
2024年是大型语言模型(llm)的快速发展的一年,对于大语言模型的训练一个重要的方法是对齐方法,它包括使用人类样本的监督微调(SFT)和依赖人类偏好的人类反馈强化学习(RLHF)。这些方法在llm中发挥了至关重要的作用,但是对齐方法对人工注释数据有的大量需求。这一挑战使得微调成为一个充满活力的研究领域,研究人员积极致力于开发能够有效利用人类数据的方法。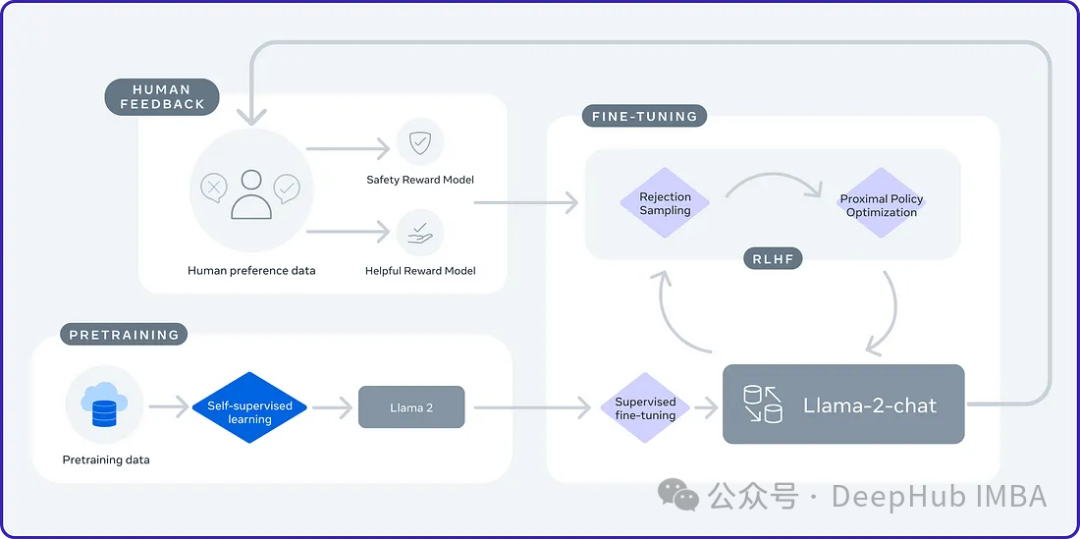
加州大学最近的一项研究介绍了一种名为SPIN(Self Play fIne tuNing)的新技术。SPIN从AlphaGo Zero和AlphaZero等游戏中成功的自我对弈机制中汲取灵感。它能够使LLM参与自我游戏的能力。这消除了对专业注释者的需求,无论是人类还是更高级的模型(如GPT-4)。SPIN涉及训练一个新的语言模型,并通过一系列迭代来区分它自己生成的响应和人类生成的响应。最终目标是开发得到一种语言模型,使其产生的反应与人类产生的反应没有区别。
自我博弈
自我博弈是一种算法通过对抗自身副本来学习的技术。这种方法增加了学习环境的挑战性和复杂性,允许代理与自己的不同版本进行交互。例如AlphaGo Zero,就是一个自我博弈的案例。
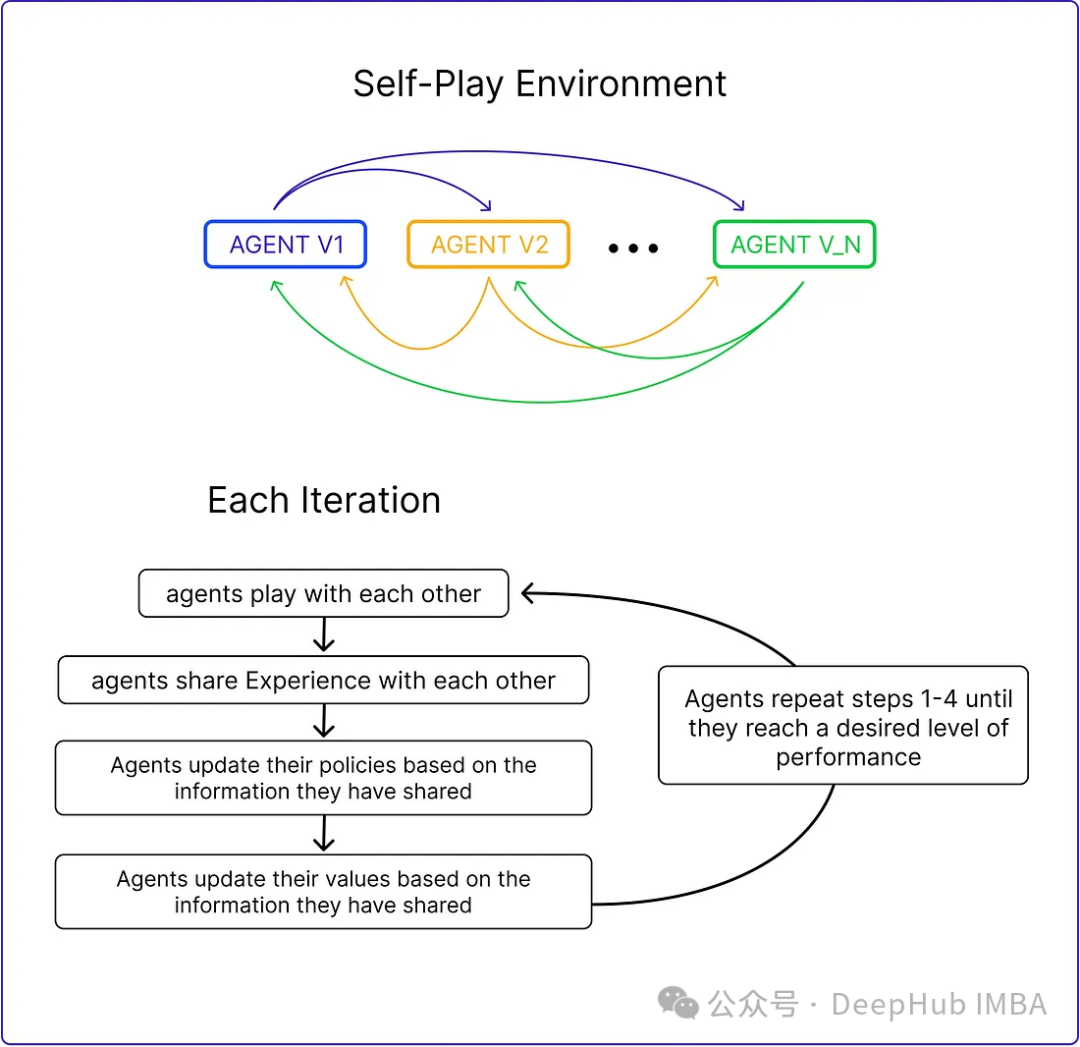
自我博弈在MARL中的有效性已经得到证实,但将其应用于大型语言模型(llm)的增强是一种新的方法。在大型语言模型中应用自我博弈有可能进一步提高他们的能力,使他们能够生成更连贯、信息丰富的文本。
自我游戏既可以用于竞争环境,也可以用于合作环境。在竞争环境中,算法的副本相互竞争以达到特定的目标。在协作设置中,算法的副本一起工作以实现共同的目标。它还可以与其他学习技术相结合,如监督学习和强化学习,以进一步提高算法的性能。
SPIN
SPIN就像一个双人游戏。在这个游戏中:
主模型(新LLM) -这个代理的角色是学习如何区分由语言模型(LLM)生成的响应和由人类创建的响应。在每个迭代中,主模型是正在积极训练的LLM。其目标是提高其识别和区分反应的能力。
对手模型(旧LLM) -对手模型的任务是生成与人类产生的反应没有区别的结果。对手模型是来自前一个迭代(轮)的LLM。它使用自我博弈机制,根据过去的知识产生结果。对手模型的目标是创造逼真的反应,让新的LLM无法判断他是否是机器生成的。
这个流程是不是很像GAN,但是还是不太一样
SPIN的动态涉及使用监督微调(SFT)数据集,该数据集由输入(x)和输出(y)对组成。这些示例由人工注释,并作为训练主模型识别类人响应的基础。一些公开的SFT数据集包括Dolly15K、Baize、Ultrachat等。
主模型的训练
为了训练主模型区分语言模型(LLM)和人类反应,SPIN使用了一个目标函数。这个函数测量真实数据和对手模型产生的反应之间的预期值差距。主模型的目标是最大化这一期望值差距。这包括将高值分配给与真实数据的响应配对的提示,并将低值分配给由对手模型生成的响应配对。这个目标函数被表述为最小化问题。
主模型的工作是最小化损失函数,即衡量来自真实数据的配对分配值与来自对手模型反应的配对分配值之间的差异。在整个训练过程中,主模型调整其参数以最小化该损失函数。这个迭代过程一直持续下去,直到主模型能够熟练地有效区分LLM的反应和人类的反应。
对手模型的更新
更新对手模型涉及改进主模型的能力,他们在训练时已经学会区分真实数据和语言模型反应。随着主模型的改进及其对特定函数类的理解,我们还需要更新如对手模型的参数。当主玩家面对相同的提示时,它便会使用学习得到的辨别能力去评估它们的价值。
对手模型玩家的目标是增强语言模型,使其响应与主玩家的真实数据无法区分。这就需要设置一个流程来调整语言模型的参数。目的是在保持稳定性的同时,最大限度地提高主模型对语言模型反应的评价。这涉及到一种平衡行为,确保改进不会偏离原始语言模型太远。
听着有点乱,我们简单总结下:
训练的时候只有一个模型,但是将模型分为前一轮的模型(旧LLM/对手模型)和主模型(正在训练的),使用正在训练的模型的输出与上一轮模型的输出作为对比,来优化当前模型的训练。但是这里就要求我们必须要有一个训练好的模型作为对手模型,所以SPIN算法只适合在训练结果上进行微调。
SPIN算法
SPIN从预训练的模型生成合成数据。然后使用这些合成数据对新任务上的模型进行微调。

上面时原始论文中Spin算法的伪代码,看着有点难理解,我们通过Python来复现更好地解释它是如何工作的。
1、初始化参数和SFT数据集
原论文采用Zephyr-7B-SFT-Full作为基本模型。对于数据集,他们使用了更大的Ultrachat200k语料库的子集,该语料库由使用OpenAI的Turbo api生成的大约140万个对话组成。他们随机抽取了50k个提示,并使用基本模型来生成合成响应。
# Import necessary libraries
from datasets import load_dataset
import pandas as pd
# Load the Ultrachat 200k dataset
ultrachat_dataset = load_dataset("HuggingFaceH4/ultrachat_200k")
# Initialize an empty DataFrame
combined_df = pd.DataFrame()
# Loop through all the keys in the Ultrachat dataset
for key in ultrachat_dataset.keys():
# Convert each dataset key to a pandas DataFrame and concatenate it with the existing DataFrame
combined_df = pd.concat([combined_df, pd.DataFrame(ultrachat_dataset[key])])
# Shuffle the combined DataFrame and reset the index
combined_df = combined_df.sample(frac=1, random_state=123).reset_index(drop=True)
# Select the first 50,000 rows from the shuffled DataFrame
ultrachat_50k_sample = combined_df.head(50000)
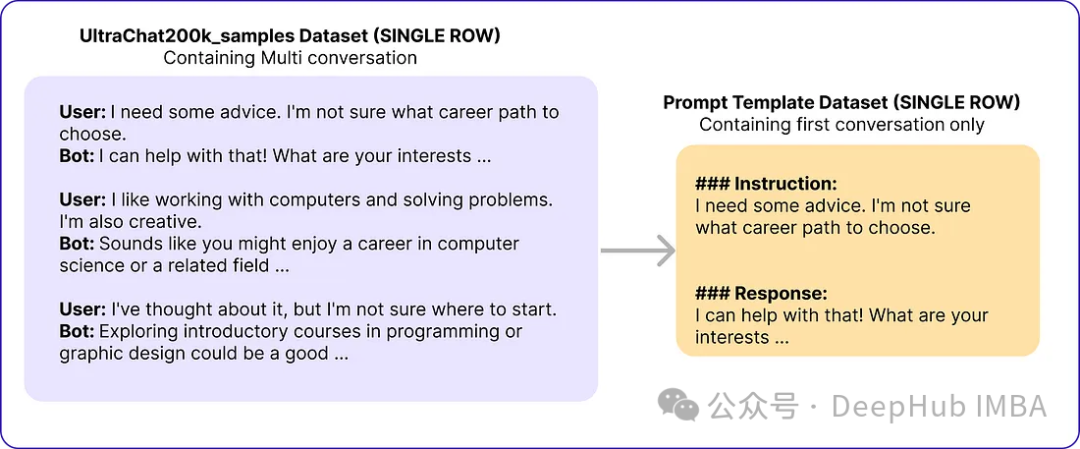
作者的提示模板“### Instruction: {prompt}\n\n### Response:”
# for storing each template in a list
templates_data = []
for index, row in ultrachat_50k_sample.iterrows():
messages = row['messages']
# Check if there are at least two messages (user and assistant)
if len(messages) >= 2:
user_message = messages[0]['content']
assistant_message = messages[1]['content']
# Create the template
instruction_response_template = f"### Instruction: {user_message}\n\n### Response: {assistant_message}"
# Append the template to the list
templates_data.append({'Template': instruction_response_template})
# Create a new DataFrame with the generated templates (ground truth)
ground_truth_df = pd.DataFrame(templates_data)
然后得到了类似下面的数据:
SPIN算法通过迭代更新语言模型(LLM)的参数使其与地面真实响应保持一致。这个过程一直持续下去,直到很难区分生成的响应和真实情况,从而实现高水平的相似性(降低损失)。
SPIN算法有两个循环。内部循环基于我们正在使用的样本数量运行,外部循环总共运行了3次迭代,因为作者发现模型的性能在此之后没有变化。采用Alignment Handbook库作为微调方法的代码库,结合DeepSpeed模块,降低了训练成本。他们用RMSProp优化器训练Zephyr-7B-SFT-Full,所有迭代都没有权重衰减,就像通常用于微调llm一样。全局批大小设置为64,使用bfloat16精度。迭代0和1的峰值学习率设置为5e-7,迭代2和3的峰值学习率随着循环接近自播放微调的结束而衰减为1e-7。最后选择β = 0.1,最大序列长度设置为2048个标记。下面就是这些参数
# Importing the PyTorch library
import torch
# Importing the neural network module from PyTorch
import torch.nn as nn
# Importing the DeepSpeed library for distributed training
import deepspeed
# Importing the AutoTokenizer and AutoModelForCausalLM classes from the transformers library
from transformers import AutoTokenizer, AutoModelForCausalLM
# Loading the zephyr-7b-sft-full model from HuggingFace
tokenizer = AutoTokenizer.from_pretrained("alignment-handbook/zephyr-7b-sft-full")
model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full")
# Initializing DeepSpeed Zero with specific configuration settings
deepspeed_config = deepspeed.config.Config(train_batch_size=64, train_micro_batch_size_per_gpu=4)
model, optimizer, _, _ = deepspeed.initialize(model=model, config=deepspeed_config, model_parameters=model.parameters())
# Defining the optimizer and setting the learning rate using RMSprop
optimizer = deepspeed.optim.RMSprop(optimizer, lr=5e-7)
# Setting up a learning rate scheduler using LambdaLR from PyTorch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lambda epoch: 0.2 ** epoch)
# Setting hyperparameters for training
num_epochs = 3
max_seq_length = 2048
beta = 0.1
2、生成合成数据(SPIN算法内循环)
这个内部循环负责生成需要与真实数据保持一致的响应,也就是一个训练批次的代码
# zephyr-sft-dataframe (that contains output that will be improved while training)
zephyr_sft_output = pd.DataFrame(columns=['prompt', 'generated_output'])
# Looping through each row in the 'ultrachat_50k_sample' dataframe
for index, row in ultrachat_50k_sample.iterrows():
# Extracting the 'prompt' column value from the current row
prompt = row['prompt']
# Generating output for the current prompt using the Zephyr model
input_ids = tokenizer(prompt, return_tensors="pt").input_ids
output = model.generate(input_ids, max_length=200, num_beams=5, no_repeat_ngram_size=2, top_k=50, top_p=0.95)
# Decoding the generated output to human-readable text
generated_text = tokenizer.decode(output[0], skip_special_tokens=True)
# Appending the current prompt and its generated output to the new dataframe 'zephyr_sft_output'
zephyr_sft_output = zephyr_sft_output.append({'prompt': prompt, 'generated_output': generated_text}, ignore_index=True)
这就是一个提示的真实值和模型输出的样例。

新的df zephyr_sft_output,其中包含提示及其通过基本模型Zephyr-7B-SFT-Full生成的相应输出。
3、更新规则
在编码最小化问题之前,理解如何计算llm生成的输出的条件概率分布是至关重要的。原论文使用马尔可夫过程,其中条件概率分布pθ (y∣x)可通过分解表示为:

这种分解意味着给定输入序列的输出序列的概率可以通过将给定输入序列的每个输出标记与前一个输出标记的概率相乘来计算。例如输出序列为“I enjoy reading books”,输入序列为“I enjoy”,则在给定输入序列的情况下,输出序列的条件概率可以计算为:

马尔可夫过程条件概率将用于计算真值和Zephyr LLM响应的概率分布,然后用于计算损失函数。但首先我们需要对条件概率函数进行编码。
# Conditional Probability Function of input text
def compute_conditional_probability(tokenizer, model, input_text):
# Tokenize the input text and convert it to PyTorch tensors
inputs = tokenizer([input_text], return_tensors="pt")
# Generate text using the model, specifying additional parameters
outputs = model.generate(**inputs, return_dict_in_generate=True, output_scores=True)
# Assuming 'transition_scores' is the logits for the generated tokens
transition_scores = model.compute_transition_scores(outputs.sequences, outputs.scores, normalize_logits=True)
# Get the length of the input sequence
input_length = inputs.input_ids.shape[1]
# Assuming 'transition_scores' is the logits for the generated tokens
logits = torch.tensor(transition_scores)
# Apply softmax to obtain probabilities
probs = torch.nn.functional.softmax(logits, dim=-1)
# Extract the generated tokens from the output
generated_tokens = outputs.sequences[:, input_length:]
# Compute conditional probability
conditional_probability = 1.0
for prob in probs[0]:
token_probability = prob.item()
conditional_probability *= token_probability
return conditional_probability
损失函数它包含四个重要的条件概率变量。这些变量中的每一个都取决于基础真实数据或先前创建的合成数据。

而lambda是一个正则化参数,用于控制偏差。在KL正则化项中使用它来惩罚对手模型的分布与目标数据分布之间的差异。论文中没有明确提到lambda的具体值,因为它可能会根据所使用的特定任务和数据集进行调优。
def LSPIN_loss(model, updated_model, tokenizer, input_text, lambda_val=0.01):
# Initialize conditional probability using the original model and input text
cp = compute_conditional_probability(tokenizer, model, input_text)
# Update conditional probability using the updated model and input text
cp_updated = compute_conditional_probability(tokenizer, updated_model, input_text)
# Calculate conditional probabilities for ground truth data
p_theta_ground_truth = cp(tokenizer, model, input_text)
p_theta_t_ground_truth = cp(tokenizer, model, input_text)
# Calculate conditional probabilities for synthetic data
p_theta_synthetic = cp_updated(tokenizer, updated_model, input_text)
p_theta_t_synthetic = cp_updated(tokenizer, updated_model, input_text)
# Calculate likelihood ratios
lr_ground_truth = p_theta_ground_truth / p_theta_t_ground_truth
lr_synthetic = p_theta_synthetic / p_theta_t_synthetic
# Compute the LSPIN loss
loss = lambda_val * torch.log(lr_ground_truth) - lambda_val * torch.log(lr_synthetic)
return loss
如果你有一个大的数据集,可以使用一个较小的lambda值,或者如果你有一个小的数据集,则可能需要使用一个较大的lambda值来防止过拟合。由于我们数据集大小为50k,所以可以使用0.01作为lambda的值。
4、训练(SPIN算法外循环)
这就是Pytorch训练的一个基本流程,就不详细解释了:
# Training loop
for epoch in range(num_epochs):
# Model with initial parameters
initial_model = AutoModelForCausalLM.from_pretrained("alignment-handbook/zephyr-7b-sft-full")
# Update the learning rate
scheduler.step()
# Initialize total loss for the epoch
total_loss = 0.0
# Generating Synthetic Data (Inner loop)
for index, row in ultrachat_50k_sample.iterrows():
# Rest of the code
...
# Output == prompt response dataframe
zephyr_sft_output
# Computing loss using LSPIN function
for (index1, row1), (index2, row2) in zip(ultrachat_50k_sample.iterrows(), zephyr_sft_output.iterrows()):
# Assuming 'prompt' and 'generated_output' are the relevant columns in zephyr_sft_output
prompt = row1['prompt']
generated_output = row2['generated_output']
# Compute LSPIN loss
updated_model = model # It will be replacing with updated model
loss = LSPIN_loss(initial_model, updated_model, tokenizer, prompt)
# Accumulate the loss
total_loss += loss.item()
# Backward pass
loss.backward()
# Update the parameters
optimizer.step()
# Update the value of beta
if epoch == 2:
beta = 5.0
我们运行3个epoch,它将进行训练并生成最终的Zephyr SFT LLM版本。官方实现还没有在GitHub上开源,这个版本将能够在某种程度上产生类似于人类反应的输出。我们看看他的运行流程
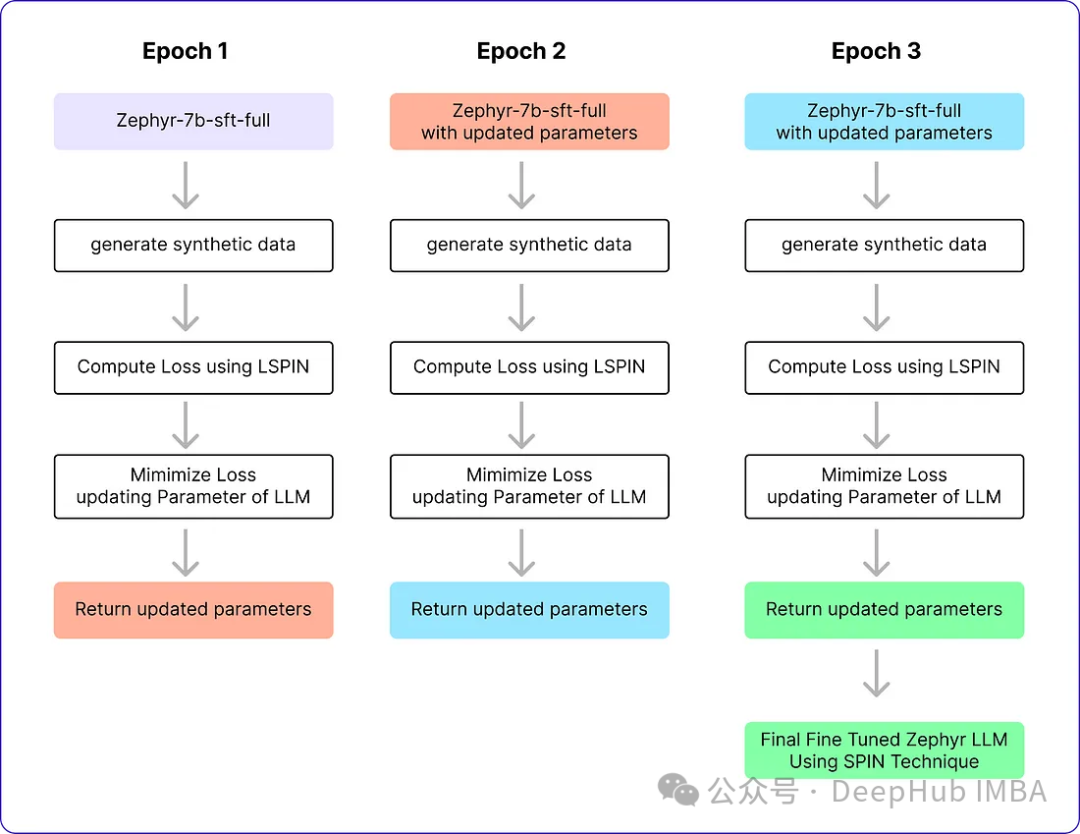
表现及结果
SPIN可以显著提高LLM在各种基准测试中的性能,甚至超过通过直接偏好优化(DPO)补充额外的GPT-4偏好数据训练的模型。
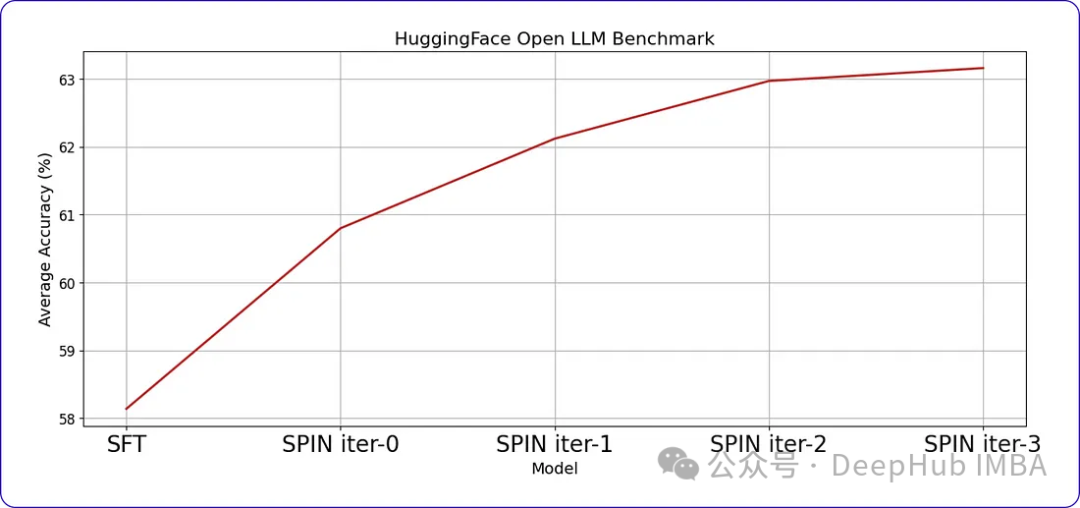
当我们继续训练时,随着时间的推移,进步会变得越来越小。这表明模型达到了一个阈值,进一步的迭代不会带来显著的收益。这是我们训练数据中样本提示符每次迭代后的响应。
论文地址:
Chen, Z., Deng, Y., Yuan, H., Ji, K., & Gu, Q. (2024, January 2). Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models.