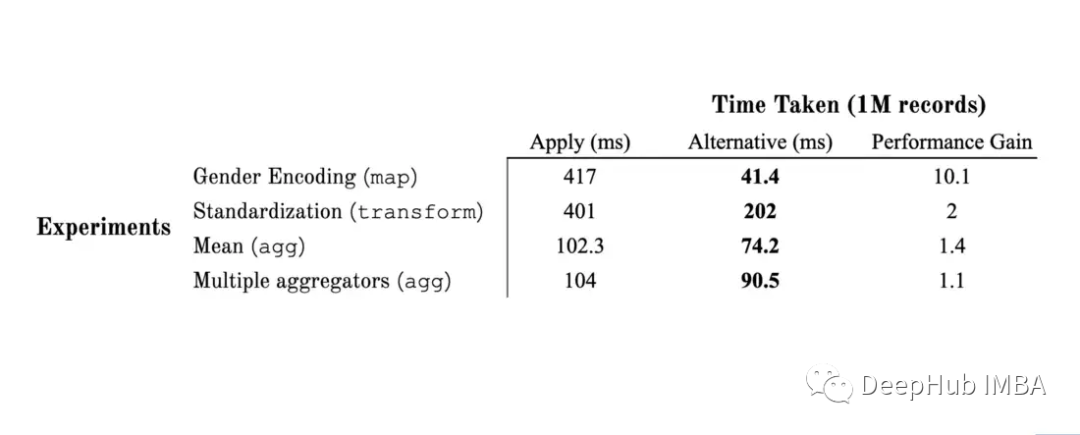
Pandas的apply, map, transform介绍和性能测试
在这篇文章中,我们将通过一些示例讨论apply、agg、map和transform的预期用途。
数据分析:SQL和Python
with as 也叫做子查询部分,类似于一个视图或临时表,可以用来存储一部分的sql语句查询结果,必须和其他的查询语句一起使用,且中间不能有分号,目前在oracle、sql server、hive等均支持 with as 用法,但 mysql并不支持!
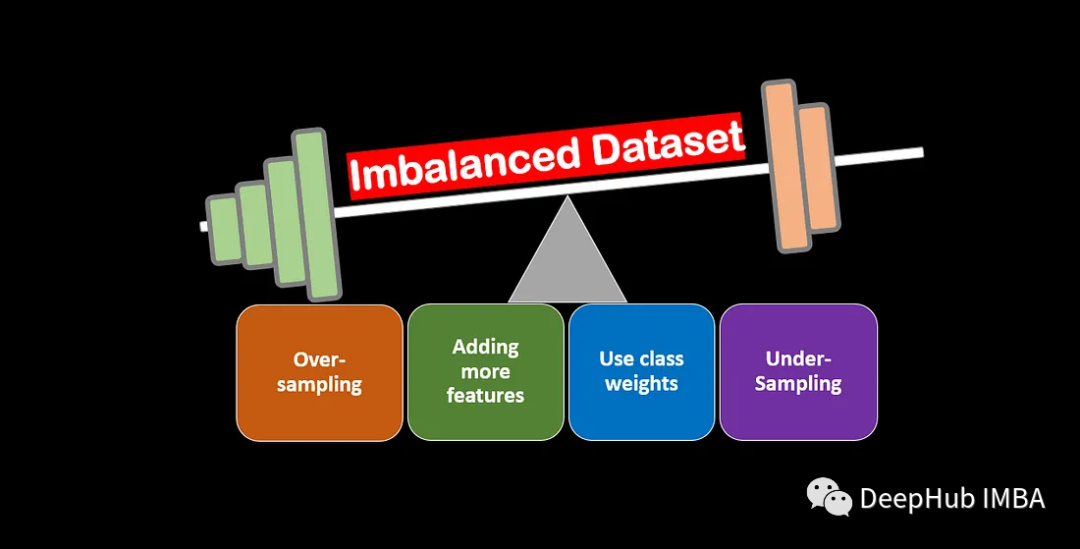
不平衡数据集的建模的技巧和策略
在本文中,我们将讨论处理不平衡数据集和提高机器学习模型性能的各种技巧和策略
监控Python 内存使用情况和代码执行时间
我的代码的哪些部分运行时间最长、内存最多?我怎样才能找到需要改进的地方?”在本文中总结了一些方法来监控 Python 代码的时间和内存使用情况。



