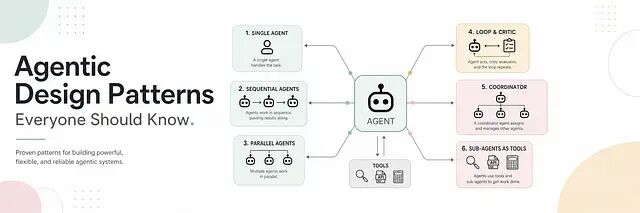
Agentic 设计模式拆解:6 种结构的优缺点与应用场景
所以这篇文章总结一些常见的设计模式,这些模式归纳了在大量已验证实现中反复出现的共性,可以视为一组结构化的骨架,用来理解智能体(Agent)、用户、模型和工具之间的核心交互。
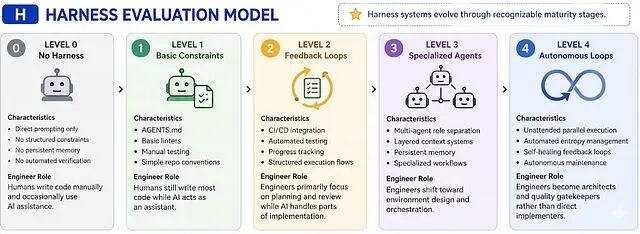
从零搭建 Harness Engineering 框架 :Rule、Skill、Sub-Agent等工程落完整路径
Harness 这个词听起来宽泛而且像一种抽象的方法论。如果它没法落到具体的目录结构、文档、脚本和工作流上,那就只是一句漂亮口号。
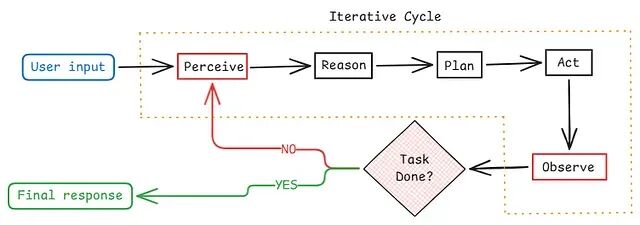
推理 → 行动 → 观察:用 LangChain + Python 实现一个智能体循环
下面这篇介绍会说明它是什么、如何工作,以及如何把它实现出来。
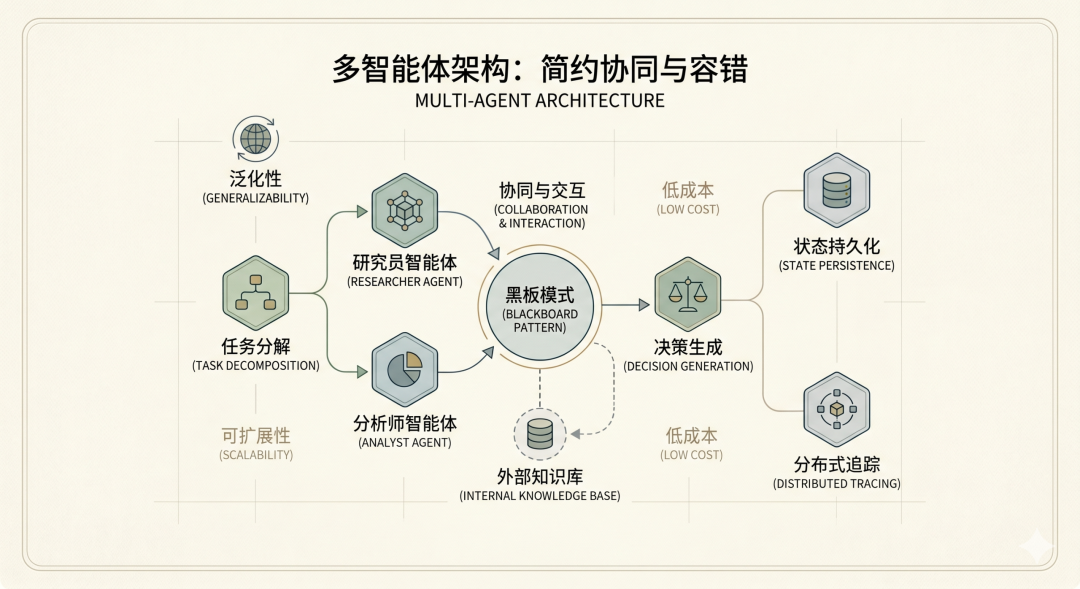
告别脆弱的单体应用,用多智能体网络构建稳定的生产力工具
本文深度解析了 AI 应用从单体大模型向多智能体(Multi-Agent)架构演进的技术趋势与工程实践。面对复杂业务,多智能体系统凭借角色分工与优雅降级展现出极强的泛化性
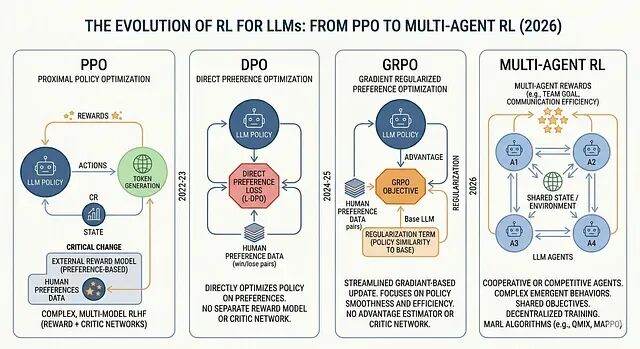
2026 年面向 LLM 的 RL方法总结:从 PPO 到 DPO 到 GRPO,再到多智能体 RL
本文是对当前格局的一次梳理。会用一点篇幅讲历史,更多篇幅留给 PPO、DPO、GRPO 和 MARL——它们是什么、各自适合什么场景、实际中会在哪里坏掉,以及今天的开源技术栈大概长什么样。
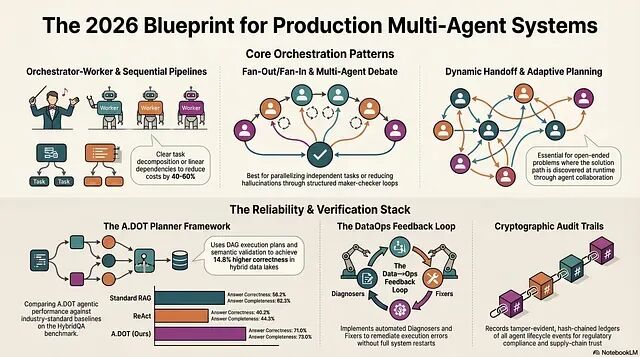
构建一个可自我改进的多 Agent RAG 系统:架构、评估,以及带人工审核的 Prompt 反馈闭环
本文描述的系统包含一个自我改进的评估闭环:自动定位表现不佳的 Prompt 维度,给出有针对性的改写方案,并通过一道由量化回归检测把关的人工审批步骤来决定是否上线。

Agent = Model + Harness:模型决定上限Harness 决定下限
Harness 不是一块单一的基础设施而是一层一层叠起来的能力栈。
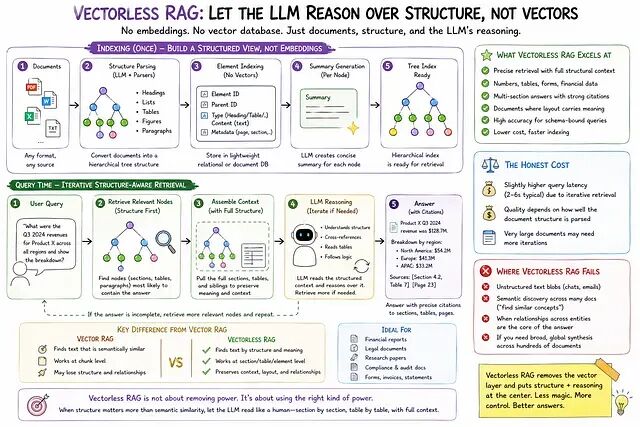
2026 RAG 选型指南:Vector、Graph、Vectorless 该怎么挑
这篇文章将介绍它们之间的差异,让你不必花三周读论文也能为自己的系统做出正确选择。
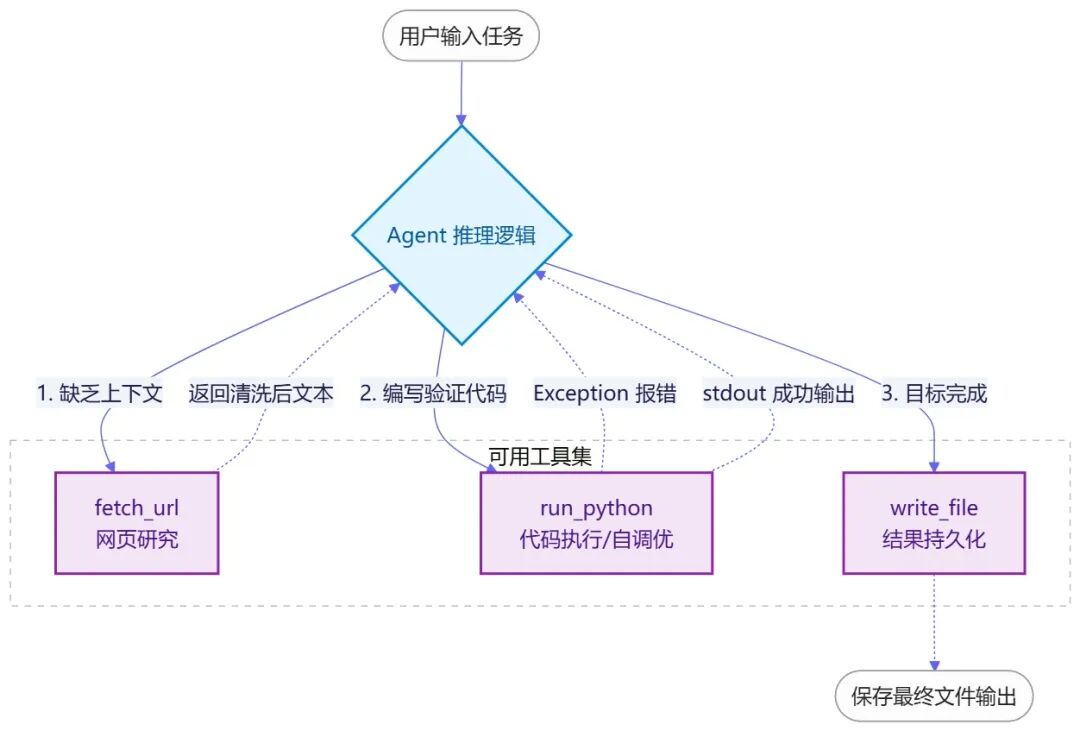
三个工具,让 agent 在一次对话里完成研究、写码、调试与保存
其实只要有三个工具就能把 agent 从聊天机器人变成能干活的东西
用 Playwright 和 LLM 实现自愈测试自动化
Playwright 是一个用于 Web 自动化和端到端测试的开源框架。
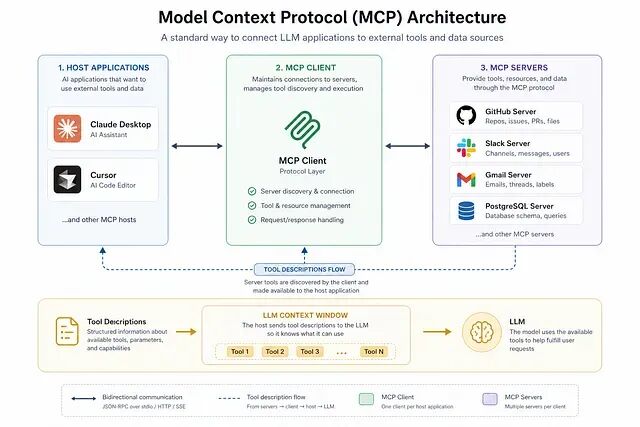
为什么 MCP 在协议层会有 prompt injection的问题:工具描述如何劫持 agent 上下文
MCP(Model Context Protocol)当初被设计成 AI agent 的通用集成层,但它的架构有一个根本缺陷:
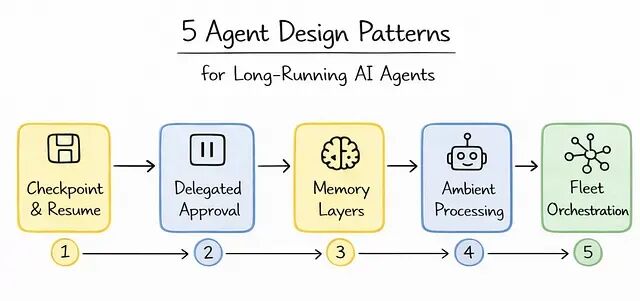
从无状态到有状态:长时运行 Agent 的 5 种架构模式
生产级 AI 不是单轮里把 agent 调得多聪明,而是看它能否在很多轮、很多天、很多次交接之间保持可靠。
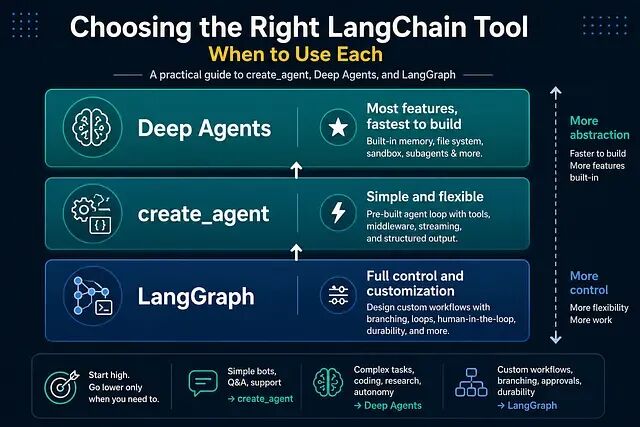
LangChain 生态里的三层抽象:LangGraph、create_agent、Deep Agents
把它们看作不同抽象层级的工具更容易理解。LangGraph 在最底层,所有控制都掌握在开发者手里;
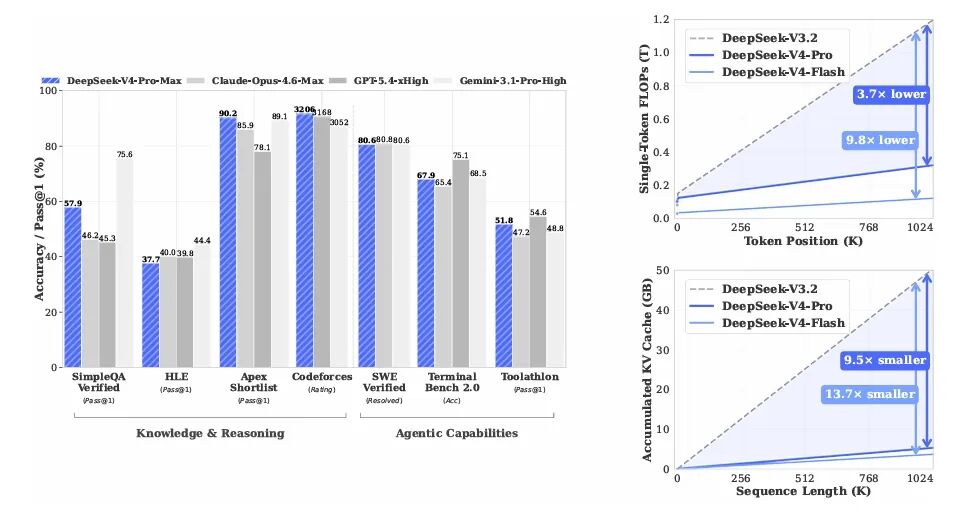
DeepSeek-V4 深度解读:百万上下文背后的工程细节
本文围绕三个问题:长上下文效率到底怎么破(架构);万亿 MoE 怎么稳定训练(基础设施 + trick);十几个领域专家如何合并成一个模型(后训练)。
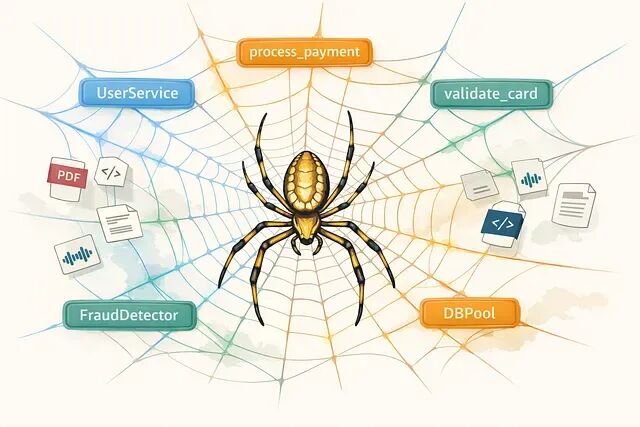
Graphify:为代码库构建知识图谱,以图遍历替代向量检索
Graphify 是一个 Python 工具,同时也是一个 Claude Code skill。它把分析工作一次性做完,把所有内容压缩成一张可查询的知识图谱,放到磁盘上。
2026年的 ReAct Agent架构解析:原生 Tool Calling 与 LangGraph 状态机
本文要做的是一个 Research Brief Agent:会上网搜索、抓取真实 URL、压缩证据,最终产出一份带真实引用的结构化简报。
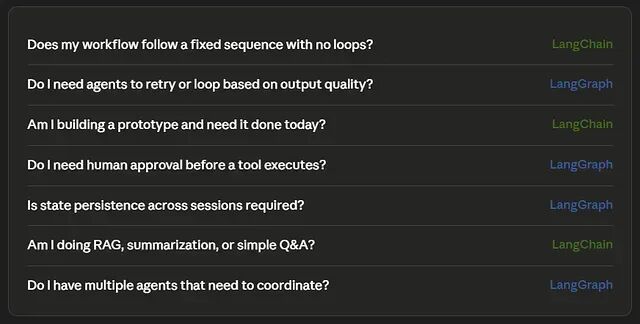
LangChain 还是 LangGraph?一个是编排一个是工具包
现在介绍LangGraph 和 LangChain 的文章。每一篇的结论都差不多:简单流程用 LangChain,复杂的用 LangGraph。

LLM 幻觉的架构级修复:推理参数、RAG、受约束解码与生成后验证
大型语言模型可以写代码、起草合同、总结论文,但它有一个致命缺陷:撒谎的时候极其自信。
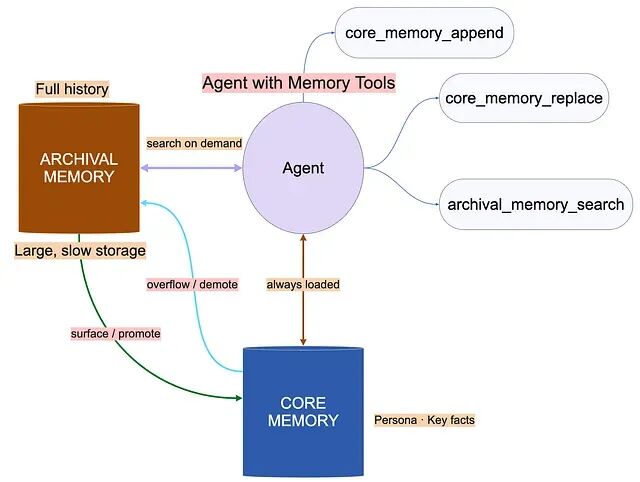
为生产级 AI Agent 构建持久化记忆:五阶段流水线与四种设计模式
不是每个 Agent 都需要这一套。如果你的 Agent 只处理单轮事务或无状态查询,这就是过度工程。记忆不是一项特性,它是 Agent 身份、连续性与信任的根基。
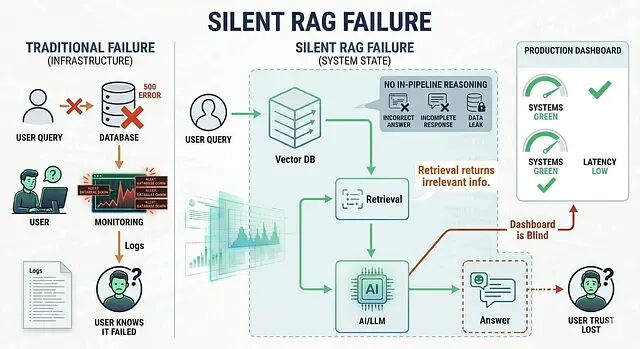
从检索到回答:RAG 流水线中三个被忽视的故障点
RAG 的搭建门槛不高,但要让一个 RAG 系统在生产环境中达到可信赖的程度,所需时间远不止于此。



